Spring Cloud为开发人员提供了快速构建分布式系统中一些常见模式的工具(例如配置管理,服务发现,断路器,智能路由,微代理,控制总线,一次性令牌,全局锁,领导选举,分布式会话,集群状态)。分布式系统的协调导致了样板模式, 使用Spring Cloud开发人员可以快速地支持实现这些模式的服务和应用程序。他们将在任何分布式环境中运行良好,包括开发人员自己的笔记本电脑,裸机数据中心,以及Cloud Foundry等托管平台。
版本:Brixton.BUILD-SNAPSHOT
特征
Spring Cloud专注于提供良好的开箱即用经验的典型用例和可扩展性机制覆盖。
-
分布式/版本化配置
-
服务注册和发现
-
路由
-
service - to - service调用
-
负载均衡
-
断路器
-
全局锁
-
Leadership选举与集群状态
-
分布式消息传递
云原生应用程序
云原生是一种应用开发风格,鼓励在持续交付和价值驱动开发领域轻松采用最佳实践。相关的学科是建立12-factor Apps,其中开发实践与交付和运营目标相一致,例如通过使用声明式编程和管理和监控。Spring Cloud以许多具体方式促进这些开发风格,起点是分布式系统中的所有组件需要或需要时轻松访问的一组功能。
许多这些功能都由Spring Boot覆盖,我们在Spring Cloud中建立。更多的由Spring Cloud提供为两个库:Spring Cloud上下文和Spring Cloud Commons。Spring Cloud上下文为Spring Cloud应用程序(引导上下文,加密,刷新范围和环境端点)的ApplicationContext提供实用程序和特殊服务。Spring Cloud Commons是一组在不同的Spring Cloud实现中使用的抽象和常用类(例如Spring Cloud Netflix vs. Spring Cloud Consul)。
如果由于“非法密钥大小”而导致异常,并且您正在使用Sun的JDK,则需要安装Java加密扩展(JCE)无限强度管理策略文件。有关详细信息,请参阅以下链接:
将文件解压缩到JDK / jre / lib / security文件夹(无论您使用的是哪个版本的JRE / JDK x64 / x86)。
|
注意
|
Spring Cloud在非限制性Apache 2.0许可证下发布。如果您想为文档的这一部分做出贡献,或者发现错误,请在github中找到项目中的源代码和问题跟踪器。 |
Spring Cloud上下文:应用程序上下文服务
Spring Boot有如何使用Spring构建应用程序的意见:例如它具有常规配置文件的常规位置,以及用于常见管理和监视任务的端点。Spring Cloud建立在此之上,并添加了一些可能系统中所有组件将使用或偶尔需要的功能。
引导应用程序上下文
一个Spring Cloud应用程序通过创建一个“引导”上下文来运行,上下文是主应用程序的父上下文。开箱即用,负责从外部源加载配置属性,还解密本地外部配置文件中的属性。这两个上下文共享一个Environment,这是任何Spring应用程序的外部属性的来源。Bootstrap属性的优先级高,因此默认情况下不能被本地配置覆盖。
引导上下文使用与主应用程序上下文定位外部配置的不同约定,因此使用bootstrap.yml而不是application.yml(或.properties),保持引导和主上下文的外部配置非常独立。例:
spring:
application:
name: foo
cloud:
config:
uri: ${SPRING_CONFIG_URI:http://localhost:8888}
如果您的应用程序需要从服务器进行特定于应用程序的配置,那么设置spring.application.name(bootstrap.yml或application.yml)是个好主意。
您可以通过设置spring.cloud.bootstrap.enabled=false(例如在系统属性中)来完全禁用引导过程。
应用程序上下文层次结构
如果您从SpringApplication或SpringApplicationBuilder构建应用程序上下文,则将Bootstrap上下文添加为该上下文的父级。这是一个Spring的功能,即子上下文从其父级继承属性源和配置文件,因此与主要构建相同的上下文相比,“主”应用程序上下文将包含其他属性源,而不使用Spring Cloud Config。额外的财产来源是:
-
“bootstrap”:如果在引导上下文中找到任何
PropertySourceLocators,则可选的CompositePropertySource显示为高优先级,它们具有非空属性。一个例子就是Spring Cloud Config服务器的属性。有关如何自定义此属性源的内容的说明,请参阅 下文。 -
“applicationConfig:[classpath:bootstrap.yml]”(和朋友,如果Spring配置文件处于活动状态)。如果您有一个
bootstrap.yml(或属性),那么这些属性用于配置引导上下文,然后在父设置时将它们添加到子上下文中。它们的优先级低于application.yml(或属性)以及作为创建Spring Boot应用程序进程的正常部分添加到子级的任何其他属性源的优先级。有关如何自定义这些属性源的内容的说明,请参阅下文。
由于属性源的排序规则,“引导”条目优先,但请注意,这些条目不包含来自bootstrap.yml的任何数据,其优先级非常低,但可用于设置默认值。
您可以通过简单地设置您创建的任何ApplicationContext的父上下文来扩展上下文层次结构,例如使用自己的界面,或使用SpringApplicationBuilder方便方法(parent(),child()和sibling())。引导环境将是您创建自己的最高级祖先的父级。层次结构中的每个上下文都将有自己的“引导”属性源(可能为空),以避免无意中将值从父级升级到其后代。层次结构中的每个上下文也可以(原则上)具有不同的spring.application.name,因此,如果存在配置服务器,则不同的远程属性源。正常Spring应用程序上下文行为规则适用于属性解析:子上下文的属性通过名称以及属性源名称覆盖父项中的属性(如果子级具有与父级名称相同的属性源,一个来自父母的孩子不包括在孩子中)。
请注意,SpringApplicationBuilder允许您在整个层次结构中共享Environment,但这不是默认的。因此,兄弟情境尤其不需要具有相同的资料或财产来源,尽管它们与父母共享共同点。
改变Bootstrap的位置Properties
可以使用spring.cloud.bootstrap.name(默认“引导”)或spring.cloud.bootstrap.location(默认为空)指定bootstrap.yml(或.properties)位置,例如系统属性。这些属性的行为类似于具有相同名称的spring.config.*变体,实际上它们用于通过在其Environment中设置这些属性来设置引导ApplicationContext。如果在正在建立的上下文中有活动的配置文件(来自spring.profiles.active或通过Environment API),则该配置文件中的属性也将被加载,就像在常规的Spring Boot应用程序中,例如来自bootstrap-development.properties的“开发”简介。
覆盖远程Properties的值
通过引导上下文添加到应用程序的属性源通常是“远程”(例如从配置服务器),并且默认情况下,不能在本地覆盖,除了在命令行上。如果要允许应用程序使用自己的系统属性或配置文件覆盖远程属性,则远程属性源必须通过设置spring.cloud.config.allowOverride=true(无法在本地设置)授予权限。一旦设置了该标志,就会有一些更精细的设置来控制远程属性与系统属性和应用程序本地配置的位置:spring.cloud.config.overrideNone=true覆盖任何本地属性源,spring.cloud.config.overrideSystemProperties=false如果只有系统属性和env var应该覆盖远程设置,而不是本地配置文件。
自定义引导配置
可以通过在org.springframework.cloud.bootstrap.BootstrapConfiguration关键字/META-INF/spring.factories下添加条目来训练自举上下文来执行任何您喜欢的操作。这是用于创建上下文的Spring @Configuration类的逗号分隔列表。您可以在此处创建要用于自动布线的主应用程序上下文的任何bean,并且还有一个@Beans类型为ApplicationContextInitializer的特殊合同。如果要控制启动顺序(默认顺序为“最后”),可以使用@Order标记类。
|
警告
|
添加自定义BootstrapConfiguration时,请注意,您添加的类不是错误的@ComponentScanned到您的“主”应用程序上下文中,可能不需要它们。对于您的@ComponentScan或@SpringBootApplication注释配置类尚未涵盖的引导配置类,请使用单独的包名称。
|
引导过程通过将初始化器注入主SpringApplication实例(即正常的Spring Boot启动顺序,无论是作为独立应用程序运行还是部署在应用程序服务器中)结束。首先,从spring.factories中找到的类创建一个引导上下文,然后在SpringApplication类型之前将ApplicationContextInitializer类型的所有@Beans添加到开始之前。
自定义引导属性源
引导过程添加的外部配置的默认属性源是Config Server,但您可以通过将PropertySourceLocator类型的bean添加到引导上下文中(通过spring.factories)添加其他源。您可以使用此方法从其他服务器或数据库中插入其他属性。
作为一个例子,请考虑以下微不足道的自定义定位器:
@Configuration
public class CustomPropertySourceLocator implements PropertySourceLocator {
@Override
public PropertySource<?> locate(Environment environment) {
return new MapPropertySource("customProperty",
Collections.<String, Object>singletonMap("property.from.sample.custom.source", "worked as intended"));
}
}传入的Environment是要创建的ApplicationContext的Environment,即为我们提供额外的属性来源的。它将已经具有正常的Spring Boot提供的资源来源,因此您可以使用这些资源来定位特定于此Environment的属性源(例如,通过在spring.application.name上键入,就像在默认值Config Server属性源定位器)。
如果你在这个类中创建一个jar,然后添加一个META-INF/spring.factories包含:
org.springframework.cloud.bootstrap.BootstrapConfiguration=sample.custom.CustomPropertySourceLocator
那么“customProperty”PropertySource将显示在其类路径中包含该jar的任何应用程序中。
环境变化
应用程序将收听EnvironmentChangeEvent,并以几种标准方式对此更改作出反应(用户可以按常规方式添加ApplicationListeners另外的ApplicationListeners)。当观察到EnvironmentChangeEvent时,它将有一个已经更改的键值列表,应用程序将使用以下内容:
-
重新绑定上下文中的所有
@ConfigurationPropertiesbean -
为
logging.level.*中的任何属性设置记录器级别
请注意,配置客户端不会通过默认轮询查看Environment中的更改,通常我们不建议检测更改的方法(尽管可以使用@Scheduled注释进行设置)。如果您有一个扩展的客户端应用程序,那么最好将EnvironmentChangeEvent广播到所有实例,而不是让它们轮询更改(例如使用Spring Cloud总线)。
EnvironmentChangeEvent涵盖了大量的刷新用例,只要您实际可以更改Environment并发布事件(这些API是公开的,并且是核心Spring的一部分)。您可以通过访问/configprops端点(普通Spring Boot Actuator功能)来验证更改是否绑定到@ConfigurationProperties bean。例如,DataSource可以在运行时更改其maxPoolSize(由Spring Boot创建的默认DataSource是一个@ConfigurationProperties bean),并且动态增加容量。重新绑定@ConfigurationProperties不涵盖另一大类用例,您需要更多的控制刷新,而您需要将整个ApplicationContext变更为原子。为了解决这些担忧,我们有@RefreshScope。
刷新范围
当配置更改时,标记为@RefreshScope的Spring @Bean将得到特殊处理。这解决了状态bean在初始化时只注入配置的问题。例如,如果通过Environment更改数据库URL时DataSource有开放连接,我们可能希望这些连接的持有者能够完成他们正在做的工作。然后下一次有人从游泳池借用一个连接,他得到一个新的URL。
刷新范围bean是在使用时初始化的懒惰代理(即当调用一个方法时),并且作用域作为初始值的缓存。要强制bean重新初始化下一个方法调用,您只需要使其缓存条目无效。
RefreshScope是上下文中的一个bean,它有一个公共方法refreshAll()来清除目标缓存中的范围内的所有bean。还有一个refresh(String)方法通过名称刷新单个bean。此功能在/refresh端点(通过HTTP或JMX)中公开。
|
注意
|
@RefreshScope工程(技术)上的@Configuration类,但它可能会导致令人惊讶的行为:例如,它并不
意味着所有的@Beans在类中定义本身@RefreshScope。具体来说,任何取决于这些bean的东西都不能依赖它们在刷新启动时被更新,除非它本身在@RefreshScope(在其中将重新刷新并重新注入其依赖关系),那么它们将从刷新的@Configuration重新初始化)。
|
加密和解密
Spring Cloud具有用于在本地解密属性值的Environment预处理器。它遵循与Config Server相同的规则,并通过encrypt.*具有相同的外部配置。因此,您可以使用{cipher}*格式的加密值,只要有一个有效的密钥,那么在主应用程序上下文获取Environment之前,它们将被解密。要在应用程序中使用加密功能,您需要在您的类路径中包含Spring Security RSA(Maven协调“org.springframework.security:spring-security-rsa”),并且还需要全面强大的JCE扩展你的JVM
如果由于“非法密钥大小”而导致异常,并且您正在使用Sun的JDK,则需要安装Java加密扩展(JCE)无限强度管理策略文件。有关详细信息,请参阅以下链接:
将文件解压缩到JDK / jre / lib / security文件夹(无论您使用的是哪个版本的JRE / JDK x64 / x86)。
端点
对于Spring Boot Actuator应用程序,还有一些额外的管理端点:
-
POST到
/env以更新Environment并重新绑定@ConfigurationProperties和日志级别 -
/refresh重新加载引导带上下文并刷新@RefreshScopebean -
/restart关闭ApplicationContext并重新启动(默认情况下禁用) -
/pause和/resume调用Lifecycle方法(stop()和start())上的ApplicationContext)
Spring Cloud Commons:普通抽象
诸如服务发现,负载平衡和断路器之类的模式适用于所有Spring Cloud客户端可以独立于实现(例如,通过Eureka或Consul发现)可以使用的普通抽象层。
@EnableDiscoveryClient
Commons提供@EnableDiscoveryClient注释。这通过META-INF/spring.factories查找DiscoveryClient接口的实现。Discovery Client的实现将在org.springframework.cloud.client.discovery.EnableDiscoveryClient键下的spring.factories中添加一个配置类。DiscoveryClient实现的例子是Spring Cloud Netflix Eureka,Spring Cloud Consul发现和Spring Cloud Zookeeper发现。
默认情况下,DiscoveryClient的实现将使用远程发现服务器自动注册本地Spring Boot服务器。可以通过在@EnableDiscoveryClient中设置autoRegister=false来禁用此功能。
ServiceRegistry
Commons现在提供了一个ServiceRegistry接口,它提供了诸如register(Registration)和deregister(Registration)之类的方法,允许您提供自定义的注册服务。Registration是一个标记界面。
服务注册执行器端点
Commons提供/service-registry致动器端点。此端点依赖于Spring应用程序上下文中的Registration bean。通过GET调用/service-registry/instance-status将返回Registration的状态。具有String主体的同一端点的POST将将当前Registration的状态更改为新值。请参阅您正在使用的ServiceRegistry实现的文档,以获取更新状态的允许值以及为状态获取的值。
Spring RestTemplate作为负载均衡器客户端
RestTemplate可以自动配置为使用功能区。要创建负载平衡RestTemplate创建RestTemplate @Bean并使用@LoadBalanced限定符。
|
警告
|
通过自动配置不再创建RestTemplate bean。它必须由单个应用程序创建。
|
@Configuration
public class MyConfiguration {
@LoadBalanced
@Bean
RestTemplate restTemplate() {
return new RestTemplate();
}
}
public class MyClass {
@Autowired
private RestTemplate restTemplate;
public String doOtherStuff() {
String results = restTemplate.getForObject("http://stores/stores", String.class);
return results;
}
}URI需要使用虚拟主机名(即服务名称,而不是主机名)。Ribbon客户端用于创建完整的物理地址。有关
如何设置RestTemplate的详细信息,请参阅
RibbonAutoConfiguration。
重试失败的请求
负载平衡RestTemplate可以配置为重试失败的请求。默认情况下,该逻辑被禁用,您可以通过设置spring.cloud.loadbalancer.retry.enabled=true启用该逻辑。负载平衡RestTemplate将符合与重试失败请求相关的某些Ribbon配置值。您可以使用的属性是client.ribbon.MaxAutoRetries,client.ribbon.MaxAutoRetriesNextServer和client.ribbon.OkToRetryOnAllOperations。请参阅Ribbon文档
,了解属性的具体内容。
|
注意
|
上述示例中的client应替换为您的Ribbon客户端名称。
|
多个RestTemplate对象
如果你想要一个没有负载平衡的RestTemplate,创建一个RestTemplate bean并注入它。创建@Bean时访问负载平衡RestTemplate use
the `@LoadBalanced限定词。
|
重要
|
请注意下面示例中明文RestTemplate声明的@Primary注释,以消除不合格的@Autowired注入。
|
@Configuration
public class MyConfiguration {
@LoadBalanced
@Bean
RestTemplate loadBalanced() {
return new RestTemplate();
}
@Primary
@Bean
RestTemplate restTemplate() {
return new RestTemplate();
}
}
public class MyClass {
@Autowired
private RestTemplate restTemplate;
@Autowired
@LoadBalanced
private RestTemplate loadBalanced;
public String doOtherStuff() {
return loadBalanced.getForObject("http://stores/stores", String.class);
}
public String doStuff() {
return restTemplate.getForObject("http://example.com", String.class);
}
}|
提示
|
如果您发现错误java.lang.IllegalArgumentException: Can not set org.springframework.web.client.RestTemplate field com.my.app.Foo.restTemplate to com.sun.proxy.$Proxy89,请尝试注销RestOperations或设置spring.aop.proxyTargetClass=true。
|
忽略网络接口
有时,忽略某些命名网络接口是有用的,因此可以将其从服务发现注册中排除(例如,在Docker容器中运行)。可以设置正则表达式的列表,这将导致所需的网络接口被忽略。以下配置将忽略“docker0”接口和以“veth”开头的所有接口。
spring:
cloud:
inetutils:
ignoredInterfaces:
- docker0
- veth.*
您还可以强制使用正则表达式列表中指定的网络地址:
spring:
cloud:
inetutils:
preferredNetworks:
- 192.168
- 10.0
您也可以强制仅使用站点本地地址。有关更多详细信息,请参阅Inet4Address.html.isSiteLocalAddress())是什么是站点本地地址。
spring:
cloud:
inetutils:
useOnlySiteLocalInterfaces: true
Spring Cloud Config
Environment和PropertySource抽象相同,因此它们与Spring应用程序非常契合,但可以与任何以任何语言运行的应用程序一起使用。随着应用程序通过从开发人员到测试和生产的部署流程,您可以管理这些环境之间的配置,并确定应用程序具有迁移时需要运行的一切。服务器存储后端的默认实现使用git,因此它轻松支持标签版本的配置环境,以及可以访问用于管理内容的各种工具。可以轻松添加替代实现,并使用Spring配置将其插入。
快速开始
启动服务器:
$ cd spring-cloud-config-server $ ../mvnw spring-boot:run
该服务器是一个Spring Boot应用程序,所以您可以从IDE(而不是主类(ConfigServerApplication))运行它。然后尝试一个客户端:
$ curl localhost:8888/foo/development
{"name":"development","label":"master","propertySources":[
{"name":"https://github.com/scratches/config-repo/foo-development.properties","source":{"bar":"spam"}},
{"name":"https://github.com/scratches/config-repo/foo.properties","source":{"foo":"bar"}}
]}
定位资源的默认策略是克隆一个git仓库(在spring.cloud.config.server.git.uri),并使用它来初始化一个迷你SpringApplication。迷你应用程序的Environment用于枚举属性源并通过JSON端点发布。
HTTP服务具有以下格式的资源:
/{application}/{profile}[/{label}]
/{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties
其中“应用程序”作为SpringApplication中的spring.config.name注入(即常规Spring Boot应用程序中通常为“应用程序”),“配置文件”是活动配置文件(或逗号分隔列表的属性),“label”是可选的git标签(默认为“master”)。
Spring Cloud Config服务器从git存储库中提取远程客户端的配置(必须提供):
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo客户端使用
要在应用程序中使用这些功能,只需将其构建为依赖于spring-cloud-config-client的Spring引导应用程序(例如,查看配置客户端或示例应用程序的测试用例)。添加依赖关系的最方便的方法是通过Spring Boot启动器org.springframework.cloud:spring-cloud-starter-config。还有一个Maven用户的父pom和BOM(spring-cloud-starter-parent)以及Gradle和Spring CLI用户的Spring IO版本管理属性文件。示例Maven配置:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.5.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<!-- repositories also needed for snapshots and milestones -->那么您可以创建一个标准的Spring Boot应用程序,就像这个简单的HTTP服务器:
@SpringBootApplication
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello World!";
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
当它运行它将从端口8888上的默认本地配置服务器接收外部配置,如果它正在运行。要修改启动行为,您可以使用bootstrap.properties更改配置服务器的位置(如application.properties,但用于应用程序上下文的引导阶段),例如
spring.cloud.config.uri: http://myconfigserver.com
引导属性将在/env端点中显示为高优先级属性源,例如
$ curl localhost:8080/env
{
"profiles":[],
"configService:https://github.com/spring-cloud-samples/config-repo/bar.properties":{"foo":"bar"},
"servletContextInitParams":{},
"systemProperties":{...},
...
}
(名为“configService:<远程存储库的URL> / <文件名>”的属性源包含值为“bar”的属性“foo”,是最高优先级)。
|
注意
|
属性源名称中的URL是git存储库,而不是配置服务器URL。 |
Spring Cloud Config服务器
服务器为外部配置(名称值对或等效的YAML内容)提供了基于资源的HTTP。服务器可以使用@EnableConfigServer注释轻松嵌入到Spring Boot应用程序中。所以这个应用程序是一个配置服务器:
@SpringBootApplication
@EnableConfigServer
public class ConfigServer {
public static void main(String[] args) {
SpringApplication.run(ConfigServer.class, args);
}
}像所有默认端口8080上运行的所有Spring Boot应用程序一样,但您可以通过各种方式将其切换到常规端口8888。最简单的(也设置默认配置库)是通过使用spring.config.name=configserver启动(在Config Server jar中有一个configserver.yml)。另一个是使用你自己的application.properties,例如
server.port: 8888
spring.cloud.config.server.git.uri: file://${user.home}/config-repo其中${user.home}/config-repo是包含YAML和属性文件的git仓库。
|
注意
|
在Windows中,如果文件URL为绝对驱动器前缀,例如file:///${user.home}/config-repo,则需要额外的“/”。
|
|
提示
|
以下是上面示例中创建git仓库的方法: $ cd $HOME $ mkdir config-repo $ cd config-repo $ git init . $ echo info.foo: bar > application.properties $ git add -A . $ git commit -m "Add application.properties" |
|
警告
|
使用本地文件系统进行git存储库仅用于测试。使用服务器在生产环境中托管配置库。 |
|
警告
|
如果您只保留文本文件,则配置库的初始克隆将会快速有效。如果您开始存储二进制文件,尤其是较大的文件,则可能会遇到服务器中第一个配置请求和/或内存不足错误的延迟。 |
环境库
您要在哪里存储配置服务器的配置数据?管理此行为的策略是EnvironmentRepository,服务于Environment对象。此Environment是Spring Environment(包括propertySources作为主要功能)的域的浅层副本。Environment资源由三个变量参数化:
-
{application}映射到客户端的“spring.application.name”; -
{profile}映射到客户端上的“spring.profiles.active”(逗号分隔列表); 和 -
{label}这是一个服务器端功能,标记“版本”的配置文件集。
存储库实现通常表现得像一个Spring Boot应用程序从“spring.config.name”等于{application}参数加载配置文件,“spring.profiles.active”等于{profiles}参数。配置文件的优先级规则也与常规启动应用程序相同:活动配置文件优先于默认配置,如果有多个配置文件,则最后一个获胜(例如向Map添加条目)。
示例:客户端应用程序具有此引导配置:
spring:
application:
name: foo
profiles:
active: dev,mysql(通常使用Spring Boot应用程序,这些属性也可以设置为环境变量或命令行参数)。
如果存储库是基于文件的,则服务器将从application.yml创建Environment(在所有客户端之间共享),foo.yml(以foo.yml优先))。如果YAML文件中有文档指向Spring配置文件,那么应用的优先级更高(按照列出的配置文件的顺序),并且如果有特定于配置文件的YAML(或属性)文件,那么这些文件也应用于优先级高于默认值。较高的优先级转换为Environment之前列出的PropertySource。(这些规则与独立的Spring Boot应用程序相同。)
Git后端
EnvironmentRepository的默认实现使用Git后端,这对于管理升级和物理环境以及审核更改非常方便。要更改存储库的位置,可以在Config Server中设置“spring.cloud.config.server.git.uri”配置属性(例如application.yml)。如果您使用file:前缀进行设置,则应从本地存储库中运行,以便在没有服务器的情况下快速轻松地启动,但在这种情况下,服务器将直接在本地存储库中进行操作,而不会克隆它(不会如果它不是裸机,因为配置服务器永远不会更改“远程”资源库)。要扩展Config Server并使其高度可用,您需要将服务器的所有实例指向同一个存储库,因此只有共享文件系统才能正常工作。即使在这种情况下,最好使用共享文件系统存储库的ssh:协议,以便服务器可以将其克隆并使用本地工作副本作为缓存。
该存储库实现将HTTP资源的{label}参数映射到git标签(提交ID,分支名称或标签)。如果git分支或标签名称包含斜杠(“/”),则应使用特殊字符串“(_)”指定HTTP URL中的标签,以避免与其他URL路径模糊。如果您使用像curl这样的命令行客户端(例如使用引号将其从shell中转出来),请小心URL中的方括号。
Git URI中的占位符
Spring Cloud Config服务器支持具有{application}和{profile}(以及{label}(如果需要)的占位符的git仓库URL,但请记住,标签应用为git标签)。因此,您可以使用(例如)轻松支持“每个应用程序的一个repo”策略:
spring:
cloud:
config:
server:
git:
uri: https://github.com/myorg/{application}或使用类似模式“{一个回购每个配置文件”策略,但是使用{profile}。
模式匹配和多个存储库
还可以通过应用程序和配置文件名称的模式匹配来支持更复杂的需求。模式格式是带有通配符的{application}/{profile}名称的逗号分隔列表(其中以通配符开头的模式可能需要引用)。例:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
repos:
simple: https://github.com/simple/config-repo
special:
pattern: special*/dev*,*special*/dev*
uri: https://github.com/special/config-repo
local:
pattern: local*
uri: file:/home/configsvc/config-repo如果{application}/{profile}不匹配任何模式,它将使用在“spring.cloud.config.server.git.uri”下定义的默认uri。在上面的例子中,对于“简单”存储库,模式是simple/*(即它只匹配一个在所有配置文件中名为“简单”的应用程序)。“本地”存储库将所有配置文件中以“local”开头的所有应用程序名称进行匹配(将/*后缀自动添加到任何没有配置文件匹配器的模式)。
|
注意
|
在上述“简单”示例中使用的“单行”快捷方式只能在唯一要设置的属性为URI的情况下使用。如果您需要设置其他任何内容(凭据,模式等),则需要使用完整的表单。 |
repo中的pattern属性实际上是一个数组,因此您可以使用属性文件中的YAML数组(或[0],[1]等后缀)绑定到多个模式。如果要运行具有多个配置文件的应用程序,则可能需要执行此操作。例:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
repos:
development:
pattern:
- */development
- */staging
uri: https://github.com/development/config-repo
staging:
pattern:
- */qa
- */production
uri: https://github.com/staging/config-repo|
注意
|
Spring Cloud将猜测包含不在*中的配置文件的模式意味着您实际上要匹配从此模式开始的配置文件列表(所以*/staging是["*/staging", "*/staging,*"])。这是常见的,您需要在本地的“开发”配置文件中运行应用程序,但也可以远程运行“云”配置文件。
|
每个存储库还可以选择将配置文件存储在子目录中,搜索这些目录的模式可以指定为searchPaths。例如在顶层:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
searchPaths: foo,bar*在此示例中,服务器搜索顶级和“foo /”子目录以及名称以“bar”开头的任何子目录中的配置文件。
默认情况下,首次请求配置时,服务器克隆远程存储库。服务器可以配置为在启动时克隆存储库。例如在顶层:
spring:
cloud:
config:
server:
git:
uri: https://git/common/config-repo.git
repos:
team-a:
pattern: team-a-*
cloneOnStart: true
uri: http://git/team-a/config-repo.git
team-b:
pattern: team-b-*
cloneOnStart: false
uri: http://git/team-b/config-repo.git
team-c:
pattern: team-c-*
uri: http://git/team-a/config-repo.git在此示例中,服务器在启动之前克隆了team-a的config-repo,然后它接受任何请求。所有其他存储库将不被克隆,直到请求从存储库配置。
要在远程存储库上使用HTTP基本身份验证,请分别添加“username”和“password”属性(不在URL中),例如
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
username: trolley
password: strongpassword如果您不使用HTTPS和用户凭据,当您将密钥存储在默认目录(~/.ssh)中并且uri指向SSH位置时,SSH也应该开箱即用,例如“ git@github.com:配置/云配置”。使用JGit访问存储库,因此您发现的任何文档都应适用。HTTPS代理设置可以~/.git/config设置,也可以通过系统属性(-Dhttps.proxyHost和-Dhttps.proxyPort)与任何其他JVM进程相同。
|
提示
|
如果你不知道~/.git目录是我们git config
--global操纵设置(例如git config --global
http.sslVerify false)的位置。
|
Git搜索路径中的占位符
Spring Cloud Config服务器还支持具有{application}和{profile}(以及{label}(如果需要))占位符的搜索路径。例:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
searchPaths: '{application}'在资源库中搜索与目录(以及顶级)相同名称的文件。通配符在具有占位符的搜索路径中也是有效的(搜索中包含任何匹配的目录)。
版本控制后端文件系统使用
|
警告
|
使用基于VCS的后端(git,svn)文件被检出或克隆到本地文件系统。默认情况下,它们放在系统临时目录中,前缀为config-repo-。在linux上,例如可以是/tmp/config-repo-<randomid>。一些操作系统会定期清除临时目录。这可能会导致意外的行为,例如缺少属性。要避免此问题,请通过将spring.cloud.config.server.git.basedir或spring.cloud.config.server.svn.basedir设置为不驻留在系统临时结构中的目录来更改Config Server使用的目录。
|
文件系统后端
配置服务器中还有一个不使用Git的“本机”配置文件,只是从本地类路径或文件系统加载配置文件(您想要指向的任何静态URL“spring.cloud.config.server .native.searchLocations“)。要使用本机配置文件,只需使用“spring.profiles.active = native”启动Config Server。
|
注意
|
记住使用文件资源的file:前缀(缺省没有前缀通常是classpath)。与任何Spring Boot配置一样,您可以嵌入${}风格的环境占位符,但请记住,Windows中的绝对路径需要额外的“/”,例如file:///${user.home}/config-repo
|
|
警告
|
searchLocations的默认值与本地Spring Boot应用程序(所以[classpath:/, classpath:/config,
file:./, file:./config])相同。这不会将application.properties从服务器暴露给所有客户端,因为在发送到客户端之前,服务器中存在的任何属性源都将被删除。
|
|
提示
|
文件系统后端对于快速入门和测试是非常好的。要在生产中使用它,您需要确保文件系统是可靠的,并在配置服务器的所有实例中共享。 |
搜索位置可以包含{application},{profile}和{label}的占位符。以这种方式,您可以隔离路径中的目录,并选择一个有用的策略(例如每个应用程序的子目录或每个配置文件的子目录)。
如果您不在搜索位置使用占位符,则该存储库还将HTTP资源的{label}参数附加到搜索路径上的后缀,因此属性文件将从每个搜索位置加载并具有相同名称的子目录作为标签(标记的属性在Spring环境中优先)。因此,没有占位符的默认行为与添加以/{label}/. For example `file:/tmp/config结尾的搜索位置的添加与file:/tmp/config,file:/tmp/config/{label}相同
与所有应用共享配置
使用基于文件(即git,svn和native)的存储库,所有客户端应用程序({application.properties,application.yml,application-*.properties等))共享文件名为application*的资源。您可以使用这些文件名的资源来配置全局默认值,并根据需要将其覆盖应用程序特定的文件。
#_property_overrides [属性覆盖]功能也可用于设置全局默认值,并且允许占位符应用程序在本地覆盖它们。
|
提示
|
使用“本机”配置文件(本地文件系统后端),建议您使用不属于服务器自身配置的显式搜索位置。否则默认搜索位置中的application*资源将被删除,因为它们是服务器的一部分。
|
属性覆盖
配置服务器具有“覆盖”功能,允许操作员为所有应用程序提供配置属性,这些应用程序不会被应用程序使用普通的Spring Boot钩子意外更改。要声明覆盖,只需将名称/值对的地图添加到spring.cloud.config.server.overrides。例如
spring:
cloud:
config:
server:
overrides:
foo: bar将导致配置客户端的所有应用程序独立于自己的配置读取foo=bar。(当然,应用程序可以使用任何它喜欢的配置服务器中的数据,所以覆盖是不可执行的,但如果他们是Spring Cloud Config客户端,它们确实提供有用的默认行为。)
|
提示
|
通过使用反斜杠(“\”)来转义“$”或“{”,例如\${app.foo:bar}解析,可以将正常的Spring环境占位符与“$ {}”进行转义(并在客户端上解析)到“bar”,除非应用程序提供自己的“app.foo”。请注意,在YAML中,您不需要转义反斜杠本身,而是在您执行的属性文件中配置服务器上的覆盖。
|
您可以将客户端中所有覆盖的优先级更改为默认值,允许应用程序通过在远程存储库中设置标志spring.cloud.config.overrideNone=true(默认值为false),在环境变量或系统属性中提供自己的值。
健康指标
配置服务器附带一个运行状况指示器,用于检查配置的EnvironmentRepository是否正常工作。默认情况下,请求app的应用程序default,default配置文件和EnvironmentRepository实现提供的默认标签。
您可以配置运行状况指示器以检查更多应用程序以及自定义配置文件和自定义标签,例如
spring:
cloud:
config:
server:
health:
repositories:
myservice:
label: mylabel
myservice-dev:
name: myservice
profiles: development您可以通过设置spring.cloud.config.server.health.enabled=false来禁用运行状况指示器。
安全
您可以以任何对您有意义的方式(从物理网络安全性到OAuth2承载令牌)来保护您的Config Server,并且Spring Security和Spring Boot可以轻松做任何事情。
要使用默认的Spring Boot配置的HTTP Basic安全性,只需在类路径中包含Spring Security(例如通过spring-boot-starter-security)。默认值为“user”和随机生成的密码,这在实践中不会非常有用,因此我们建议您配置密码(通过security.user.password)进行加密(请参阅下面的说明)怎么做)。
加密和解密
|
重要
|
先决条件:要使用加密和解密功能,您需要在JVM中安装全面的JCE(默认情况下不存在)。您可以从Oracle下载“Java加密扩展(JCE)无限强度管理策略文件”,并按照安装说明(实际上将JRE lib / security目录中的2个策略文件替换为您下载的文件)。 |
如果远程属性源包含加密内容(以{cipher}开头的值),则在通过HTTP发送给客户端之前,它们将被解密。这种设置的主要优点是,当它们“静止”时,属性值不必是纯文本(例如在git仓库中)。如果值无法解密,则从属性源中删除该值,并添加具有相同键的附加属性,但以“无效”作为前缀。和“不适用”的值(通常为“<n / a>”)。这主要是为了防止密码被用作密码并意外泄漏。
如果您正在为配置客户端应用程序设置远程配置存储库,可能会包含这样的application.yml,例如:
spring:
datasource:
username: dbuser
password: '{cipher}FKSAJDFGYOS8F7GLHAKERGFHLSAJ'.properties文件中的加密值不能用引号括起来,否则不会解密该值:
spring.datasource.username: dbuser
spring.datasource.password: {cipher}FKSAJDFGYOS8F7GLHAKERGFHLSAJ
您可以安全地将此纯文本推送到共享git存储库,并且保密密码。
服务器还暴露了/encrypt和/decrypt端点(假设这些端点将被保护并且只能由授权代理访问)。如果您正在编辑远程配置文件,可以使用Config Server通过POST到/encrypt端点来加密值,例如
$ curl localhost:8888/encrypt -d mysecret 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda
逆向操作也可通过/decrypt获得(如果服务器配置了对称密钥或全密钥对):
$ curl localhost:8888/decrypt -d 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda mysecret
|
提示
|
如果您使用curl进行测试,则使用--data-urlencode(而不是-d)或设置显式Content-Type:
text/plain,以确保在有特殊字符时正确地对数据进行编码('+'特别是棘手)。
|
在加入值之前,先添加{cipher}前缀,然后再将其放入YAML或属性文件中,然后再将其推送到远程,可能不安全的存储区。
/encrypt和/decrypt端点也接受/*/{name}/{profiles}形式的路径,当客户端调用到主环境资源时,可以用于每个应用程序(名称)和配置文件控制密码。
|
注意
|
为了以这种细微的方式控制密码,您还必须提供一种TextEncryptorLocator类型的@Bean,每个名称和配置文件都会创建一个不同的加密器。默认提供的不会这样做(所有加密使用相同的密钥)。
|
spring命令行客户端(安装了Spring Cloud CLI扩展)也可以用于加密和解密,例如
$ spring encrypt mysecret --key foo 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda $ spring decrypt --key foo 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda mysecret
要在文件中使用密钥(例如用于加密的RSA公钥),使用“@”键入键值,并提供文件路径,例如
$ spring encrypt mysecret --key @${HOME}/.ssh/id_rsa.pub
AQAjPgt3eFZQXwt8tsHAVv/QHiY5sI2dRcR+...
关键参数是强制性的(尽管有一个--前缀)。
密钥管理
Config Server可以使用对称(共享)密钥或非对称密钥(RSA密钥对)。非对称选择在安全性方面是优越的,但是使用对称密钥往往更方便,因为它只是配置的一个属性值。
要配置对称密钥,您只需要将encrypt.key设置为一个秘密字符串(或使用环境变量ENCRYPT_KEY将其从纯文本配置文件中删除)。
要配置非对称密钥,您可以将密钥设置为PEM编码的文本值(以encrypt.key)或密钥库(例如由JDK附带的keytool实用程序创建)。密钥库属性为encrypt.keyStore.*,*等于
-
location(aResource位置), -
password(解锁密钥库)和 -
alias(以识别商店中使用的密钥)。
使用公钥进行加密,需要私钥进行解密。因此,原则上您只能在服务器中配置公钥,如果您只想进行加密(并准备使用私钥本地解密值)。实际上,您可能不想这样做,因为它围绕所有客户端传播密钥管理流程,而不是将其集中在服务器中。另一方面,如果您的配置服务器真的相对不安全,并且只有少数客户端需要加密的属性,这是一个有用的选项。
创建用于测试的密钥库
要创建一个密钥库进行测试,您可以执行以下操作:
$ keytool -genkeypair -alias mytestkey -keyalg RSA \ -dname "CN=Web Server,OU=Unit,O=Organization,L=City,S=State,C=US" \ -keypass changeme -keystore server.jks -storepass letmein
将server.jks文件放在类路径(例如)中,然后在您的application.yml中配置服务器:
encrypt:
keyStore:
location: classpath:/server.jks
password: letmein
alias: mytestkey
secret: changeme使用多个键和键旋转
除了加密属性值中的{cipher}前缀之外,配置服务器在(Base64编码)密文开始之前查找{name:value}前缀(零或多个)。密钥被传递给一个TextEncryptorLocator,它可以做任何逻辑,需要找到一个TextEncryptor的密码。如果配置了密钥库(encrypt.keystore.location),默认定位器将使用“key”前缀提供的别名,即使用如下密码查找存储中的密钥:
foo:
bar: `{cipher}{key:testkey}...`定位器将寻找一个名为“testkey”的键。也可以通过前缀中的{secret:…}值提供秘密,但如果不是默认值,则使用密钥库密码(这是您构建密钥存储并且不指定密码时获得的密码)。如果你这样做
提供一个秘密建议你也加密使用自定义SecretLocator的秘密。
如果密钥只用于加密几个字节的配置数据(即它们没有在其他地方使用),则密码转换几乎不是必需的,但是如果存在安全漏洞,有时您可能需要更改密钥实例。在这种情况下,所有客户端都需要更改其源配置文件(例如git),并在所有密码中使用新的{key:…}前缀,当然事先检查配置服务器密钥库中的密钥别名可用。
|
提示
|
如果要让配置服务器处理所有加密以及解密,也可以将{name:value}前缀添加到发布到/encrypt端点的明文。
|
服务加密Properties
有时您希望客户端在本地解密配置,而不是在服务器中进行配置。在这种情况下,您仍然可以拥有/加密和/解密端点(如果您提供encrypt.*配置来定位密钥),但是您需要使用spring.cloud.config.server.encrypt.enabled=false明确地关闭传出属性的解密。如果您不关心端点,那么如果您既不配置密钥也不配置使能的标志,则应该起作用。
服务替代格式
来自环境端点的默认JSON格式非常适合Spring应用程序的使用,因为它直接映射到Environment抽象。如果您喜欢,可以通过向资源路径(“.yml”,“.yaml”或“.properties”)添加后缀来使用与YAML或Java属性相同的数据。这对于不关心JSON端点的结构的应用程序或其提供的额外的元数据的应用程序可能会有用,例如,不使用Spring的应用程序可能会受益于此方法的简单性。
YAML和属性表示有一个附加标志(作为布尔查询参数resolvePlaceholders提供)),以标示Spring ${…}形式的源文档中的占位符信号,应在输出中解析可能在渲染之前。对于不了解Spring占位符约定的消费者来说,这是一个有用的功能。
|
注意
|
使用YAML或属性格式存在局限性,主要是与元数据的丢失有关。JSON被构造为属性源的有序列表,例如,名称与源相关联。即使源的起源具有多个源,并且原始源文件的名称丢失,YAML和属性表也合并成一个映射。YAML表示不一定是后台存储库中YAML源的忠实表示:它是由平面属性源的列表构建的,并且必须对键的形式进行假设。 |
服务纯文本
您的应用程序可能需要通用的纯文本配置文件,而不是使用Environment抽象(或YAML或属性格式的其他替代表示形式)。配置服务器通过/{name}/{profile}/{label}/{path}附加的端点提供这些服务,其中“name”,“profile”和“label”的含义与常规环境端点相同,但“path”是文件名(例如log.xml )。此端点的源文件位于与环境端点相同的方式:与属性或YAML文件相同的搜索路径,而不是聚合所有匹配的资源,只返回匹配的第一个。
在找到资源后,使用正确格式(${…})的占位符使用有效的Environment解析应用程序名称,配置文件和标签。以这种方式,资源端点与环境端点紧密集成。例如,如果您有一个GIT(或SVN)资源库的布局:
application.yml nginx.conf
其中nginx.conf如下所示:
server {
listen 80;
server_name ${nginx.server.name};
}
和application.yml这样:
nginx:
server:
name: example.com
---
spring:
profiles: development
nginx:
server:
name: develop.com那么/foo/default/master/nginx.conf资源如下所示:
server {
listen 80;
server_name example.com;
}
和/foo/development/master/nginx.conf这样:
server {
listen 80;
server_name develop.com;
}
|
注意
|
就像环境配置的源文件一样,“配置文件”用于解析文件名,因此,如果您想要一个特定于配置文件的文件,则/*/development/*/logback.xml将由一个名为logback-development.xml的文件解析(优先于logback.xml)。
|
嵌入配置服务器
配置服务器最好作为独立应用程序运行,但如果需要,可以将其嵌入到另一个应用程序中。只需使用@EnableConfigServer注释。在这种情况下可以使用的可选属性是spring.cloud.config.server.bootstrap,它是一个标志,表示服务器应该从自己的远程存储库配置自己。该标志默认关闭,因为它可能会延迟启动,但是当嵌入在另一个应用程序中时,以与其他应用程序相同的方式初始化是有意义的。
|
注意
|
应该很明显,但请记住,如果使用引导标志,配置服务器将需要在bootstrap.yml中配置其名称和存储库URI。
|
要更改服务器端点的位置,您可以(可选)设置spring.cloud.config.server.prefix,例如“/ config”,以提供前缀下的资源。前缀应该开始但不以“/”结尾。它应用于Config Server中的@RequestMappings(即Spring Boot前缀server.servletPath和server.contextPath)之下。
如果您想直接从后端存储库(而不是从配置服务器)读取应用程序的配置,这基本上是一个没有端点的嵌入式配置服务器。如果不使用@EnableConfigServer注释(仅设置spring.cloud.config.server.bootstrap=true),则可以完全关闭端点。
推送通知和Spring Cloud Bus
许多源代码存储库提供程序(例如Github,Gitlab或Bitbucket)将通过webhook通知您存储库中的更改。您可以通过提供商的用户界面将webhook配置为URL和一组感兴趣的事件。例如,
Github
将使用包含提交列表的JSON主体和“X-Github-Event”等于“push”的头文件发送到webhook。如果您在spring-cloud-config-monitor库中添加依赖关系并激活Config Server中的Spring Cloud Bus,则启用“/ monitor”端点。
当Webhook被激活时,配置服务器将发送一个针对他认为可能已经改变的应用的RefreshRemoteApplicationEvent。变更检测可以进行策略化,但默认情况下,它只是查找与应用程序名称匹配的文件的更改(例如,“foo.properties”针对的是“foo”应用程序,“application.properties”针对所有应用程序) 。如果要覆盖该行为的策略是PropertyPathNotificationExtractor,它接受请求标头和正文作为参数,并返回已更改的文件路径列表。
默认配置与Github,Gitlab或Bitbucket配合使用。除了来自Github,Gitlab或Bitbucket的JSON通知之外,您还可以通过使用表单编码的身体参数path={name}打印到“/ monitor”来触发更改通知。这将广播到匹配“{name}”模式的应用程序(可以包含通配符)。
|
注意
|
只有在配置服务器和客户端应用程序中激活spring-cloud-bus时,才会传送RefreshRemoteApplicationEvent。
|
|
注意
|
默认配置还检测本地git存储库中的文件系统更改(在这种情况下不使用webhook,但是一旦编辑配置文件,将会播放刷新)。 |
Spring Cloud Config客户端
Spring Boot应用程序可以立即利用Spring配置服务器(或应用程序开发人员提供的其他外部属性源),并且还会选择与Environment更改事件相关的一些其他有用功能。
配置第一引导
这是在类路径上具有Spring Cloud Config Client的任何应用程序的默认行为。当配置客户端启动时,它将绑定到配置服务器(通过引导配置属性spring.cloud.config.uri)并使用远程属性源初始化Spring Environment。
这样做的最终结果是所有想要使用Config Server的客户端应用程序都需要bootstrap.yml(或环境变量),服务器地址为spring.cloud.config.uri(默认为“http:// localhost:8888” )。
发现第一个引导
如果您正在使用“DiscoveryClient”实现,例如Spring Cloud Netflix和Eureka服务发现或Spring Cloud Consul(Spring Cloud Zookeeper不支持此功能),那么您如果您想要配置服务器可以使用发现服务器注册,但在默认的“配置优先”模式下,客户端将无法利用注册功能。
如果您希望使用DiscoveryClient找到配置服务器,可以通过设置spring.cloud.config.discovery.enabled=true(默认为“false”)来实现。最终的结果是客户端应用程序都需要具有适当发现配置的bootstrap.yml(或环境变量)。例如,使用Spring Cloud Netflix,您需要定义Eureka服务器地址,例如eureka.client.serviceUrl.defaultZone。使用此选项的价格是启动时额外的网络往返,以定位服务注册。好处是配置服务器可以更改其坐标,只要发现服务是一个固定点。默认服务ID为“configserver”,但您可以使用spring.cloud.config.discovery.serviceId(在服务器上以通常的方式更改服务的方式,例如设置spring.application.name)。
发现客户端实现都支持某种元数据映射(例如Eureka,我们有eureka.instance.metadataMap)。可能需要在其服务注册元数据中配置Config Server的一些其他属性,以便客户端可以正确连接。如果使用HTTP Basic安全配置服务器,则可以将凭据配置为“用户名”和“密码”。并且如果配置服务器具有上下文路径,您可以设置“configPath”。例如,对于作为Eureka客户端的配置服务器:
eureka:
instance:
...
metadataMap:
user: osufhalskjrtl
password: lviuhlszvaorhvlo5847
configPath: /config配置客户端快速失败
在某些情况下,如果服务无法连接到配置服务器,则可能希望启动服务失败。如果这是所需的行为,请设置引导配置属性spring.cloud.config.failFast=true,并且客户端将以异常停止。
配置客户端重试
如果您希望配置服务器在您的应用程序启动时可能偶尔不可用,您可以要求它在发生故障后继续尝试。首先,您需要设置spring.cloud.config.failFast=true,然后您需要将spring-retry和spring-boot-starter-aop添加到您的类路径中。默认行为是重试6次,初始退避间隔为1000ms,指数乘数为1.1,用于后续退避。您可以使用spring.cloud.config.retry.*配置属性配置这些属性(和其他)。
|
提示
|
要完全控制重试,请使用id“configServerRetryInterceptor”添加RetryOperationsInterceptor类型的@Bean。Spring重试有一个RetryInterceptorBuilder可以轻松创建一个。
|
查找远程配置资源
配置服务提供来自/{name}/{profile}/{label}的属性来源,客户端应用程序中的默认绑定
-
“name”=
${spring.application.name} -
“profile”=
${spring.profiles.active}(实际上是Environment.getActiveProfiles()) -
“label”=“master”
所有这些都可以通过设置spring.cloud.config.*(其中*为“name”,“profile”或“label”)来覆盖。“标签”可用于回滚到以前版本的配置; 使用默认的Config Server实现,它可以是git标签,分支名称或提交ID。标签也可以以逗号分隔的列表形式提供,在这种情况下,列表中的项目会逐个尝试,直到成功。当在特征分支上工作时,例如,当您可能希望将配置标签与分支对齐,但使其成为可选(例如spring.cloud.config.label=myfeature,develop)时,这可能非常有用。
安全
如果您在服务器上使用HTTP基本安全性,那么客户端只需要知道密码(如果不是默认用户名)。您可以通过配置服务器URI,或通过单独的用户名和密码属性,例如
spring:
cloud:
config:
uri: https://user:secret@myconfig.mycompany.com要么
spring:
cloud:
config:
uri: https://myconfig.mycompany.com
username: user
password: secretspring.cloud.config.password和spring.cloud.config.username值覆盖URI中提供的任何内容。
如果您在Cloud Foundry部署应用程序,则提供密码的最佳方式是通过服务凭证(例如URI),因为它甚至不需要在配置文件中。在Cloud Foundry上为本地工作的用户提供的服务的一个例子,名为“configserver”:
spring:
cloud:
config:
uri: ${vcap.services.configserver.credentials.uri:http://user:password@localhost:8888}如果您使用另一种形式的安全性,您可能需要向ConfigServicePropertySourceLocator提供RestTemplate(例如,通过在引导上下文中获取它并注入一个)。
Spring Cloud Netflix
服务发现:Eureka客户端
服务发现是基于微服务架构的关键原则之一。尝试配置每个客户端或某种形式的约定可能非常困难,可以非常脆弱。Netflix服务发现服务器和客户端是Eureka。可以将服务器配置和部署为高可用性,每个服务器将注册服务的状态复制到其他服务器。
注册Eureka
当客户端注册Eureka时,它提供有关自身的元数据,例如主机和端口,运行状况指示符URL,主页等。Eureka从属于服务的每个实例接收心跳消息。如果心跳失败超过可配置的时间表,则通常将该实例从注册表中删除。
示例eureka客户端:
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}(即完全正常的Spring Boot应用程序)。在这个例子中,我们明确地使用@EnableEurekaClient,但只有Eureka可用,你也可以使用@EnableDiscoveryClient。找到Eureka服务器需要进行配置。例:
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
其中“defaultZone”是一个魔术字符串后备值,为任何不表示首选项的客户端提供服务URL(即它是有用的默认值)。
从Environment获取的默认应用程序名称(服务ID),虚拟主机和非安全端口分别为${spring.application.name},${spring.application.name}和${server.port}。
@EnableEurekaClient使应用程序成为Eureka“实例”(即注册自身)和“客户端”(即它可以查询注册表以查找其他服务)。实例行为由eureka.instance.*配置键驱动,但如果您确保您的应用程序具有spring.application.name(这是Eureka服务ID或VIP的默认值),默认情况下将是正常的。
有关可配置选项的更多详细信息,请参阅EurekaInstanceConfigBean和EurekaClientConfigBean。
使用Eureka服务器进行身份验证
如果其中一个eureka.client.serviceUrl.defaultZone URL中嵌入了凭证(如http://user:password@localhost:8761/eureka)),HTTP基本身份验证将自动添加到您的eureka客户端。对于更复杂的需求,您可以创建DiscoveryClientOptionalArgs类型的@Bean并将ClientFilter实例注入到其中,所有这些都将应用于从客户端到服务器的调用。
|
注意
|
由于Eureka中的限制,不可能支持每个服务器的基本身份验证凭据,因此只能使用第一个找到的集合。 |
状态页和健康指标
Eureka实例的状态页面和运行状况指示符分别默认为“/ info”和“/ health”,它们是Spring Boot Actuator应用程序中有用端点的默认位置。如果您使用非默认上下文路径或servlet路径(例如server.servletPath=/foo)或管理端点路径(例如management.contextPath=/admin),则需要更改这些,即使是执行程序应用程序。例:
eureka:
instance:
statusPageUrlPath: ${management.context-path}/info
healthCheckUrlPath: ${management.context-path}/health
这些链接显示在客户端使用的元数据中,并在某些情况下用于决定是否将请求发送到应用程序,因此如果它们是准确的,这是有帮助的。
注册安全应用程序
如果您的应用程序想通过HTTPS联系,则可以分别在EurekaInstanceConfig,即eureka.instance.[nonSecurePortEnabled,securePortEnabled]=[false,true]中设置两个标志。即
v32 { }中设置两个标志。这将使Eureka发布实例信息显示安全通信的明确偏好。Spring云DiscoveryClient将始终为以这种方式配置的服务返回https://…; URI,并且Eureka(本机)实例信息将具有安全的健康检查URL。
由于Eureka在内部工作,它仍然会发布状态和主页的非安全URL,除非您也明确地覆盖。您可以使用占位符来配置eureka实例URL,例如
eureka:
instance:
statusPageUrl: https://${eureka.hostname}/info
healthCheckUrl: https://${eureka.hostname}/health
homePageUrl: https://${eureka.hostname}/
(请注意,${eureka.hostname}是仅在稍后版本的Eureka中可用的本机占位符,您也可以使用Spring占位符实现同样的功能,例如使用${eureka.instance.hostName}。
|
注意
|
如果您的应用程序在代理服务器后面运行,并且SSL终止服务在代理中(例如,如果您运行在Cloud Foundry或其他平台作为服务),则需要确保代理“转发”头部被截取并处理应用程序。Spring Boot应用程序中的嵌入式Tomcat容器会自动执行“X-Forwarded - \ *”头的显式配置。你这个错误的一个迹象就是你的应用程序本身所呈现的链接是错误的(错误的主机,端口或协议)。 |
Eureka的健康检查
默认情况下,Eureka使用客户端心跳来确定客户端是否启动。除非另有规定,否则发现客户端将不会根据Spring Boot Actuator传播应用程序的当前运行状况检查状态。这意味着成功注册后,Eureka将永远宣布申请处于“UP”状态。可以通过启用Eureka运行状况检查来改变此行为,从而将应用程序状态传播到Eureka。因此,每个其他应用程序将不会在“UP”之外的状态下将流量发送到应用程序。
eureka:
client:
healthcheck:
enabled: true
如果您需要更多的控制健康检查,您可以考虑实施自己的com.netflix.appinfo.HealthCheckHandler。
Eureka实例和客户端的元数据
值得花点时间了解Eureka元数据的工作原理,以便您可以在平台上使用它。有主机名,IP地址,端口号,状态页和运行状况检查等标准元数据。这些发布在服务注册表中,由客户使用,以直接的方式联系服务。额外的元数据可以添加到eureka.instance.metadataMap中的实例注册中,并且这将在远程客户端中可访问,但通常不会更改客户端的行为,除非意识到元数据的含义。下面描述了几个特殊情况,其中Spring Cloud已经为元数据映射指定了含义。
在Cloudfoundry上使用Eureka
Cloudfoundry有一个全局路由器,所以同一个应用程序的所有实例都具有相同的主机名(在具有相似架构的其他PaaS解决方案中也是如此)。这不一定是使用Eureka的障碍,但是如果您使用路由器(建议,甚至是强制性的,具体取决于您的平台的设置方式),则需要显式设置主机名和端口号(安全或非安全),以便他们使用路由器。您可能还需要使用实例元数据,以便您可以区分客户端上的实例(例如,在自定义负载平衡器中)。默认情况下,eureka.instance.instanceId为vcap.application.instance_id。例如:
eureka:
instance:
hostname: ${vcap.application.uris[0]}
nonSecurePort: 80
根据Cloudfoundry实例中安全规则的设置方式,您可以注册并使用主机VM的IP地址进行直接的服务到服务调用。此功能尚未在Pivotal Web Services(PWS)上提供。
在AWS上使用Eureka
如果应用程序计划将部署到AWS云,那么Eureka实例必须被配置为亚马逊意识到,这可以通过定制来完成EurekaInstanceConfigBean方式如下:
@Bean
@Profile("!default")
public EurekaInstanceConfigBean eurekaInstanceConfig() {
EurekaInstanceConfigBean b = new EurekaInstanceConfigBean();
AmazonInfo info = AmazonInfo.Builder.newBuilder().autoBuild("eureka");
b.setDataCenterInfo(info);
return b;
}更改Eureka实例ID
香草Netflix Eureka实例注册了与其主机名相同的ID(即每个主机只有一个服务)。Spring Cloud Eureka提供了一个明智的默认,如下所示:${spring.cloud.client.hostname}:${spring.application.name}:${spring.application.instance_id:${server.port}}}。例如myhost:myappname:8080。
使用Spring Cloud,您可以通过在eureka.instance.instanceId中提供唯一的标识来覆盖此。例如:
eureka:
instance:
instanceId: ${spring.application.name}:${spring.application.instance_id:${random.value}}
使用这个元数据和在localhost上部署的多个服务实例,随机值将在那里进行,以使实例是唯一的。在Cloudfoundry中,spring.application.instance_id将在Spring Boot Actuator应用程序中自动填充,因此不需要随机值。
使用EurekaClient
一旦您有一个@EnableDiscoveryClient(或@EnableEurekaClient)的应用程序,您可以使用它来发现Eureka服务器的服务实例。一种方法是使用本机com.netflix.discovery.EurekaClient(而不是Spring Cloud DiscoveryClient),例如
@Autowired
private EurekaClient discoveryClient;
public String serviceUrl() {
InstanceInfo instance = discoveryClient.getNextServerFromEureka("STORES", false);
return instance.getHomePageUrl();
}
|
提示
|
不要使用 |
本机Netflix EurekaClient的替代方案
您不必使用原始的Netflix EurekaClient,通常在某种包装器后面使用它更为方便。Spring Cloud支持Feign(REST客户端构建器),还支持Spring RestTemplate使用逻辑Eureka服务标识符(VIP)而不是物理URL。要使用固定的物理服务器列表配置Ribbon,您可以将<client>.ribbon.listOfServers设置为逗号分隔的物理地址(或主机名)列表,其中<client>是客户端的ID。
您还可以使用org.springframework.cloud.client.discovery.DiscoveryClient,它为Netflix不具体的发现客户端提供简单的API,例如
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List<ServiceInstance> list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri();
}
return null;
}
为什么注册服务这么慢?
作为一个实例也包括定期心跳到注册表(通过客户端的serviceUrl),默认持续时间为30秒。在实例,服务器和客户端在其本地缓存中都具有相同的元数据(因此可能需要3个心跳)之前,客户端才能发现服务。您可以使用eureka.instance.leaseRenewalIntervalInSeconds更改期限,这将加快客户端连接到其他服务的过程。在生产中,最好坚持使用默认值,因为服务器内部有一些计算可以对租赁更新期进行假设。
服务发现:Eureka服务器
示例eureka服务器(例如使用spring-cloud-starter-eureka-server设置类路径):
@SpringBootApplication
@EnableEurekaServer
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}根据/eureka/*的正常Eureka功能,服务器具有带有UI的主页和HTTP API端点。
|
提示
|
由于Gradle的依赖关系解决规则和父母的bom功能缺乏,只要依靠spring-cloud-starter-eureka-server就可能导致应用程序启动失败。为了解决这个问题,必须添加Spring Boot Gradle插件,并且必须像这样导入Spring云启动器父母bom: 的build.gradle
|
高可用性,区域和地区
Eureka服务器没有后端存储,但是注册表中的服务实例都必须发送心跳线以保持其注册更新(因此可以在内存中完成)。客户端还具有eureka注册的内存缓存(因此,他们不必为注册表提供每个服务请求)。
默认情况下,每个Eureka服务器也是Eureka客户端,并且需要(至少一个)服务URL来定位对等体。如果您不提供该服务将运行和工作,但它将淋浴您的日志与大量的噪音无法注册对等体。
有关区域和区域的客户端Ribbon支持的详细信息,请参见下文。
独立模式
只要存在某种监视器或弹性运行时间(例如Cloud Foundry),两个缓存(客户机和服务器)和心跳的组合使独立的Eureka服务器对故障具有相当的弹性。在独立模式下,您可能更喜欢关闭客户端行为,因此不会继续尝试并且无法访问其对等体。例:
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
请注意,serviceUrl指向与本地实例相同的主机。
同行意识
通过运行多个实例并请求他们相互注册,可以使Eureka更具弹性和可用性。实际上,这是默认的行为,所以你需要做的只是为对方添加一个有效的serviceUrl,例如
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
client:
serviceUrl:
defaultZone: http://peer2/eureka/
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
client:
serviceUrl:
defaultZone: http://peer1/eureka/
在这个例子中,我们有一个YAML文件可以用于通过在不同的Spring配置文件中运行,在2台主机(peer1和peer2)上运行相同的服务器。您可以使用此配置来测试单个主机上的对等体感知(通过操作/etc/hosts来解析主机名,在生产中没有太多价值)。事实上,如果您在一台知道自己的主机名的机器上运行(默认情况下使用java.net.InetAddress查找),则不需要eureka.instance.hostname。
您可以向系统添加多个对等体,只要它们彼此直接相连,就可以将它们之间的注册同步。
eureka:
client:
serviceUrl:
defaultZone: http://peer1/eureka/,http://peer2/eureka/,http://peer3/eureka/
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
---
spring:
profiles: peer3
eureka:
instance:
hostname: peer3
喜欢IP地址
在某些情况下,Eureka最好广告服务的IP地址,而不是主机名。将eureka.instance.preferIpAddress设置为true,当应用程序向eureka注册时,它将使用其IP地址而不是其主机名。
断路器:Hystrix客户

较低级别的服务中的服务故障可能导致用户级联故障。当对特定服务的呼叫达到一定阈值时(Hystrix中默认为20秒,20秒),电路打开,不进行通话。在错误和开路的情况下,开发人员可以提供后备。
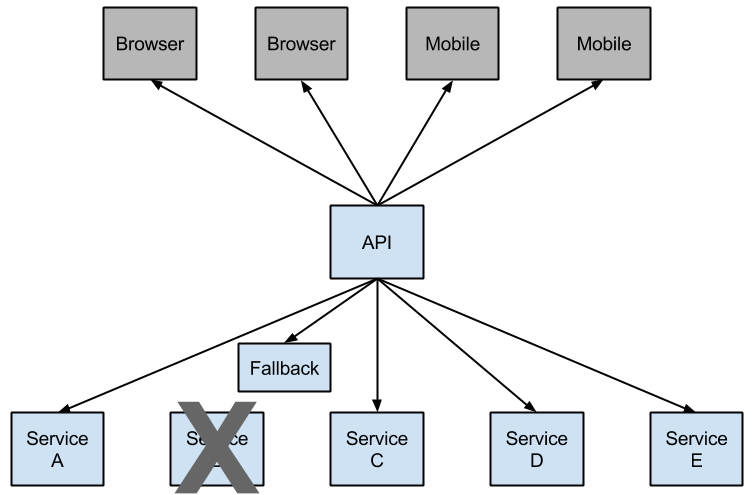
开放式电路会停止级联故障,并允许不必要的或失败的服务时间来愈合。回退可以是另一个Hystrix保护的调用,静态数据或一个正常的空值。回退可能被链接,所以第一个回退使得一些其他业务电话又回到静态数据。
示例启动应用程序:
@SpringBootApplication
@EnableCircuitBreaker
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
@Component
public class StoreIntegration {
@HystrixCommand(fallbackMethod = "defaultStores")
public Object getStores(Map<String, Object> parameters) {
//do stuff that might fail
}
public Object defaultStores(Map<String, Object> parameters) {
return /* something useful */;
}
}
@HystrixCommand由名为“javanica”的Netflix contrib库提供
。Spring Cloud在连接到Hystrix断路器的代理中使用该注释自动包装Spring bean。断路器计算何时打开和关闭电路,以及在发生故障时应该做什么。
要配置@HystrixCommand,您可以使用commandProperties属性列出@HystrixProperty注释。请参阅
这里
了解更多详情。有关
可用属性的详细信息,请参阅Hystrix维基。
传播安全上下文或使用Spring范围
如果您希望某些线程本地上下文传播到@HystrixCommand中,默认声明将不起作用,因为它在线程池中执行命令(超时)。您可以使用某些配置或直接在注释中将Hystrix切换为使用与调用者相同的线程,要求使用不同的“隔离策略”。例如:
@HystrixCommand(fallbackMethod = "stubMyService",
commandProperties = {
@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE")
}
)
...如果您使用@SessionScope或@RequestScope,同样的事情也适用。您将知道何时需要执行此操作,因为运行时异常说它找不到范围的上下文。
健康指标
连接断路器的状态也暴露在呼叫应用程序的/health端点。
{
"hystrix": {
"openCircuitBreakers": [
"StoreIntegration::getStoresByLocationLink"
],
"status": "CIRCUIT_OPEN"
},
"status": "UP"
}Hystrix指标流
要使Hystrix指标流包含对spring-boot-starter-actuator的依赖。这将使/hystrix.stream作为管理端点。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>断路器:Hystrix仪表板
Hystrix的主要优点之一是它收集关于每个HystrixCommand的一套指标。Hystrix仪表板以有效的方式显示每个断路器的运行状况。
运行Hystrix仪表板使用@EnableHystrixDashboard注释您的Spring Boot主类。然后访问/hystrix,并将仪表板指向Hystrix客户端应用程序中的单个实例/hystrix.stream端点。
Turbine
查看个别实例Hystrix数据在系统整体健康方面不是非常有用。Turbine是将所有相关/hystrix.stream端点聚合成Hystrix仪表板中使用的组合/turbine.stream的应用程序。个人实例位于Eureka。运行Turbine就像使用@EnableTurbine注释(例如使用spring-cloud-starter-turbine设置类路径)注释主类一样简单。来自Turbine 1维基的所有文档配置属性都适用。唯一的区别是turbine.instanceUrlSuffix不需要预先添加的端口,除非turbine.instanceInsertPort=false自动处理。
配置密钥turbine.appConfig是涡轮机将用于查找实例的尤里卡服务列表。涡轮流然后在Hystrix仪表板中使用如下URL:http://my.turbine.sever:8080/turbine.stream?cluster=<CLUSTERNAME>;(如果名称为“默认值”,则可以省略群集参数)。cluster参数必须与turbine.aggregator.clusterConfig中的条目相匹配。从eureka返回的值是大写字母,因此如果有一个名为“customers”的Eureka注册了一个应用程序,我们希望这个例子可以工作:
turbine:
aggregator:
clusterConfig: CUSTOMERS
appConfig: customers
clusterName可以通过turbine.clusterNameExpression中的SPEL表达式以root身份InstanceInfo定制。默认值为appName,这意味着Eureka serviceId最终作为集群密钥(即客户的InstanceInfo具有appName“CUSTOMERS”)。一个不同的例子是turbine.clusterNameExpression=aSGName,它将从AWS ASG名称获取集群名称。另一个例子:
turbine:
aggregator:
clusterConfig: SYSTEM,USER
appConfig: customers,stores,ui,admin
clusterNameExpression: metadata['cluster']
在这种情况下,来自4个服务的集群名称从其元数据映射中提取,并且预期具有包含“SYSTEM”和“USER”的值。
要为所有应用程序使用“默认”集群,您需要一个字符串文字表达式(带单引号,并且如果它在YAML中也使用双引号进行转义):
turbine: appConfig: customers,stores clusterNameExpression: "'default'"
Spring Cloud提供了一个spring-cloud-starter-turbine,它具有运行Turbine服务器所需的所有依赖关系。只需创建一个Spring Boot应用程序并用@EnableTurbine注释它。
|
注意
|
默认情况下,天然的Netflix行为内置到Turbine并没有允许每台主机多个进程,每个群集(关键到实例id是主机名)。Spring Cloud概括一下,允许主机和端口用作键,但只有设置属性turbine.combineHostPort=true
|
Turbine流
在某些环境中(例如在PaaS设置中),所有分布式Hystrix命令拉取度量的经典Turbine模型不起作用。在这种情况下,您可能希望让您的Hystrix命令将度量标准推送到Turbine,并且Spring Cloud可以使用消息传递。您需要在客户端上执行的所有操作都为您选择的spring-cloud-netflix-hystrix-stream和spring-cloud-starter-stream-*添加依赖关系(有关经纪人的详细信息,请参阅Spring Cloud Stream文档,以及如何配置客户端凭据,但应该为当地经纪人开箱即用)。
在服务器端只需创建一个Spring Boot应用程序并使用@EnableTurbineStream进行注释,默认情况下,它将出现在端口8989(将您的Hystrix仪表板指向该端口,任何路径)。您可以使用server.port或turbine.stream.port自定义端口。如果类路径中还有spring-boot-starter-web和spring-boot-starter-actuator,那么您可以通过提供不同的management.port在单独的端口(默认情况下使用Tomcat)打开Actuator端点。
然后,您可以将Hystrix仪表板指向Turbine流服务器,而不是单个Hystrix流。如果Turbine Stream在myhost上的端口8989上运行,则将http://myhost:8989放在Hystrix仪表板中的流输入字段中。电路将以各自的serviceId为前缀,后跟一个点,然后是电路名称。
Spring Cloud提供了一个spring-cloud-starter-turbine-stream,它具有您需要的所有依赖关系,以获取Turbine Stream服务器运行 - 只需添加您选择的Stream binder,例如spring-cloud-starter-stream-rabbit。您需要Java 8来运行应用程序,因为它是基于Netty的。
客户端负载均衡器:Ribbon
Ribbon是一个客户端负载平衡器,可以很好地控制HTTP和TCP客户端的行为。Feign已经使用Ribbon,所以如果您使用@FeignClient,则此部分也适用。
Ribbon中的中心概念是命名客户端的概念。每个负载均衡器是组合的组合的一部分,它们一起工作以根据需要联系远程服务器,并且集合具有将其作为应用程序开发人员(例如使用@FeignClient注释)的名称。Spring Cloud使用RibbonClientConfiguration为每个已命名的客户端根据需要创建一个新的集合,作为ApplicationContext。这包含(其中包括)ILoadBalancer,RestClient和ServerListFilter。
自定义Ribbon客户端
您可以使用<client>.ribbon.*中的外部属性配置Ribbon客户端的某些位,这与使用Netflix API本身没有区别,只是您可以使用Spring Boot配置文件。本地选项可以作为CommonClientConfigKey(功能区内核心部分)中的静态字段进行检查。
Spring Cloud还允许您通过使用@RibbonClient声明其他配置(位于RibbonClientConfiguration之上)来完全控制客户端。例:
@Configuration
@RibbonClient(name = "foo", configuration = FooConfiguration.class)
public class TestConfiguration {
}在这种情况下,客户端由RibbonClientConfiguration中的组件与FooConfiguration中的任何组件组成(后者通常将覆盖前者)。
|
警告
|
FooConfiguration必须是@Configuration,但要注意主应用程序上下文不属于@ComponentScan,否则将由@RibbonClients所有者共享。如果您使用@ComponentScan(或@SpringBootApplication),则需要采取措施避免包含(例如将其放在一个单独的,不重叠的包中,或者指定要在@ComponentScan)。
|
Spring Cloud Netflix默认提供以下功能区(BeanType beanName:ClassName)的bean:
-
IClientConfigribbonClientConfig:DefaultClientConfigImpl -
IRuleribbonRule:ZoneAvoidanceRule -
IPingribbonPing:NoOpPing -
ServerList<Server>ribbonServerList:ConfigurationBasedServerList -
ServerListFilter<Server>ribbonServerListFilter:ZonePreferenceServerListFilter -
ILoadBalancerribbonLoadBalancer:ZoneAwareLoadBalancer
创建一个类型的bean并将其放置在@RibbonClient配置(例如上面的FooConfiguration)中)允许您覆盖所描述的每个bean。例:
@Configuration
public class FooConfiguration {
@Bean
public IPing ribbonPing(IClientConfig config) {
return new PingUrl();
}
}这将PingUrl替换为NoOpPing。
使用Ribbon与Eureka
当Eureka与Ribbon结合使用时,ribbonServerList的扩展名DiscoveryEnabledNIWSServerList将被覆盖,从Eureka填充服务器列表。它还将IPing接口替换为NIWSDiscoveryPing,委托给Eureka以确定服务器是否已启动。默认情况下安装的ServerList是一个DomainExtractingServerList,其目的是使物理元数据可用于负载平衡器,而不使用AWS AMI元数据(Netflix依赖于此)。默认情况下,服务器列表将使用实例元数据(如远程客户端集合eureka.instance.metadataMap.zone)中提供的“区域”信息构建,如果缺少,则可以使用服务器主机名中的域名作为代理用于区域(如果设置了标志approximateZoneFromHostname)。一旦区域信息可用,它可以在ServerListFilter中使用。默认情况下,它将用于定位与客户端相同区域的服务器,因为默认值为ZonePreferenceServerListFilter。默认情况下,客户端的区域与远程实例相同,即通过eureka.instance.metadataMap.zone确定。
|
注意
|
设置客户端区域的正统“archaius”方式是通过名为“@zone”的配置属性,如果可用,Spring Cloud将优先使用所有其他设置(请注意,该键必须被引用)在YAML配置中)。 |
|
注意
|
如果没有其他的区域数据源,则基于客户端配置(与实例配置相反)进行猜测。我们将eureka.client.availabilityZones(从区域名称映射到区域列表),并拉出实例本身区域的第一个区域(即eureka.client.region,默认为“us-east-1”为与本机Netflix的兼容性)。
|
示例:如何使用Ribbon不使用Eureka
Eureka是一种方便的方法来抽象远程服务器的发现,因此您不必在客户端中对其URL进行硬编码,但如果您不想使用它,Ribbon和Feign仍然很适用的。假设您已经为“商店”申明了@RibbonClient,并且Eureka未被使用(甚至不在类路径上)。Ribbon客户端默认为已配置的服务器列表,您可以提供这样的配置
stores:
ribbon:
listOfServers: example.com,google.com
示例:在Ribbon中禁用Eureka使用
设置属性ribbon.eureka.enabled = false将明确禁用在Ribbon中使用Eureka。
ribbon: eureka: enabled: false
直接使用Ribbon API
您也可以直接使用LoadBalancerClient。例:
public class MyClass {
@Autowired
private LoadBalancerClient loadBalancer;
public void doStuff() {
ServiceInstance instance = loadBalancer.choose("stores");
URI storesUri = URI.create(String.format("http://%s:%s", instance.getHost(), instance.getPort()));
// ... do something with the URI
}
}声明性REST客户端:Feign
Feign是一个声明式的Web服务客户端。这使得Web服务客户端的写入更加方便 要使用Feign创建一个界面并对其进行注释。它具有可插入的注释支持,包括Feign注释和JAX-RS注释。Feign还支持可插拔编码器和解码器。Spring Cloud添加了对Spring MVC注释的支持,并在Spring Web中使用默认使用的相同HttpMessageConverters。Spring Cloud集成Ribbon和Eureka以在使用Feign时提供负载平衡的http客户端。
示例Spring Boot应用程序
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@EnableFeignClients
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}@FeignClient("stores")
public interface StoreClient {
@RequestMapping(method = RequestMethod.GET, value = "/stores")
List<Store> getStores();
@RequestMapping(method = RequestMethod.POST, value = "/stores/{storeId}", consumes = "application/json")
Store update(@PathVariable("storeId") Long storeId, Store store);
}在@FeignClient注释中,String值(以上“存储”)是一个任意的客户端名称,用于创建Ribbon负载平衡器(有关Ribbon支持的详细信息,请参阅下文))。您还可以使用url属性(绝对值或仅主机名)指定URL。应用程序上下文中的bean的名称是该接口的完全限定名称。还创建了一个别名,它是'name'属性加'FeignClient'。对于上面的示例,可以使用@Qualifier("storesFeignClient")来引用该bean。
以上的Ribbon客户端将要发现“商店”服务的物理地址。如果您的应用程序是Eureka客户端,那么它将解决Eureka服务注册表中的服务。如果您不想使用Eureka,您可以简单地配置外部配置中的服务器列表(例如,参见 上文)。
覆盖Feign默认值
Spring Cloud的Feign支持中的中心概念是指定的客户端。每个假装客户端都是组合的组件的一部分,它们一起工作以按需联系远程服务器,并且该集合具有您将其作为应用程序开发人员使用@FeignClient注释的名称。Spring Cloud使用FeignClientsConfiguration为每个命名的客户端按需要创建一个新的集合ApplicationContext。这包含(除其他外)feign.Decoder,feign.Encoder和feign.Contract。
Spring Cloud可以通过使用@FeignClient声明额外的配置(FeignClientsConfiguration之外)来完全控制假客户端。例:
@FeignClient(name = "stores", configuration = FooConfiguration.class)
public interface StoreClient {
//..
}在这种情况下,客户端由FeignClientsConfiguration中已经存在的组件与FooConfiguration中的任何组件组成(后者将覆盖前者)。
|
警告
|
FooConfiguration必须是@Configuration,但请注意,对于主应用程序上下文,它不在@ComponentScan中,否则将用于每个@FeignClient。如果您使用@ComponentScan(或@SpringBootApplication),则需要采取措施避免包含(例如将其放在一个单独的,不重叠的包中,或者指定要在@ComponentScan)。
|
|
注意
|
serviceId属性现在已被弃用,有利于name属性。
|
|
警告
|
以前,使用url属性,不需要name属性。现在需要使用name。
|
name和url属性支持占位符。
@FeignClient(name = "${feign.name}", url = "${feign.url}")
public interface StoreClient {
//..
}Spring Cloud Netflix默认为feign(BeanType beanName:ClassName)提供以下bean:
-
DecoderfeignDecoder:ResponseEntityDecoder(其中包含SpringDecoder) -
EncoderfeignEncoder:SpringEncoder -
LoggerfeignLogger:Slf4jLogger -
ContractfeignContract:SpringMvcContract -
Feign.BuilderfeignBuilder:HystrixFeign.Builder
Spring Cloud Netflix 默认情况下不提供以下bean,但是仍然从应用程序上下文中查找这些类型的bean以创建feign客户端:
-
Logger.Level -
Retryer -
ErrorDecoder -
Request.Options -
Collection<RequestInterceptor>
创建一个类型的bean并将其放置在@FeignClient配置(例如上面的FooConfiguration)中)允许您覆盖所描述的每个bean。例:
@Configuration
public class FooConfiguration {
@Bean
public Contract feignContract() {
return new feign.Contract.Default();
}
@Bean
public BasicAuthRequestInterceptor basicAuthRequestInterceptor() {
return new BasicAuthRequestInterceptor("user", "password");
}
}将SpringMvcContract替换为feign.Contract.Default,并将RequestInterceptor添加到RequestInterceptor的集合中。
可以在@EnableFeignClients属性defaultConfiguration中以与上述类似的方式指定默认配置。不同之处在于,此配置将适用于所有假客户端。
Feign Hystrix支持
如果Hystrix在类路径上,默认情况下Feign将使用断路器包装所有方法。还可以返回com.netflix.hystrix.HystrixCommand。这允许您使用无效模式(调用.toObservable()或.observe()或异步使用(调用.queue()))。
要禁用Hystrix支持Feign,请设置feign.hystrix.enabled=false。
要在每个客户端基础上禁用Hystrix支持,使用“prototype”范围创建一个vanilla Feign.Builder,例如:
@Configuration
public class FooConfiguration {
@Bean
@Scope("prototype")
public Feign.Builder feignBuilder() {
return Feign.builder();
}
}Feign Hystrix回退
Hystrix支持回退的概念:当电路打开或出现错误时执行的默认代码路径。要为给定的@FeignClient启用回退,请将fallback属性设置为实现回退的类名。
@FeignClient(name = "hello", fallback = HystrixClientFallback.class)
protected interface HystrixClient {
@RequestMapping(method = RequestMethod.GET, value = "/hello")
Hello iFailSometimes();
}
static class HystrixClientFallback implements HystrixClient {
@Override
public Hello iFailSometimes() {
return new Hello("fallback");
}
}|
警告
|
在Feign中执行回退以及如何Hystrix回退工作有一个局限性。当前返回com.netflix.hystrix.HystrixCommand和rx.Observable的方法目前不支持回退。
|
Feign继承支持
Feign通过单继承接口支持样板apis。这样就可以将常用操作分成方便的基本界面。
public interface UserService {
@RequestMapping(method = RequestMethod.GET, value ="/users/{id}")
User getUser(@PathVariable("id") long id);
}@RestController
public class UserResource implements UserService {
}package project.user;
@FeignClient("users")
public interface UserClient extends UserService {
}|
注意
|
通常不建议在服务器和客户端之间共享接口。它引入紧耦合,实际上并不适用于当前形式的Spring MVC(方法参数映射不被继承)。 |
Feign请求/响应压缩
您可以考虑启用针对您的Feign请求的请求或响应GZIP压缩。您可以通过启用其中一个属性来执行此操作:
feign.compression.request.enabled=true
feign.compression.response.enabled=trueFeign请求压缩为您提供与您为Web服务器设置的设置相似的设置:
feign.compression.request.enabled=true
feign.compression.request.mime-types=text/xml,application/xml,application/json
feign.compression.request.min-request-size=2048这些属性可以让您对压缩介质类型和最小请求阈值长度有选择性。
Feign日志记录
为每个创建的Feign客户端创建一个记录器。默认情况下,记录器的名称是用于创建Feign客户端的接口的完整类名。Feign日志记录仅响应DEBUG级别。
logging.level.project.user.UserClient: DEBUG您可以为每个客户端配置的Logger.Level对象告诉Feign记录多少。选择是:
-
NONE,无记录(DEFAULT)。 -
BASIC,只记录请求方法和URL以及响应状态代码和执行时间。 -
HEADERS,记录基本信息以及请求和响应标头。 -
FULL,记录请求和响应的头文件,正文和元数据。
例如,以下将Logger.Level设置为FULL:
@Configuration
public class FooConfiguration {
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}外部配置:Archaius
Netflix客户端配置库是Archaius。它是所有Netflix OSS组件用于配置的库。Archaius是Apache Commons配置项目的扩展。它允许通过轮询源进行更改或将源更改推送到客户端来进行配置更新。Archaius使用Dynamic <Type> Property类作为属性的句柄。
class ArchaiusTest {
DynamicStringProperty myprop = DynamicPropertyFactory
.getInstance()
.getStringProperty("my.prop");
void doSomething() {
OtherClass.someMethod(myprop.get());
}
}Archaius具有自己的一组配置文件和加载优先级。Spring应用程序通常不应直接使用Archaius,但本地仍然需要配置Netflix工具。Spring Cloud有一个Spring环境桥,所以Archaius可以从Spring环境读取属性。这允许Spring Boot项目使用正常的配置工具链,同时允许他们在文档中大部分配置Netflix工具。
路由器和过滤器:Zuul
路由在微服务体系结构的一个组成部分。例如,/可以映射到您的Web应用程序,/api/users映射到用户服务,/api/shop映射到商店服务。Zuul是Netflix的基于JVM的路由器和服务器端负载均衡器。
Netflix使用Zuul以下内容:
-
认证
-
洞察
-
压力测试
-
金丝雀测试
-
动态路由
-
服务迁移
-
负载脱落
-
安全
-
静态响应处理
-
主动/主动流量管理
Zuul的规则引擎允许基本上以任何JVM语言编写规则和过滤器,内置对Java和Groovy的支持。
|
注意
|
配置属性zuul.max.host.connections已被两个新属性zuul.host.maxTotalConnections和zuul.host.maxPerRouteConnections替换,分别默认为200和20。
|
嵌入Zuul反向代理
Spring Cloud已经创建了一个嵌入式Zuul代理,以简化UI应用程序想要代理对一个或多个后端服务的呼叫的非常常见的用例的开发。此功能对于用户界面对其所需的后端服务进行代理是有用的,避免了对所有后端独立管理CORS和验证问题的需求。
要启用它,请使用@EnableZuulProxy注释Spring Boot主类,并将本地调用转发到相应的服务。按照惯例,具有ID“用户”的服务将接收来自位于/users(具有前缀stripped)的代理的请求。代理使用Ribbon来定位要通过发现转发的实例,并且所有请求都以hystrix命令执行,所以故障将显示在Hystrix指标中,一旦电路打开,代理将不会尝试联系服务。
|
注意
|
Zuul启动器不包括发现客户端,因此对于基于服务ID的路由,您还需要在类路径中提供其中一个路由(例如Eureka)。 |
要跳过自动添加的服务,请将zuul.ignored-services设置为服务标识模式列表。如果一个服务匹配一个被忽略的模式,而且包含在明确配置的路由映射中,那么它将被无符号。例:
zuul:
ignoredServices: '*'
routes:
users: /myusers/**在此示例中,除 “用户” 之外,所有服务都被忽略。
要扩充或更改代理路由,可以添加如下所示的外部配置:
zuul:
routes:
users: /myusers/**这意味着对“/ myusers”的http呼叫转发到“用户”服务(例如“/ myusers / 101”转发到“/ 101”)。
要获得对路由的更细粒度的控制,您可以独立地指定路径和serviceId:
zuul:
routes:
users:
path: /myusers/**
serviceId: users_service这意味着对“/ myusers”的http呼叫转发到“users_service”服务。路由必须有一个“路径”,可以指定为蚂蚁样式模式,所以“/ myusers / *”只匹配一个级别,但“/ myusers / **”分层匹配。
后端的位置可以被指定为“serviceId”(用于发现的服务)或“url”(对于物理位置),例如
zuul:
routes:
users:
path: /myusers/**
url: http://example.com/users_service这些简单的URL路由不会被执行为HystrixCommand,也不能使用Ribbon对多个URL进行负载平衡。为此,请指定service-route并为serviceId配置Ribbon客户端(目前需要在Ribbon中禁用Eureka支持:详见上文),例如
zuul:
routes:
users:
path: /myusers/**
serviceId: users
ribbon:
eureka:
enabled: false
users:
ribbon:
listOfServers: example.com,google.com您可以使用regexmapper在serviceId和路由之间提供约定。它使用名为group的正则表达式从serviceId中提取变量并将它们注入到路由模式中。
@Bean
public PatternServiceRouteMapper serviceRouteMapper() {
return new PatternServiceRouteMapper(
"(?<name>^.+)-(?<version>v.+$)",
"${version}/${name}");
}这意味着serviceId“myusers-v1”将被映射到路由“/ v1 / myusers / **”。任何正则表达式都被接受,但所有命名组都必须存在于servicePattern和routePattern中。如果servicePattern与serviceId不匹配,则使用默认行为。在上面的示例中,serviceId“myusers”将被映射到路由“/ myusers / **”(检测不到版本)此功能默认禁用,仅适用于已发现的服务。
要为所有映射添加前缀,请将zuul.prefix设置为一个值,例如/api。默认情况下,转发请求之前,从请求中删除代理前缀(使用zuul.stripPrefix=false切换此行为)。您还可以关闭从各路线剥离服务特定的前缀,例如
zuul:
routes:
users:
path: /myusers/**
stripPrefix: false在本示例中,对“/ myusers / 101”的请求将转发到“/ myusers / 101”上的“users”服务。
zuul.routes条目实际上绑定到类型为ZuulProperties的对象。如果您查看该对象的属性,您将看到它还具有“可重试”标志。将该标志设置为“true”使Ribbon客户端自动重试失败的请求(如果需要,可以使用Ribbon客户端配置修改重试操作的参数)。
默认情况下,将X-Forwarded-Host标头添加到转发的请求中。要关闭set zuul.addProxyHeaders = false。默认情况下,前缀路径被删除,对后端的请求会拾取一个标题“X-Forwarded-Prefix”(上述示例中的“/ myusers”)。
如果您设置默认路由(“/”),例如zuul.route.home:
/将路由所有流量(即“/ **”)到“home”服务,则具有@EnableZuulProxy的应用程序可以充当独立服务器。
如果需要更细粒度的忽略,可以指定要忽略的特定模式。在路由位置处理开始时评估这些模式,这意味着前缀应包含在模式中以保证匹配。忽略的模式跨越所有服务,并取代任何其他路由规范。
zuul:
ignoredPatterns: /**/admin/**
routes:
users: /myusers/**这意味着诸如“/ myusers / 101”的所有呼叫将被转发到“用户”服务上的“/ 101”。但是包含“/ admin /”的呼叫将无法解决。
Cookie和敏感标题
在同一个系统中的服务之间共享标题是可行的,但是您可能不希望敏感标头泄漏到外部服务器的下游。您可以在路由配置中指定被忽略头文件列表。Cookies起着特殊的作用,因为它们在浏览器中具有明确的语义,并且它们总是被视为敏感的。如果代理的消费者是浏览器,则下游服务的cookie也会导致用户出现问题,因为它们都被混淆(所有下游服务看起来都是来自同一个地方)。
如果您对服务的设计非常谨慎,例如,如果只有一个下游服务设置了Cookie,那么您可能可以让他们从后台一直到调用者。此外,如果您的代理设置Cookie,并且所有后端服务都是同一系统的一部分,那么简单地共享它们就可以自然(例如使用Spring Session将它们链接到一些共享状态)。除此之外,由下游服务设置的任何Cookie可能对呼叫者来说都不是很有用,因此建议您将(至少)“Set-Cookie”和“Cookie”设置为不属于您的域名。即使是属于您域名的路线,请尝试仔细考虑允许Cookie在代理之间流动的含义。
灵敏头可以配置为每个路由的逗号分隔列表,例如
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders: Cookie,Set-Cookie,Authorization
url: https://downstream也可以通过设置zuul.sensitiveHeaders来全局设置敏感标题。如果在路由上设置了sensitiveHeaders,这将覆盖全局sensitiveHeaders设置。
|
注意
|
这是sensitiveHeaders的默认值,因此您不需要设置它,除非您希望它不同。注意这是Spring Cloud Netflix 1.1中的新功能(在1.0中,用户无法控制标题,所有Cookie都在两个方向上流动)。
|
除了每个路由的敏感标头,您还可以为与下游服务交互期间应该丢弃(请求和响应)的值设置全局值zuul.ignoredHeaders。默认情况下,如果Spring安全性不在类路径上,则它们是空的,否则它们被初始化为Spring安全性所指定的一组众所周知的“安全”头(例如涉及缓存)。在这种情况下的假设是下游服务可能也添加这些头,我们希望代理的值。
路线端点
如果您使用Spring Boot Actuator使用@EnableZuulProxy,则将启用(默认情况下)另一个端点,通过HTTP可用作/routes。到此端点的GET将返回映射路由的列表。POST将强制刷新现有路由(例如,如果服务目录中有更改)。
|
注意
|
路由应自动响应服务目录中的更改,但POST到/路由是强制更改立即发生的一种方式。 |
扼杀模式和本地Forwards
迁移现有应用程序或API时的常见模式是“扼杀”旧端点,用不同的实现慢慢替换它们。Zuul代理是一个有用的工具,因为您可以使用它来处理来自旧端点的客户端的所有流量,但将一些请求重定向到新端点。
示例配置:
zuul:
routes:
first:
path: /first/**
url: http://first.example.com
second:
path: /second/**
url: forward:/second
third:
path: /third/**
url: forward:/3rd
legacy:
path: /**
url: http://legacy.example.com在这个例子中,我们扼杀了“遗留”应用程序,该应用程序映射到所有与其他模式不匹配的请求。已将/first/**中的路径提取到带有外部URL的新服务中。而/second/**中的路径是forwared,因此可以在本地进行处理,例如正常Spring @RequestMapping。/third/**中的路径也被转发,但使用不同的前缀(即/third/foo转发到/3rd/foo)。
|
注意
|
被忽略的模式并不完全被忽略,它们只是不被代理处理(因此它们也被有效地转发到本地)。 |
通过Zuul上传文件
如果您@EnableZuulProxy您可以使用代理路径上传文件,只要文件很小就可以使用。对于大文件,有一个替代路径绕过“/ zuul / *”中的Spring DispatcherServlet(以避免多部分处理)。也就是说,如果zuul.routes.customers=/customers/**则可以将大文件发送到“/ zuul / customers / *”。servlet路径通过zuul.servletPath进行外部化。如果代理路由引导您通过Ribbon负载均衡器,例如,超大文件也将需要提升超时设置
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 60000
ribbon:
ConnectTimeout: 3000
ReadTimeout: 60000请注意,要使用大型文件进行流式传输,您需要在请求中使用分块编码(某些浏览器默认情况下不会执行)。例如在命令行:
$ curl -v -H "Transfer-Encoding: chunked" \
-F "file=@mylarge.iso" localhost:9999/zuul/simple/file
普通嵌入Zuul
如果您使用@EnableZuulServer(而不是@EnableZuulProxy),您也可以选择性地运行Zuul服务器而不进行代理,或选择性地切换代理平台的部分。您添加到类型为ZuulFilter的应用程序的任何bean将自动安装,与@EnableZuulProxy一样,但不会自动添加任何代理过滤器。
在这种情况下,仍然通过配置“zuul.routes。*”来指定进入Zuul服务器的路由,但是没有服务发现,没有代理,所以“serviceId”和“url”设置将被忽略。例如:
zuul:
routes:
api: /api/**将“/ api / **”中的所有路径映射到Zuul过滤器链。
禁用Zuul筛选器
Spring Cloud Zuul在代理和服务器模式下默认启用了多个ZuulFilter bean。有关启用的可能过滤器,请参阅zuul过滤器包。如果要禁用它,只需设置zuul.<SimpleClassName>.<filterType>.disable=true。按照惯例,filters之后的包是Zuul过滤器类型。例如,禁用org.springframework.cloud.netflix.zuul.filters.post.SendResponseFilter设置zuul.SendResponseFilter.post.disable=true。
Polyglot支持与Sidecar
你有没有非jvm的语言你想要利用Eureka,Ribbon和配置服务器?Spring Cloud Netflix Sidecar的灵感来自于 Netflix Prana。它包含一个简单的http api来获取给定服务的所有实例(即主机和端口)。您还可以通过从Eureka获取其路由条目的嵌入式Zuul代理来代理服务调用。可以通过主机查找或通过Zuul代理访问Spring Cloud Config服务器。非jvm应用程序应该执行健康检查,以便Sidecar可以向应用程序启动或关闭时向eureka报告。
要启用Sidecar,请使用@EnableSidecar创建Spring Boot应用程序。此注释包括@EnableCircuitBreaker,@EnableDiscoveryClient和@EnableZuulProxy。在与非jvm应用程序相同的主机上运行生成的应用程序。
配置侧车将sidecar.port和sidecar.health-uri添加到application.yml。sidecar.port属性是非jvm应用程序正在侦听的端口。这是因为Sidecar可以使用Eureka正确注册该应用程序。sidecar.health-uri是一个可以在非jvm应用程序上访问的uri,它模仿Spring Boot健康指标。它应该返回一个json文档,如下所示:
{
"status":"UP"
}以下是Sidecar应用程序的application.yml示例:
server:
port: 5678
spring:
application:
name: sidecar
sidecar:
port: 8000
health-uri: http://localhost:8000/health.jsonDiscoveryClient.getInstances()方法的api为/hosts/{serviceId}。以下是针对不同主机返回两个实例的/hosts/customers的示例响应。这个api可以通过http://localhost:5678/hosts/{serviceId}访问非jvm应用程序(如果sidecar在端口5678)。
[
{
"host": "myhost",
"port": 9000,
"uri": "http://myhost:9000",
"serviceId": "CUSTOMERS",
"secure": false
},
{
"host": "myhost2",
"port": 9000,
"uri": "http://myhost2:9000",
"serviceId": "CUSTOMERS",
"secure": false
}
]Zuul代理自动将eureka中已知的每个服务的路由添加到/<serviceId>,因此客户服务可在/customers获得。非jvm应用程序可以通过http://localhost:5678/customers访问客户服务(假设侧面正在侦听端口5678)。
如果配置服务器注册了Eureka,则非jvm应用程序可以通过Zuul代理访问它。如果ConfigServer的serviceId为configserver,Sidecar为5678端口,则可以在
http:// localhost:5678 / configserver
非jvm应用程序可以利用Config Server返回YAML文档的功能。例如,调用http://sidecar.local.spring.io:5678/configserver/default-master.yml 可能会导致一个YAML文档,如下所示
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
password: password
info:
description: Spring Cloud Samples
url: https://github.com/spring-cloud-samplesRxJava与Spring MVC
Spring Cloud Netflix包括RxJava。
RxJava是Reactive Extensions的Java VM实现:用于通过使用observable序列来构建异步和基于事件的程序的库。
Spring Cloud Netflix支持从Spring MVC控制器返回rx.Single对象。它还支持对服务器发送事件(SSE)使用rx.Observable对象。如果您的内部API已经使用RxJava构建(参见Feign Hystrix支持示例),这可能非常方便。
以下是使用rx.Single的一些示例:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single<String> single() {
return Single.just("single value");
}
@RequestMapping(method = RequestMethod.GET, value = "/singleWithResponse")
public ResponseEntity<Single<String>> singleWithResponse() {
return new ResponseEntity<>(Single.just("single value"),
HttpStatus.NOT_FOUND);
}
@RequestMapping(method = RequestMethod.GET, value = "/singleCreatedWithResponse")
public Single<ResponseEntity<String>> singleOuterWithResponse() {
return Single.just(new ResponseEntity<>("single value", HttpStatus.CREATED));
}
@RequestMapping(method = RequestMethod.GET, value = "/throw")
public Single<Object> error() {
return Single.error(new RuntimeException("Unexpected"));
}如果您有Observable而不是单个,则可以使用.toSingle()或.toList().toSingle()。这里有些例子:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single<String> single() {
return Observable.just("single value").toSingle();
}
@RequestMapping(method = RequestMethod.GET, value = "/multiple")
public Single<List<String>> multiple() {
return Observable.just("multiple", "values").toList().toSingle();
}
@RequestMapping(method = RequestMethod.GET, value = "/responseWithObservable")
public ResponseEntity<Single<String>> responseWithObservable() {
Observable<String> observable = Observable.just("single value");
HttpHeaders headers = new HttpHeaders();
headers.setContentType(APPLICATION_JSON_UTF8);
return new ResponseEntity<>(observable.toSingle(), headers, HttpStatus.CREATED);
}
@RequestMapping(method = RequestMethod.GET, value = "/timeout")
public Observable<String> timeout() {
return Observable.timer(1, TimeUnit.MINUTES).map(new Func1<Long, String>() {
@Override
public String call(Long aLong) {
return "single value";
}
});
}如果您有流式端点和客户端,SSE可以是一个选项。要将rx.Observable转换为Spring SseEmitter,请使用RxResponse.sse()。这里有些例子:
@RequestMapping(method = RequestMethod.GET, value = "/sse")
public SseEmitter single() {
return RxResponse.sse(Observable.just("single value"));
}
@RequestMapping(method = RequestMethod.GET, value = "/messages")
public SseEmitter messages() {
return RxResponse.sse(Observable.just("message 1", "message 2", "message 3"));
}
@RequestMapping(method = RequestMethod.GET, value = "/events")
public SseEmitter event() {
return RxResponse.sse(APPLICATION_JSON_UTF8, Observable.just(
new EventDto("Spring io", getDate(2016, 5, 19)),
new EventDto("SpringOnePlatform", getDate(2016, 8, 1))
));
}指标:Spectator,Servo和Atlas
当一起使用时,Spectator / Servo和Atlas提供了近实时操作洞察平台。
Spectator和Servo是Netflix的指标收集库。Atlas是用于管理维度时间序列数据的Netflix指标后端。
Servo为Netflix服务了几年,仍然可以使用,但逐渐被淘汰出来,赞成Spectator,它只适用于Java 8. Spring Cloud Netflix为两者提供了支持,但Java鼓励使用基于8的应用程序来使用Spectator。
维度与层次度量
Spring Boot Actuator指标是层次结构,指标只能由名称分隔。这些名称通常遵循将密钥/值属性对(维)嵌入到以句点分隔的名称中的命名约定。考虑以下两个端点(root和star-star)的指标:
{
"counter.status.200.root": 20,
"counter.status.400.root": 3,
"counter.status.200.star-star": 5,
}第一个指标给出了每单位时间内针对根端点的成功请求的归一化计数。但是如果系统有20个端点,并且想要获得针对所有端点的成功请求计数呢?一些分层度量后端将允许您指定一个通配符,例如counter.status.200. ,它将读取所有20个指标并聚合结果。或者,您可以提供HandlerInterceptorAdapter拦截并记录所有成功请求的counter.status.200.all等指标,而不考虑端点,但现在您必须写入20 + 1个不同的指标。类似地,如果您想知道服务中所有端点成功请求的总数,您可以指定一个通配符,例如counter.status.2 .*。
即使在分级度量后端的通配符支持的情况下,命名一致性也是困难的。具体来说,这些标签在名称字符串中的位置可能会随着时间而滑落,从而导致查询错 例如,假设我们为上述HTTP方法添加了一个额外的维度。那么counter.status.200.root成为counter.status.200.method.get.root等等。我们的counter.status.200.*突然不再具有相同的语义。此外,如果新的维度在整个代码库中不均匀地应用,某些查询可能会变得不可能。这可以很快失控。
Netflix指标被标记(又称维度)。每个指标都有一个名称,但是这个单一的命名度量可以包含多个统计信息和“标签”键/值对,这允许更多的查询灵活性。实际上统计本身就是记录在一个特殊的标签上。
使用Netflix Servo或Spectator记录,上述根端点的计时器包含每个状态码的4个统计信息,其中计数统计信息与Spring Boot Actuator计数器相同。如果到目前为止,我们遇到了HTTP 200和400,将有8个可用数据点:
{
"root(status=200,stastic=count)": 20,
"root(status=200,stastic=max)": 0.7265630630000001,
"root(status=200,stastic=totalOfSquares)": 0.04759702862580789,
"root(status=200,stastic=totalTime)": 0.2093076914666667,
"root(status=400,stastic=count)": 1,
"root(status=400,stastic=max)": 0,
"root(status=400,stastic=totalOfSquares)": 0,
"root(status=400,stastic=totalTime)": 0,
}默认度量集合
没有任何额外的依赖或配置,基于Spring Cloud的服务将自动配置Servo MonitorRegistry,并开始收集每个Spring MVC请求的指标。默认情况下,将为每个MVC请求记录名称为rest的Servo定时器,其中标记为:
-
HTTP方法
-
HTTP状态(例如200,400,500)
-
URI(如果URI为空,则为“root”),为Atlas
-
异常类名称,如果请求处理程序抛出异常
-
如果在请求上设置了匹配
netflix.metrics.rest.callerHeader的密钥的请求头,则呼叫者。netflix.metrics.rest.callerHeader没有默认键。如果您希望收集来电者信息,则必须将其添加到应用程序属性中。
设置netflix.metrics.rest.metricName属性可将度量值的名称从rest更改为您提供的名称。
如果Spring AOP已启用,并且org.aspectj:aspectjweaver存在于您的运行时类路径上,则Spring Cloud还将收集每个使用RestTemplate进行的客户端调用的指标。将为每个MVC请求记录名称为restclient的Servo定时器,其标记为:
-
HTTP方法
-
HTTP状态(例如200,400,500),如果响应返回为null,则为“CLIENT_ERROR”;如果在
RestTemplate方法执行期间发生IOException,则为“IO_ERROR” -
为Atlas消毒的URI
-
客户名称
指标集:Spectator
要启用Spectator指标,请包括spring-boot-starter-spectator的依赖关系:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-spectator</artifactId>
</dependency>在Spectator说明中,仪表是一个命名,打字和标记的配置,一个度量表示某个时间点给定仪表的值。Spectator米由注册表创建和控制,注册表目前有几个不同的实现。Spectator提供4米类型:计数器,计时器,量规和分配摘要。
Spring Cloud Spectator集成为您配置可注入的com.netflix.spectator.api.Registry实例。具体来说,它配置一个ServoRegistry实例,以统一REST度量标准的集合,并在Atlas API下将指标导出到Atlas后端。实际上,这意味着您的代码可能会使用Servo显示器和Spectator米的混合,并且两者都将被Spring Boot Actuator MetricReader实例占用,并且都会发送到Atlas后端。
Spectator柜台
计数器用于测量某些事件发生的速率。
// create a counter with a name and a set of tags
Counter counter = registry.counter("counterName", "tagKey1", "tagValue1", ...);
counter.increment(); // increment when an event occurs
counter.increment(10); // increment by a discrete amount计数器记录单个时间归一化统计量。
Spectator计时器
一个计时器用于测量一些事件需要多长时间。Spring Cloud自动记录Spring MVC请求和有条件RestTemplate请求的定时器,稍后可以用于创建仪表板,以获取请求相关的指标,如延迟:
image :: RequestLatency.png []
// create a timer with a name and a set of tags
Timer timer = registry.timer("timerName", "tagKey1", "tagValue1", ...);
// execute an operation and time it at the same time
T result = timer.record(() -> fooReturnsT());
// alternatively, if you must manually record the time
Long start = System.nanoTime();
T result = fooReturnsT();
timer.record(System.nanoTime() - start, TimeUnit.NANOSECONDS);计时器同时记录4个统计信息:count,max,totalOfSquares和totalTime。如果您在每次记录时间时在计数器上调用了一次increment()一次,计数统计量将始终与计数器提供的单个归一化值相匹配,因此对于单次操作,不需要单独计数和分时。
对于长时间运行的操作,Spectator提供了一个特殊的LongTaskTimer。
Spectator量规
量规用于确定一些当前值,如队列的大小或处于运行状态的线程数。由于仪表被采样,它们不提供关于这些值在样品之间如何波动的信息。
仪器的正常使用包括在初始化中使用标识符注册仪表,对要采样的对象的引用,以及基于对象获取或计算数值的功能。对对象的引用被单独传递,并且Spectator注册表将保持对该对象的弱引用。如果对象是垃圾回收,则Spectator将自动删除注册。见注 Spectator是关于潜在的内存泄漏的文件中,如果这个API被滥用。
// the registry will automatically sample this gauge periodically
registry.gauge("gaugeName", pool, Pool::numberOfRunningThreads);
// manually sample a value in code at periodic intervals -- last resort!
registry.gauge("gaugeName", Arrays.asList("tagKey1", "tagValue1", ...), 1000);Spectator分发摘要
分发摘要用于跟踪事件的分布情况。它类似于一个计时器,但更普遍的是,大小不一定是一段时间。例如,分发摘要可用于测量服务器的请求的有效载荷大小。
// the registry will automatically sample this gauge periodically
DistributionSummary ds = registry.distributionSummary("dsName", "tagKey1", "tagValue1", ...);
ds.record(request.sizeInBytes());指标集:Servo
|
警告
|
如果您的代码在Java 8上编译,请使用Spectator而不是Servo,因为Spectator注定要从长远来完全替换Servo。 |
在Servo语言中,监视器是一个命名,键入和标记的配置,而指标表示给定监视器在某个时间点的值。Servo显示器在逻辑上相当于Spectator米。Servo监视器由MonitorRegistry创建和控制。尽管有上述警告,Servo确实拥有比Spectator有米的更广泛的监视器选项。
Spring Cloud集成为您配置可注入的com.netflix.servo.MonitorRegistry实例。在Servo中创建了相应的Monitor类型后,记录数据的过程完全类似于Spectator。
创建Servo显示器
如果您使用Spring Cloud提供的Servo MonitorRegistry实例(具体来说是DefaultMonitorRegistry的实例),则Servo为检索计数器和计时器提供便利类。这些便利类确保每个唯一的名称和标签组合只注册一个Monitor。
要在Servo中手动创建监视器类型,特别是对于不提供方便方法的异域监视器类型,通过提供MonitorConfig实例来实例化适当的类型:
MonitorConfig config = MonitorConfig.builder("timerName").withTag("tagKey1", "tagValue1").build();
// somewhere we should cache this Monitor by MonitorConfig
Timer timer = new BasicTimer(config);
monitorRegistry.register(timer);指标后端:Atlas
Atlas由Netflix开发,用于管理尺寸时间序列数据,以实现近实时操作洞察。Atlas具有内存数据存储功能,可以非常快速地收集和报告大量的指标。
Atlas捕获操作情报。而商业智能是收集的数据,用于分析一段时间内的趋势,操作情报提供了系统中目前发生的情况。
Spring Cloud提供了一个spring-cloud-starter-atlas,它具有您需要的所有依赖项。然后,使用@EnableAtlas注释您的Spring Boot应用程序,并为运行中的Atlas服务器提供netflix.atlas.uri属性的位置。
全球标签
您可以通过Spring Cloud向发送到Atlas后端的每个度量标准添加标签。全局标签可用于按应用程序名称,环境,区域等分隔度量。
实现AtlasTagProvider的每个bean将贡献全局标签列表:
@Bean
AtlasTagProvider atlasCommonTags(
@Value("${spring.application.name}") String appName) {
return () -> Collections.singletonMap("app", appName);
}使用Atlas
引导内存独立的Atlas实例:
$ curl -LO https://github.com/Netflix/atlas/releases/download/v1.4.2/atlas-1.4.2-standalone.jar
$ java -jar atlas-1.4.2-standalone.jar|
提示
|
运行在r3.2xlarge(61GB RAM)上的Atlas独立节点可以在给定的6小时窗口内处理每分钟大约200万个度量值。 |
一旦运行并收集了少量指标,请通过在Atlas服务器上列出代码来验证您的设置是否正确:
$ curl http://ATLAS/api/v1/tags|
提示
|
在针对您的服务执行多个请求后,您可以通过在浏览器中粘贴以下URL来收集关于每个请求的请求延迟的一些非常基本的信息:http://ATLAS/api/v1/graph?q=name,rest,:eq,:avg
|
Atlas wiki包含各种场景样本查询的汇编。
Spring Cloud Stream
本节将详细介绍如何使用Spring Cloud Stream。它涵盖了创建和运行流应用程序等主题。
介绍Spring Cloud Stream
Spring Cloud Stream是构建消息驱动的微服务应用程序的框架。Spring Cloud Stream基于Spring Boot建立独立的生产级Spring应用程序,并使用Spring Integration提供与消息代理的连接。它提供了来自几家供应商的中间件的意见配置,介绍了持久发布订阅语义,消费者组和分区的概念。
您可以将@EnableBinding注释添加到应用程序中,以便立即连接到消息代理,并且可以将@StreamListener添加到方法中,以使其接收流处理事件。以下是接收外部消息的简单接收器应用程序。
@SpringBootApplication
public class StreamApplication {
public static void main(String[] args) {
SpringApplication.run(StreamApplication.class, args);
}
}
@EnableBinding(Sink.class)
public class TimerSource {
...
@StreamListener(Sink.INPUT)
public void processVote(Vote vote) {
votingService.recordVote(vote);
}
}@EnableBinding注释需要一个或多个接口作为参数(在这种情况下,参数是单个Sink接口)。接口声明输入和/或输出通道。Spring Cloud Stream提供了接口Source,Sink和Processor; 您还可以定义自己的界面。
以下是Source接口的定义:
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}@Input注释标识输入通道,通过该输入通道接收到的消息进入应用程序; @Output注释标识一个输出通道,发布的消息将通过该通道离开应用程序。@Input和@Output注释可以使用频道名称作为参数; 如果未提供名称,将使用注释方法的名称。
Spring Cloud Stream将为您创建一个界面的实现。您可以在应用程序中通过自动连接来使用它,如下面的测试用例示例。
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = StreamApplication.class)
@WebAppConfiguration
@DirtiesContext
public class StreamApplicationTests {
@Autowired
private Sink sink;
@Test
public void contextLoads() {
assertNotNull(this.sink.input());
}
}主要概念
Spring Cloud Stream提供了一些简化了消息驱动的微服务应用程序编写的抽象和原语。本节概述了以下内容:
-
Spring Cloud Stream的应用模式
-
Binder抽象
-
持续的发布 - 订阅支持
-
消费者群体支持
-
分区支持
-
一个可插拔的Binder API
应用模型
一个Spring Cloud Stream应用程序由一个中间件中立的核心组成。应用程序通过Spring Cloud Stream注入到其中的输入和输出通道与外部世界进行通信。渠道通过中间件特定的Binder实现连接到外部经纪人。
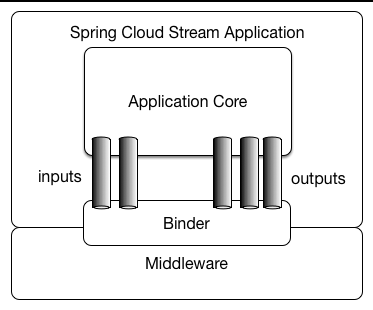
胖JAR
Spring Cloud Stream应用程序可以在IDE中以独立模式运行,用于测试。要在生产中运行Spring Cloud Stream应用程序,您可以使用为Maven或Gradle提供的标准Spring Boot工具创建可执行文件(或“胖”)JAR。
Binder抽象
Spring Cloud Stream为Kafka,Rabbit MQ,Redis和Gemfire提供Binder 实现。Spring Cloud Stream还包括一个TestSupportBinder,它保留了一个未修改的通道,以便测试可以直接和可靠地与通道进行交互。您可以使用可扩展API来编写自己的Binder。
Spring Cloud Stream使用Spring Boot进行配置,Binder抽象使得Spring Cloud Stream应用程序可以灵活地连接到中间件。例如,部署者可以在运行时动态选择通道连接到的目的地(例如,Kafka主题或RabbitMQ交换机)。可以通过外部配置属性和Spring Boot(包括应用程序参数,环境变量和application.yml或application.properties文件)支持的任何形式提供此类配置。在介绍Spring Cloud Stream部分的接收器示例中,将应用程序属性spring.cloud.stream.bindings.input.destination设置为raw-sensor-data将使其从raw-sensor-data Kafka主题或从绑定到raw-sensor-data RabbitMQ交换。
Spring Cloud Stream自动检测并使用类路径中找到的绑定。您可以使用相同的代码轻松使用不同类型的中间件:在构建时只包含不同的绑定器。对于更复杂的用例,您还可以在应用程序中打包多个绑定器,并在运行时选择绑定器,甚至是否为不同的通道使用不同的绑定器。
持续发布 - 订阅支持
应用之间的通信遵循发布订阅模式,其中通过共享主题广播数据。这可以在下图中看出,它显示了一组交互式Spring Cloud Stream应用程序的典型部署。
传感器向HTTP端点报告的数据将发送到名为raw-sensor-data的公共目标。从目的地,它由微服务应用程序独立处理,该应用程序计算时间窗口平均值,以及另一个将原始数据导入HDFS的微服务应用程序。为了处理数据,两个应用程序在运行时将主题声明为它们的输入。
发布订阅通信模型降低了生产者和消费者的复杂性,并允许将新应用程序添加到拓扑中,而不会中断现有流。例如,在平均计算应用程序的下游,您可以添加一个计算显示和监视的最高温度值的应用程序。然后,您可以添加另一个解释相同的故障检测平均流程的应用程序。通过共享主题而不是点对点队列进行所有通信可以减少微服务之间的耦合。
虽然发布订阅消息传递的概念不是新的,但是Spring Cloud Stream需要采取额外的步骤,使其成为其应用模型的有意义的选择。通过使用本地中间件支持,Spring Cloud Stream还简化了跨不同平台使用发布订阅模型。
消费群体
虽然发布订阅模型可以轻松地通过共享主题连接应用程序,但通过创建给定应用程序的多个实例来扩展的能力同样重要。当这样做时,应用程序的不同实例被放置在竞争的消费者关系中,其中只有一个实例预期处理给定消息。
Spring Cloud Stream通过消费者群体的概念来模拟这种行为。(Spring Cloud Stream消费者组与Kafka消费者组相似并受到启发)。每个使用者绑定可以使用spring.cloud.stream.bindings.input.group属性来指定组名称。对于下图所示的消费者,此属性将设置为spring.cloud.stream.bindings.input.group=hdfsWrite或spring.cloud.stream.bindings.input.group=average。
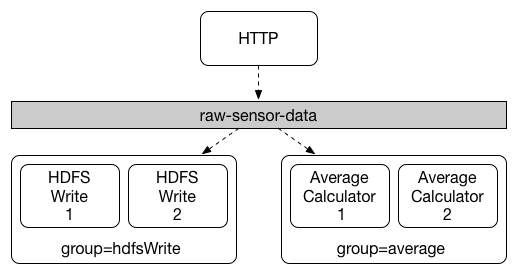
订阅给定目标的所有组都会收到已发布数据的副本,但每个组中只有一个成员从该目的地接收给定的消息。默认情况下,当未指定组时,Spring Cloud Stream将应用程序分配给与所有其他消费者组发布 - 订阅关系的匿名且独立的单个成员消费者组。
耐久力
与Spring Cloud Stream的舆论应用模式一致,消费者群体订阅是持久的。也就是说,绑定实现确保组预订是持久的,一旦已经创建了一个组的至少一个订阅,即使组中的所有应用程序都被停止,组也将接收消息。
|
注意
|
匿名订阅本质上是不耐用的。对于某些绑定实现(例如,RabbitMQ),可以具有非持久组的订阅。 |
通常,当将应用绑定到给定目的地时,最好始终指定消费者组。在扩展Spring Cloud Stream应用程序时,必须为其每个输入绑定指定使用者组。这样可以防止应用程序的实例收到重复的消息(除非需要这种行为,这是不寻常的)。
分区支持
Spring Cloud Stream提供对给定应用程序的多个实例之间的分区数据的支持。在分区场景中,物理通信介质(例如,代理主题)被视为被构造成多个分区。一个或多个生产者应用程序实例将数据发送到多个消费者应用程序实例,并确保由共同特征标识的数据由相同的消费者实例处理。
Spring Cloud Stream提供了统一方式实现分区处理用例的通用抽象。因此,无论代理本身是否自然分区(例如,Kafka)(例如,RabbitMQ),分区都可以使用。
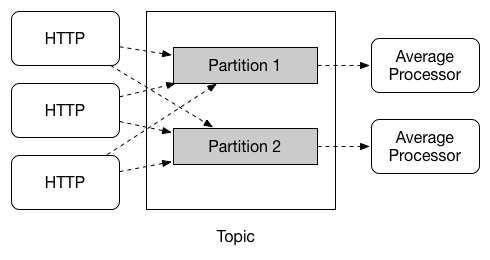
分区是状态处理中的一个关键概念,无论是性能还是一致性原因,它都是批评性的,以确保所有相关数据一起处理。例如,在时间平均计算示例中,重要的是所有给定传感器的所有测量都由相同的应用实例进行处理。
|
注意
|
要设置分区处理方案,您必须同时配置数据生成和数据消耗结束。 |
编程模型
本节介绍Spring Cloud Stream的编程模型。Spring Cloud Stream提供了许多预定义的注释,用于声明绑定的输入和输出通道以及如何收听频道。
声明和绑定频道
触发绑定@EnableBinding
您可以将Spring应用程序转换为Spring Cloud Stream应用程序,将@EnableBinding注释应用于应用程序的配置类之一。@EnableBinding注释本身使用@Configuration进行元注释,并触发Spring Cloud Stream基础架构的配置:
...
@Import(...)
@Configuration
@EnableIntegration
public @interface EnableBinding {
...
Class<?>[] value() default {};
}@EnableBinding注释可以作为参数的一个或多个接口类,其中包含表示可绑定组件(通常是消息通道)的方法。
|
注意
|
在Spring Cloud Stream 1.0中,唯一支持的可绑定组件是Spring消息传递 |
@Input和@Output
Spring Cloud Stream应用程序可以在接口中定义任意数量的输入和输出通道为@Input和@Output方法:
public interface Barista {
@Input
SubscribableChannel orders();
@Output
MessageChannel hotDrinks();
@Output
MessageChannel coldDrinks();
}使用此接口作为@EnableBinding的参数将分别触发三个绑定通道,分别命名为orders,hotDrinks和coldDrinks。
@EnableBinding(Barista.class)
public class CafeConfiguration {
...
}自定义频道名称
您可以使用@Input和@Output注释指定频道的自定义频道名称,如以下示例所示:
public interface Barista {
...
@Input("inboundOrders")
SubscribableChannel orders();
}在这个例子中,创建的绑定通道将被命名为inboundOrders。
Source,Sink和Processor
为了方便寻址最常见的用例,涉及输入通道,输出通道或两者,Spring Cloud Stream提供了三个预定义的开箱即用的接口。
Source可用于具有单个出站通道的应用程序。
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}Sink可用于具有单个入站通道的应用程序。
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}Processor可用于具有入站通道和出站通道的应用程序。
public interface Processor extends Source, Sink {
}对于任何这些接口,Spring Cloud Stream不提供特殊处理; 它们只是开箱即用。
访问绑定通道
注入绑定界面
对于每个绑定接口,Spring Cloud Stream将生成一个实现该接口的bean。调用其中一个bean的@Input注释或@Output注释方法将返回相关的绑定通道。
以下示例中的bean在调用其hello方法时在输出通道上发送消息。它在注入的Source bean上调用output()来检索目标通道。
@Component
public class SendingBean {
private Source source;
@Autowired
public SendingBean(Source source) {
this.source = source;
}
public void sayHello(String name) {
source.output().send(MessageBuilder.withPayload(body).build());
}
}直接注入渠道
绑定通道也可以直接注入:
@Component
public class SendingBean {
private MessageChannel output;
@Autowired
public SendingBean(MessageChannel output) {
this.output = output;
}
public void sayHello(String name) {
output.send(MessageBuilder.withPayload(body).build());
}
}如果在声明注释上定制了通道的名称,则应使用该名称而不是方法名称。给出以下声明:
public interface CustomSource {
...
@Output("customOutput")
MessageChannel output();
}通道将被注入,如下例所示:
@Component
public class SendingBean {
@Autowired
private MessageChannel output;
@Autowired @Qualifier("customOutput")
public SendingBean(MessageChannel output) {
this.output = output;
}
public void sayHello(String name) {
customOutput.send(MessageBuilder.withPayload(body).build());
}
}生产和消费消息
您可以使用Spring Integration注释或Spring Cloud Stream的@StreamListener注释编写Spring Cloud Stream应用程序。@StreamListener注释在其他Spring消息传递注释(例如@MessageMapping,@JmsListener,@RabbitListener等)之后建模,但添加了内容类型管理和类型强制功能。
本地Spring Integration支持
因为Spring Cloud Stream基于Spring Integration,Stream完全继承了Integration的基础和基础设施以及组件本身。例如,您可以将Source的输出通道附加到MessageSource:
@EnableBinding(Source.class)
public class TimerSource {
@Value("${format}")
private String format;
@Bean
@InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = "${fixedDelay}", maxMessagesPerPoll = "1"))
public MessageSource<String> timerMessageSource() {
return () -> new GenericMessage<>(new SimpleDateFormat(format).format(new Date()));
}
}或者您可以在变压器中使用处理器的通道:
@EnableBinding(Processor.class)
public class TransformProcessor {
@Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.OUTPUT)
public Object transform(String message) {
return message.toUpper();
}
}使用@StreamListener进行自动内容类型处理
在Spring Integration支持之外,Spring Cloud Stream提供自己的@StreamListener注释,在其他Spring消息传递注释(例如@MessageMapping,@JmsListener,@RabbitListener等)之后建模。 )。@StreamListener注释提供了一种更简单的处理入站邮件的模型,特别是在处理涉及内容类型管理和类型强制的用例时。
Spring Cloud Stream提供了一种可扩展的MessageConverter机制,用于通过绑定的通道处理数据转换,在这种情况下,将派生到使用@StreamListener注释的方法。以下是处理外部Vote事件的应用程序的示例:
@EnableBinding(Sink.class)
public class VoteHandler {
@Autowired
VotingService votingService;
@StreamListener(Sink.INPUT)
public void handle(Vote vote) {
votingService.record(vote);
}
}当考虑具有String有效载荷和contentType标题application/json的入站Message时,可以看出@StreamListener和Spring Integration @ServiceActivator之间的区别。在@StreamListener的情况下,MessageConverter机制将使用contentType标头将String有效载荷解析为Vote对象。
与其他Spring消息传递方法一样,方法参数可以用@Payload,@Headers和@Header注释。
|
注意
|
对于返回数据的方法,必须使用 |
|
注意
|
在RabbitMQ的情况下,内容类型头可以由外部应用程序设置。Spring Cloud Stream支持它们作为扩展内部协议的一部分,用于任何类型的传输(包括通常不支持头文件的传输(例如Kafka))。 |
聚合
Spring Cloud Stream支持将多个应用程序聚合在一起,直接连接其输入和输出通道,并避免通过代理交换消息的额外成本。从版本1.0的Spring Cloud Stream开始,仅对以下类型的应用程序支持聚合:
-
来源 - 具有名为
output的单个输出通道的应用程序,通常具有类型为org.springframework.cloud.stream.messaging.Source的单个绑定 -
接收器 - 具有名为
input的单个输入通道的应用程序,通常具有类型为org.springframework.cloud.stream.messaging.Sink的单个绑定 -
处理器 - 具有名为
input的单个输入通道和名为output的单个输出通道的应用程序,通常具有类型为org.springframework.cloud.stream.messaging.Processor的单个绑定。
它们可以通过创建一系列互连的应用程序来聚合在一起,其中序列中的元素的输出通道连接到下一个元素的输入通道(如果存在)。序列可以从源或处理器开始,它可以包含任意数量的处理器,并且必须以处理器或接收器结束。
根据起始和结束元素的性质,序列可以具有一个或多个可绑定的信道,如下所示:
-
如果序列从源头开始并以sink结束,则应用程序之间的所有通信都是直接的,并且不会绑定任何通道
-
如果序列以处理器开始,则其输入通道将成为聚合的
input通道,并将相应地进行绑定 -
如果序列以处理器结束,则其输出通道将成为聚合的
output通道,并将相应地进行绑定
使用AggregateApplicationBuilder实用程序类执行聚合,如以下示例所示。我们考虑一个项目,我们有源,处理器和汇点,可以在项目中定义,或者可以包含在项目的依赖之一中。
@SpringBootApplication
@EnableBinding(Sink.class)
public class SinkApplication {
private static Logger logger = LoggerFactory.getLogger(SinkModuleDefinition.class);
@ServiceActivator(inputChannel=Sink.INPUT)
public void loggerSink(Object payload) {
logger.info("Received: " + payload);
}
}@SpringBootApplication
@EnableBinding(Processor.class)
public class ProcessorApplication {
@Transformer
public String loggerSink(String payload) {
return payload.toUpperCase();
}
}@SpringBootApplication
@EnableBinding(Source.class)
public class SourceApplication {
@Bean
@InboundChannelAdapter(value = Source.OUTPUT)
public String timerMessageSource() {
return new SimpleDateFormat().format(new Date());
}
}每个配置可以用于运行一个单独的组件,但在这种情况下,它们可以聚合在一起,如下所示:
@SpringBootApplication
public class SampleAggregateApplication {
public static void main(String[] args) {
new AggregateApplicationBuilder()
.from(SourceApplication.class).args("--fixedDelay=5000")
.via(ProcessorApplication.class)
.to(SinkApplication.class).args("--debug=true").run(args);
}
}该序列的起始组件作为from()方法的参数提供。序列的结尾部分作为to()方法的参数提供。中间处理器作为via()方法的参数提供。同一类型的多个处理器可以一起链接(例如,用于具有不同配置的流水线转换)。对于每个组件,构建器可以为Spring Boot配置提供运行时参数。
RxJava支持
Spring Cloud Stream通过spring-cloud-stream-rxjava中提供的RxJavaProcessor提供对基于RxJava的处理器的支持。
public interface RxJavaProcessor<I, O> {
Observable<O> process(Observable<I> input);
}RxJavaProcessor的实现将接收Observable作为表示入站消息有效载荷流的输入。启动时会调用process方法设置数据流。
您可以使用基于RxJava的处理器,并使用@EnableRxJavaProcessor注释在处理器应用程序中使用它们。@EnableRxJavaProcessor使用@EnableBinding(Processor.class)进行元注释,并创建Processor绑定。以下是基于RxJava的处理器的示例:
@EnableRxJavaProcessor
public class RxJavaTransformer {
private static Logger logger = LoggerFactory.getLogger(RxJavaTransformer.class);
@Bean
public RxJavaProcessor<String,String> processor() {
return inputStream -> inputStream.map(data -> {
logger.info("Got data = " + data);
return data;
})
.buffer(5)
.map(data -> String.valueOf(avg(data)));
}
private static Double avg(List<String> data) {
double sum = 0;
double count = 0;
for(String d : data) {
count++;
sum += Double.valueOf(d);
}
return sum/count;
}
}|
注意
|
在实现RxJava处理器时,处理异常是处理流程的一部分。未捕获的异常将被RxJava视为错误,并将导致 |
Binders
Spring Cloud Stream提供了一个Binder抽象,用于连接到外部中间件的物理目标。本节提供有关Binder SPI,其主要组件和实现特定详细信息背后的主要概念的信息。
生产者和消费者
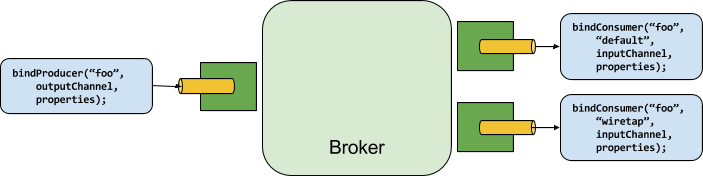
甲生产者是将消息发送到信道的任何组分。该通道可以通过该代理的Binder实现绑定到外部消息代理。当调用bindProducer()方法时,第一个参数是代理中目标的名称,第二个参数是生产者将发送消息的本地通道实例,第三个参数包含属性(如分区键表达式)在为该通道创建的适配器中使用。
甲消费者的是,从一个信道接收的消息的任何组分。与生产者一样,消费者的频道可以绑定到外部消息代理。当调用bindConsumer()方法时,第一个参数是目标名称,第二个参数提供消费者逻辑组的名称。由给定目的地的消费者绑定表示的每个组接收生产者发送到该目的地的每个消息的副本(即,发布 - 订阅语义)。如果有多个使用相同组名称的消费者实例绑定,那么消息将在这些消费者实例之间进行负载平衡,以便生产者发送的每个消息仅由每个组中的单个消费者实例消耗(即排队语义)。
Binder SPI
Binder SPI由许多接口组成,即开即用的实用程序类和发现策略,可提供连接到外部中间件的可插拔机制。
SPI的关键点是Binder接口,这是将输入和输出连接到外部中间件的策略。
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String name, T outboundBindTarget, P producerProperties);
}界面参数化,提供多个扩展点:
-
输入和输出绑定目标 - 从版本1.0开始只支持
MessageChannel,但这是打算在将来用作扩展点; -
扩展的消费者和生产者属性 - 允许特定的Binder实现来添加可以以类型安全的方式支持的补充属性。
典型的绑定实现包括以下内容
-
一个实现
Binder接口的类; -
一个Spring
@Configuration类,与中间件连接基础架构一起创建上述类型的bean; -
在类路径中找到的包含一个或多个绑定器定义的
META-INF/spring.binders文件,例如
kafka:\
org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfigurationBinder检测
Spring Cloud Stream依赖于Binder SPI的实现来执行将通道连接到消息代理的任务。每个Binder实现通常连接到一种类型的消息系统。Spring Cloud Stream开箱即用,为Kafka,RabbitMQ和Redis提供绑定。
类路径检测
默认情况下,Spring Cloud Stream依赖于Spring Boot的自动配置来配置绑定过程。如果在类路径中找到单个Binder实现,则Spring Cloud Stream将自动使用。例如,一个旨在仅绑定到RabbitMQ的Spring Cloud Stream项目可以简单地添加以下依赖关系:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>Classpath上有多个Binders
当类路径中存在多个绑定器时,应用程序必须指明每个通道绑定将使用哪个绑定器。每个binder配置包含一个META-INF/spring.binders,它是一个简单的属性文件:
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration对于其他提供的绑定实现(例如Kafka),存在类似的文件,并且预期自定义绑定实现也可以提供它们。键代表binder实现的标识名,而该值是以逗号分隔的配置类列表,每个配置类都包含唯一一个类型为org.springframework.cloud.stream.binder.Binder的bean定义。
可以通过在每个通道绑定上配置绑定器,使用spring.cloud.stream.defaultBinder属性(例如,spring.cloud.stream.defaultBinder=rabbit)或单独执行Binder选择。例如,从Kafka读取并写入RabbitMQ的处理器应用程序可以指定以下配置:
spring.cloud.stream.bindings.input.binder=kafka spring.cloud.stream.bindings.output.binder=rabbit
连接到多个系统
默认情况下,绑定器共享应用程序的Spring Boot自动配置,以便创建类路径中找到的每个绑定器的一个实例。如果您的应用程序连接到同一类型的多个代理,则可以指定多个绑定器配置,每个具有不同的环境设置。
|
注意
|
打开显式绑定器配置将完全禁用默认绑定器配置过程。如果这样做,所有使用的绑定器都必须包含在配置中。打算透明使用Spring Cloud Stream的框架可能会创建可以通过名称引用的绑定器配置,但不会影响默认的绑定器配置。为此,绑定器配置可能将其 |
例如,这是连接到两个RabbitMQ代理实例的处理器应用程序的典型配置:
spring:
cloud:
stream:
bindings:
input:
destination: foo
binder: rabbit1
output:
destination: bar
binder: rabbit2
binders:
rabbit1:
type: rabbit
environment:
spring:
rabbitmq:
host: <host1>
rabbit2:
type: rabbit
environment:
spring:
rabbitmq:
host: <host2>Binder配置属性
创建自定义绑定器配置时,以下属性可用。它们必须以spring.cloud.stream.binders.<configurationName>为前缀。
- 类型
-
粘合剂类型。它通常引用在类路径中找到的绑定器之一,特别是
META-INF/spring.binders文件中的键。默认情况下,它具有与配置名称相同的值。
- inheritEnvironment
-
配置是否会继承应用程序本身的环境。
默认
true。 - 环境
-
一组可用于自定义绑定环境的属性的根。配置此配置后,创建绑定器的上下文不是应用程序上下文的子级。这允许粘合剂组分和应用组分之间的完全分离。
默认
empty。 - defaultCandidate
-
粘合剂配置是否被认为是默认的粘合剂的候选者,或者仅在明确引用时才能使用。这允许添加binder配置,而不会干扰默认处理。
默认
true。
实施策略
本节详细介绍了Kafka和Rabbit MQ的绑定实施策略,将Spring Cloud Stream概念映射到中间件概念上的任务。
Kafka Binder
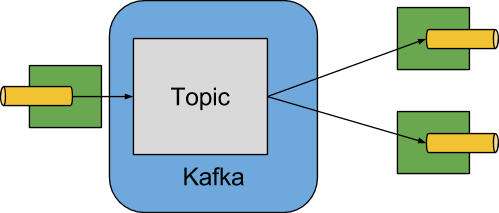
Kafka Binder实现将目的地映射到Kafka主题。消费群体直接映射到相同的Kafka概念。Spring Cloud Stream不使用高级消费者,而是为简单的消费者实现类似的概念。
RabbitMQ Binder
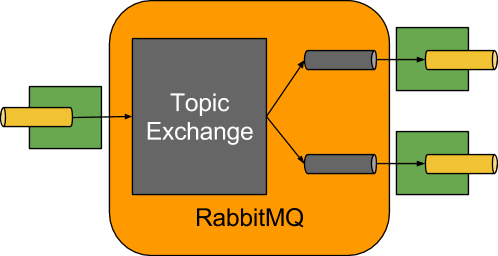
RabbitMQ Binder实现将目标映射到TopicExchange。对于每个消费群体,Queue将被绑定到TopicExchange。绑定的每个消费者实例将触发为其组的Queue创建相应的RabbitMQ Consumer实例。
配置选项
Spring Cloud Stream支持常规配置选项以及绑定和绑定器的配置。一些绑定器允许额外的绑定属性来支持中间件特定的功能。
可以通过Spring Boot支持的任何机制向Spring Cloud Stream应用程序提供配置选项。这包括应用程序参数,环境变量和YAML或.properties文件。
Spring Cloud Stream Properties
- spring.cloud.stream.instanceCount
-
应用程序部署实例的数量。必须设置分区,如果使用Kafka。
默认值:
1。 - spring.cloud.stream.instanceIndex
-
应用程序的实例索引:从
0到instanceCount-1的数字。用于分区和使用Kafka。在Cloud Foundry中自动设置以匹配应用程序的实例索引。 - spring.cloud.stream.dynamicDestinations
-
可以动态绑定的目标列表(例如,在动态路由方案中)。如果设置,只能列出目的地。
默认值:空(允许任何目的地绑定)。
- spring.cloud.stream.defaultBinder
-
如果配置了多个绑定器,则使用默认的binder。在Classpath上查看多个Binders。
默认值:空。
- spring.cloud.stream.overrideCloudConnectors
-
此属性仅适用于
cloud配置文件激活且Spring Cloud连接器随应用程序一起提供。如果属性为false(默认值),绑定器将检测适合的绑定服务(例如,RabbitMQ绑定器在Cloud Foundry中绑定的RabbitMQ服务),并将使用它来创建连接(通常通过Spring Cloud连接器)。当设置为true时,此属性指示绑定器完全忽略绑定的服务,并依赖Spring Boot属性(例如依赖于RabbitMQ绑定器环境中提供的spring.rabbitmq.*属性)。当连接到多个系统时,此属性的典型用法将嵌套在定制环境中。默认值:false。
绑定Properties
绑定属性使用格式spring.cloud.stream.bindings.<channelName>.<property>=<value>提供。<channelName>表示正在配置的通道的名称(例如Source的output)。
在下面的内容中,我们指出我们在哪里省略了spring.cloud.stream.bindings.<channelName>.前缀,并且只关注属性名称,同时理解前缀将包含在运行时。
Properties使用Spring Cloud Stream
以下绑定属性可用于输入和输出绑定,并且必须以spring.cloud.stream.bindings.<channelName>.为前缀。
- 目的地
-
绑定中间件上的通道的目标目标(例如,RabbitMQ交换机或Kafka主题)。如果通道绑定为消费者,则可以将其绑定到多个目标,并且目标名称可以指定为逗号分隔的字符串值。如果未设置,则使用通道名称。
- 组
-
渠道的消费群体。仅适用于入站绑定。参见消费者群体。
默认值:null(表示匿名消费者)。
- 内容类型
-
频道的内容类型。//参见[内容类型管理]。
默认值:null(以便不执行类型强制)。
- 粘合剂
-
这种绑定使用的粘合剂。有关详细信息,请参阅Classpath上的Multiple Binders。
默认值:null(默认的binder将被使用,如果存在)。
消费者物业
以下绑定属性仅适用于输入绑定,并且必须以spring.cloud.stream.bindings.<channelName>.consumer.为前缀。
- 并发
-
入站消费者的并发性。
默认值:
1。 - 分区
-
消费者是否从分区生产者接收数据。
默认值:
false。 - headerMode
-
设置为
raw时,禁用输入头标题解析。仅适用于不支持消息头的消息中间件,并且需要头部嵌入。入站数据来自外部Spring Cloud Stream应用程序时很有用。默认值:
embeddedHeaders。 - maxAttempts
-
重新处理入站邮件的尝试次数。
默认值:
3。 - backOffInitialInterval
-
退避初始间隔重试。
默认值:
1000。 - backOffMaxInterval
-
最大回退间隔。
默认值:
10000。 - backOffMultiplier
-
退避倍数。
默认值:
2.0。
制作人Properties
以下绑定属性仅适用于输出绑定,并且必须以spring.cloud.stream.bindings.<channelName>.producer.为前缀。
- partitionKeyExpression
-
一个确定如何分配出站数据的SpEL表达式。如果设置,或者如果设置了
partitionKeyExtractorClass,则该通道上的出站数据将被分区,并且partitionCount必须设置为大于1的值才能生效。这两个选项是相互排斥的。请参阅分区支持。默认值:null。
- partitionKeyExtractorClass
-
一个
PartitionKeyExtractorStrategy实现。如果设置,或者如果设置了partitionKeyExpression,则该通道上的出站数据将被分区,并且partitionCount必须设置为大于1的值才能生效。这两个选项是相互排斥的。请参阅分区支持。默认值:null。
- partitionSelectorClass
-
一个
PartitionSelectorStrategy实现。与partitionSelectorExpression相互排斥。如果没有设置,则分区将被选为hashCode(key) % partitionCount,其中key通过partitionKeyExpression或partitionKeyExtractorClass计算。默认值:null。
- partitionSelectorExpression
-
用于自定义分区选择的SpEL表达式。与
partitionSelectorClass相互排斥。如果没有设置,则分区将被选择为hashCode(key) % partitionCount,其中key通过partitionKeyExpression或partitionKeyExtractorClass计算。默认值:null。
- partitionCount
-
如果启用分区,则数据的目标分区数。如果生产者被分区,则必须设置为大于1的值。在Kafka,解释为提示; 而是使用更大的和目标主题的分区计数。
默认值:
1。 - requiredGroups
-
生成者必须确保消息传递的组合的逗号分隔列表,即使它们在创建之后启动(例如,通过在RabbitMQ中预先创建持久队列)。
- headerMode
-
设置为
raw时,禁用输出上的标题嵌入。仅适用于不支持消息头的消息中间件,并且需要头部嵌入。在非Spring Cloud Stream应用程序生成数据时很有用。默认值:
embeddedHeaders。
Binder - 具体配置
以下binder,consumer和producer属性特定于binder实现。
Rabbit-Specific设定
RabbitMQ Binder Properties
默认情况下,RabbitMQ绑定使用Spring Boot的ConnectionFactory,因此它支持RabbitMQ的所有Spring Boot配置选项。(有关参考,请参阅Spring Boot文档。)RabbitMQ配置选项使用spring.rabbitmq前缀。
除了Spring Boot选项之外,RabbitMQ binder还支持以下属性:
- spring.cloud.stream.rabbit.binder.adminAddresses
-
RabbitMQ管理插件网址的逗号分隔列表。仅在
nodes包含多个条目时使用。此列表中的每个条目必须在spring.rabbitmq.addresses中具有相应的条目。默认值:空。
- spring.cloud.stream.rabbit.binder.nodes
-
RabbitMQ节点名称的逗号分隔列表。当多个条目用于查找队列所在的服务器地址时。此列表中的每个条目必须在
spring.rabbitmq.addresses中具有相应的条目。默认值:空。
- spring.cloud.stream.rabbit.binder.compressionLevel
-
压缩绑定的压缩级别。见
java.util.zip.Deflater。默认值:
1(BEST_LEVEL)。
RabbitMQ消费者Properties
以下属性仅适用于Rabbit用户,必须以spring.cloud.stream.rabbit.bindings.<channelName>.consumer.为前缀。
- acknowledgeMode
-
确认模式。
默认值:
AUTO。 - autoBindDlq
-
是否自动声明DLQ并将其绑定到绑定器DLX。
默认值:
false。 - durableSubscription
-
订阅是否应该耐用。仅当
group也被设置时才有效。默认值:
true。 - maxConcurrency
-
默认值:
1。 - 预取
-
预取计数。
默认值:
1。 - 字首
-
要添加到
destination和队列名称的前缀。默认值:“”。
- recoveryInterval
-
连接恢复尝试之间的间隔,以毫秒为单位。
默认值:
5000。 - requeueRejected
-
是否应重新发送送货失败。
默认值:
true。 - requestHeaderPatterns
-
要传输的请求头。
默认值:
[STANDARD_REQUEST_HEADERS,'*']。 - replyHeaderPatterns
-
要运输的回复标题
默认值:
[STANDARD_REPLY_HEADERS,'*']。 - republishToDlq
-
默认情况下,尝试重试后失败的消息将被拒绝。如果配置了死信队列(DLQ),则RabbitMQ会将失败的消息(未更改)路由到DLQ。如果设置为
true,则总线将重新发布带有附加头的DLQ的失败消息,包括最终故障原因的异常消息和堆栈跟踪。 - 交易
-
是否使用交易渠道。
默认值:
false。 - txSize
-
阿克斯之间的交付次数。
默认值:
1。
Rabbit生产者Properties
以下属性仅适用于Rabbit生产者,必须以spring.cloud.stream.rabbit.bindings.<channelName>.producer.为前缀。
- autoBindDlq
-
是否自动声明DLQ并将其绑定到绑定器DLX。
默认值:
false。 - batchingEnabled
-
是否启用生产者的消息批处理。
默认值:
false。 - BATCHSIZE
-
批量启动时要缓冲的消息数。
默认值:
100。 - batchBufferLimit
-
默认值:
10000。 - batchTimeout
-
默认值:
5000。 - 压缩
-
发送时是否应压缩数据。
默认值:
false。 - deliveryMode
-
交货方式。
默认值:
PERSISTENT。 - 字首
-
要添加到
destination交换机名称的前缀。默认值:“”。
- requestHeaderPatterns
-
要传输的请求头。
默认值:
[STANDARD_REQUEST_HEADERS,'*']。 - replyHeaderPatterns
-
要运输的回复标题
默认值:
[STANDARD_REPLY_HEADERS,'*']。
Kafka - 具体设置
Kafka Binder Properties
- spring.cloud.stream.kafka.binder.brokers
-
Kafka活页夹连接到的经纪人列表。
默认值:
localhost。 - spring.cloud.stream.kafka.binder.defaultBrokerPort
-
brokers允许有或没有端口信息指定的主机(例如,host1,host2:port2)。当在代理列表中没有配置端口时,这将设置默认端口。默认值:
9092。 - spring.cloud.stream.kafka.binder.zkNodes
-
可以连接Kafka绑定器的ZooKeeper节点列表。
默认值:
localhost。 - spring.cloud.stream.kafka.binder.defaultZkPort
-
zkNodes允许有或没有端口信息指定的主机(例如host1,host2:port2)。当在节点列表中没有配置端口时,这将设置默认端口。默认值:
2181。 - spring.cloud.stream.kafka.binder.headers
-
将由活页夹传送的自定义标题列表。
默认值:空。
- spring.cloud.stream.kafka.binder.offsetUpdateTimeWindow
-
以毫秒为单位的频率(以毫秒为单位)保存偏移量。
0忽略。默认值:
10000。 - spring.cloud.stream.kafka.binder.offsetUpdateCount
-
频率,更新次数,哪些消耗的偏移量会持续存在。
0忽略。与offsetUpdateTimeWindow相互排斥。默认值:
0。 - spring.cloud.stream.kafka.binder.requiredAcks
-
经纪人所需的acks数量。
默认值:
1。 - spring.cloud.stream.kafka.binder.minPartitionCount
-
只有设置
autoCreateTopics或autoAddPartitions才有效。绑定器在其生成/消耗数据的主题上配置的全局最小分区数。它可以由生产者的partitionCount设置或制造商的instanceCount*concurrency设置的值替代(如果更大)。默认值:
1。 - spring.cloud.stream.kafka.binder.replicationFactor
-
如果
autoCreateTopics处于活动状态,则自动创建主题的复制因子。默认值:
1。 - spring.cloud.stream.kafka.binder.autoCreateTopics
-
如果设置为
true,则活页夹将自动创建新主题。如果设置为false,则绑定器将依赖于已配置的主题。在后一种情况下,如果主题不存在,则绑定器将无法启动。值得注意的是,此设置与代理的auto.topic.create.enable设置无关,并不影响它:如果服务器设置为自动创建主题,则可以将其创建为元数据检索请求的一部分,并使用默认代理设置。默认值:
true。 - spring.cloud.stream.kafka.binder.autoAddPartitions
-
如果设置为
true,则绑定器将根据需要创建新的分区。如果设置为false,则绑定器将依赖于已配置的主题的分区大小。如果目标主题的分区计数小于预期值,则绑定器将无法启动。默认值:
false。 - spring.cloud.stream.kafka.binder.socketBufferSize
-
Kafka消费者使用的套接字缓冲区的大小(以字节为单位)。
默认值:
2097152。
Kafka消费者Properties
以下属性仅适用于Kafka消费者,必须以spring.cloud.stream.kafka.bindings.<channelName>.consumer.为前缀。
- autoCommitOffset
-
是否在处理邮件时自动提交偏移量。如果设置为
false,则在消息头中将有一个Acknowledgment头可用于延迟确认。默认值:
true。 - autoCommitOnError
-
只有
autoCommitOffset设置为true才有效。如果设置为false,它会禁止导致错误的消息的自动提交,并且仅针对成功的消息进行提交,允许流在上次成功处理的消息中自动重播,以防持续发生故障。如果设置为true,它将始终自动提交(如果启用了自动提交)。如果没有设置(默认),它实际上具有与enableDlq相同的值,如果它们发送到DLQ,则自动提交错误消息,否则不提交错误消息。默认值:未设置。
- recoveryInterval
-
连接恢复尝试之间的间隔,以毫秒为单位。
默认值:
5000。 - resetOffsets
-
是否将消费者的偏移量重置为
startOffset提供的值。默认值:
false。 - 开始偏移
-
新组的起始偏移量,或
resetOffsets为true时。允许的值:earliest,latest。默认值:null(相当于
earliest)。 - enableDlq
-
当设置为true时,它将为消费者发送启用DLQ行为。导致错误的消息将转发到名为
error.<destination>.<group>的主题。对于错误数量相对较小并且重播整个原始主题可能太麻烦的情况,这为更常见的Kafka重播场景提供了替代选项。默认值:
false。
Kafka生产者Properties
以下属性仅适用于Kafka生产者,并且必须以spring.cloud.stream.kafka.bindings.<channelName>.producer.为前缀。
- 缓冲区大小
-
上限(以字节为单位),Kafka生产者将在发送之前尝试批量的数据量。
默认值:
16384。 - 同步
-
生产者是否是同步的
默认值:
false。 - batchTimeout
-
生产者在发送之前等待多长时间,以便允许更多消息在同一批次中累积。(通常,生产者根本不等待,并且简单地发送在先前发送进行中累积的所有消息。)非零值可能会以延迟为代价增加吞吐量。
默认值:
0。 - maxRequestSize
-
消息发送请求的最大大小。
默认值:
1048576。 - 组态
-
使用包含通用Kafka生产者属性的键/值对映射。
默认值:空地图。
内容类型和转换
要允许您传播有关所生成消息的内容类型的信息,Spring Cloud Stream默认情况下会将contentType标头附加到出站消息。对于不直接支持头文件的中间件,Spring Cloud Stream提供了自己将出站邮件自动包装在自己的信封中的机制。对于支持头文件的中间件,Spring Cloud Stream应用程序可以从非Spring Cloud Stream应用程序接收具有给定内容类型的消息。
Spring Cloud Stream可以通过两种方式处理基于此信息的消息:
-
通过其入站和出站渠道的
contentType设置 -
通过对使用
@StreamListener注释的方法执行的参数映射
Spring Cloud Stream允许您使用绑定的content-type属性声明式配置输入和输出的类型转换。请注意,一般类型转换也可以通过在应用程序中使用变压器轻松实现。目前,Spring Cloud Stream本机支持流中常用的以下类型转换:
-
来自/从POJO的JSON
-
对象到/来自byte []:用于远程传输的原始字节序列化,应用程序发出的字节,或使用Java序列化转换为字节(要求对象为Serializable)
-
字符串到/来自byte []
-
对象到纯文本(调用对象的toString()方法)
其中JSON表示包含JSON的字节数组或字符串有效负载。目前,对象可以从JSON字节数组或字符串转换。转换为JSON总是产生一个String。
MIME类型
content-type值被解析为媒体类型,例如application/json或text/plain;charset=UTF-8。MIME类型对于指示如何转换为String或byte []内容特别有用。Spring Cloud Stream还使用MIME类型格式来表示Java类型,使用具有type参数的一般类型application/x-java-object。例如,可以将application/x-java-object;type=java.util.Map或application/x-java-object;type=com.bar.Foo设置为输入绑定的content-type属性。此外,Spring Cloud Stream提供自定义MIME类型,特别是application/x-spring-tuple来指定元组。
MIME类型和Java类型
开箱即用的类型转换Spring Cloud Stream总结如下表:
| 来源有效载荷 | 目标有效载荷 | 内容类型标题 | 内容类型 | 注释 |
|---|---|---|---|---|
POJO |
JSON String |
ignored |
application/json |
|
Tuple |
JSON String |
ignored |
application/json |
JSON是为Tuple量身定制的 |
POJO |
String (toString()) |
ignored |
text/plain, java.lang.String |
|
POJO |
byte[] (java.io serialized) |
ignored |
application/x-java-serialized-object |
|
JSON byte[] or String |
POJO |
application/json (or none) |
application/x-java-object |
|
byte[] or String |
Serializable |
application/x-java-serialized-object |
application/x-java-object |
|
JSON byte[] or String |
Tuple |
application/json (or none) |
application/x-spring-tuple |
|
byte[] |
String |
any |
text/plain, java.lang.String |
将应用在content-type头中指定的任何Charset |
String |
byte[] |
any |
application/octet-stream |
将应用在content-type头中指定的任何Charset |
转换适用于需要类型转换的有效内容。例如,如果一个模块生成一个带有outputType = application / json的XML字符串,则该有效负载将不会从XML转换为JSON。这是因为模块输出通道的有效载荷已经是一个字符串,所以在运行时不会使用任何转换。
虽然输入和输出通道都支持转换,但特别推荐将其用于转发出站消息。对于入站邮件的转换,特别是当目标是POJO时,@StreamListener支持将自动执行转换。
@StreamListener和讯息转换
@StreamListener注释提供了一种方便的方式来转换传入的消息,而不需要指定输入通道的内容类型。在使用@StreamListener注释的方法的调度过程中,如果参数需要,将自动应用转换。
例如,让我们考虑一个带有{"greeting":"Hello, world"}的String内容的消息,并且在输入通道上接收到application/json的application/json标题。让我们考虑接收它的以下应用程序:
public class GreetingMessage {
String greeting;
public String getGreeting() {
return greeting;
}
public void setGreeting(String greeting) {
this.greeting = greeting;
}
}
@EnableBinding(Sink.class)
@EnableAutoConfiguration
public static class GreetingSink {
@StreamListener(Sink.INPUT)
public void receive(Greeting greeting) {
// handle Greeting
}
}该方法的参数将自动填充包含JSON字符串的未编组形式的POJO。
应用间通信
连接多个应用程序实例
虽然Spring Cloud Stream可以使个人Spring Boot应用程序轻松连接到邮件系统,但Spring Cloud Stream的典型场景是创建多应用程序管道,其中微服务应用程序将数据发送给彼此。您可以通过将相邻应用程序的输入和输出目标相关联来实现此场景。
假设设计要求时间源应用程序将数据发送到日志接收应用程序,则可以在两个应用程序中使用名为ticktock的公用目标来进行绑定。
时间源将设置以下属性:
spring.cloud.stream.bindings.output.destination=ticktock
日志接收器将设置以下属性:
spring.cloud.stream.bindings.input.destination=ticktock
实例索引和实例计数
当扩展Spring Cloud Stream应用程序时,每个实例都可以接收有关同一应用程序的其他实例数量以及自己的实例索引的信息。Spring Cloud Stream通过spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex属性执行此操作。例如,如果HDFS宿应用程序有三个实例,则所有三个实例将spring.cloud.stream.instanceCount设置为3,并且各个应用程序将spring.cloud.stream.instanceIndex设置为0,1和2。
当通过Spring Cloud数据流部署Spring Cloud Stream应用程序时,这些属性将自动配置; 当独立启动Spring Cloud Stream应用程序时,必须正确设置这些属性。默认情况下,spring.cloud.stream.instanceCount为1,spring.cloud.stream.instanceIndex为0。
在放大的情况下,正确配置这两个属性对于解决分区行为(见下文)一般很重要,并且某些绑定器(例如,Kafka绑定器)始终需要两个属性,以确保该数据在多个消费者实例之间正确分割。
分区
配置输出绑定进行分区
输出绑定配置为通过设置其唯一的一个partitionKeyExpression或partitionKeyExtractorClass属性以及其partitionCount属性来发送分区数据。例如,以下是一个有效和典型的配置:
spring.cloud.stream.bindings.output.producer.partitionKeyExpression=payload.id spring.cloud.stream.bindings.output.producer.partitionCount=5
基于上述示例配置,使用以下逻辑将数据发送到目标分区。
根据partitionKeyExpression,为发送到分区输出通道的每个消息计算分区密钥的值。partitionKeyExpression是一个Spel表达式,根据出站消息进行评估,以提取分区密钥。
|
提示
|
如果SpEL表达式不足以满足您的需要,您可以通过将属性 |
一旦计算了消息密钥,分区选择过程将确定目标分区为0和partitionCount - 1之间的值。在大多数情况下,默认计算基于公式key.hashCode() % partitionCount。这可以通过将绑定表达式设置为针对密钥(通过partitionSelectorExpression属性)进行评估)或通过设置org.springframework.cloud.stream.binder.PartitionSelectorStrategy实现(通过partitionSelectorClass属性)来进行自定义。
可以为更高级的场景配置其他属性,如以下部分所述。
|
注意
|
Kafka绑定器将使用 |
配置输入绑定进行分区
输入绑定被配置为通过在应用程序本身设置其partitioned属性以及instanceIndex和instanceCount属性来接收分区数据,如以下示例所示:
spring.cloud.stream.bindings.input.consumer.partitioned=true spring.cloud.stream.instanceIndex=3 spring.cloud.stream.instanceCount=5
instanceCount值表示数据需要分区的应用实例的总数,instanceIndex必须是0和instanceCount - 1之间的多个实例之间的唯一值。实例索引帮助每个应用程序实例识别从其接收数据的唯一分区(或在分区集合的Kafka的情况下)。重要的是正确设置两个值,以确保所有数据都被使用,并且应用程序实例接收到互斥数据集。
虽然使用多个实例进行分区数据处理的场景可能会在独立情况下进行复杂化,但是通过将输入和输出值正确填充并依赖于运行时基础架构,Spring Cloud数据流可以显着简化流程,提供有关实例索引和实例计数的信息。
测试
Spring Cloud Stream提供对测试您的微服务应用程序的支持,而无需连接到消息系统。您可以使用TestSupportBinder来做到这一点。这对于您的微服务单元测试尤其有用。
TestSupportBinder允许用户与绑定的频道进行交互,并检查应用程序发送和接收的消息
对于出站消息通道,TestSupportBinder注册单个订户,并将应用程序发出的消息保留在MessageCollector中。它们可以在测试过程中被检索,并对它们做出断言。
用户还可以将消息发送到入站消息通道,以便消费者应用程序可以使用消息。以下示例显示了如何在处理器上测试输入和输出通道。
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = ExampleTest.MyProcessor.class)
@IntegrationTest({"server.port=-1"})
@DirtiesContext
public class ExampleTest {
@Autowired
private Processor processor;
@Autowired
private BinderFactory<MessageChannel> binderFactory;
@Autowired
private MessageCollector messageCollector;
@Test
@SuppressWarnings("unchecked")
public void testWiring() {
Message<String> message = new GenericMessage<>("hello");
processor.input().send(message);
Message<String> received = (Message<String>) messageCollector.forChannel(processor.output()).poll();
assertThat(received.getPayload(), equalTo("hello world"));
}
@SpringBootApplication
@EnableBinding(Processor.class)
public static class MyProcessor {
@Autowired
private Processor channels;
@Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.OUTPUT)
public String transform(String in) {
return in + " world";
}
}
}在上面的示例中,我们正在创建一个具有输入和输出通道的应用程序,通过Processor界面绑定。绑定的接口被注入测试,所以我们可以访问这两个通道。我们在输入通道上发送消息,我们使用Spring Cloud Stream测试支持提供的MessageCollector来捕获消息已经发送到输出通道。收到消息后,我们可以验证组件是否正常工作。
健康指标
Spring Cloud Stream为粘合剂提供健康指标。它以binders的名义注册,可以通过设置management.health.binders.enabled属性启用或禁用。
样品
对于Spring Cloud Stream样本,请参考GitHub上的spring-cloud-stream-samples库。
入门
要开始创建Spring Cloud Stream应用程序,请访问Spring Initializr并创建一个名为“GreetingSource”的新Maven项目。选择Spring Boot版本1.3.4 SNAPSHOT,并搜索或勾选Stream Kafka的复选框(我们将使用Kafka进行消息传递)。
接下来,在与GreetingSourceApplication类相同的包中创建一个新类GreetingSource。给它以下代码:
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.integration.annotation.InboundChannelAdapter;
@EnableBinding(Source.class)
public class GreetingSource {
@InboundChannelAdapter(Source.OUTPUT)
public String greet() {
return "hello world " + System.currentTimeMillis();
}
}@EnableBinding注释是什么触发了Spring Integration基础架构组件的创建。具体来说,它将创建一个Kafka连接工厂,一个Kafka出站通道适配器,并在Source界面中定义消息通道:
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}自动配置还创建一个默认轮询器,以便每秒调用greet()方法一次。标准的Spring Integration @InboundChannelAdapter注释使用返回值作为消息的有效内容向源的输出通道发送消息。
要测试驱动此设置,请运行Kafka消息代理。一个简单的方法是使用Docker镜像:
# On OS X
$ docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=`docker-machine ip \`docker-machine active\`` --env ADVERTISED_PORT=9092 spotify/kafka
# On Linux
$ docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=localhost --env ADVERTISED_PORT=9092 spotify/kafka构建应用程序:
./mvnw clean package
消费者应用程序以类似的方式进行编码。返回Initializr并创建另一个名为LoggingSink的项目。然后在与类LoggingSinkApplication相同的包中创建一个新类LoggingSink,并使用以下代码:
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
@EnableBinding(Sink.class)
public class LoggingSink {
@StreamListener(Sink.INPUT)
public void log(String message) {
System.out.println(message);
}
}构建应用程序:
./mvnw clean package
要将GreetingSource应用程序连接到LoggingSink应用程序,每个应用程序必须共享相同的目标名称。启动这两个应用程序如下所示,您将看到消费者应用程序打印“hello world”和时间戳到控制台:
cd GreetingSource
java -jar target/GreetingSource-0.0.1-SNAPSHOT.jar --spring.cloud.stream.bindings.output.destination=mydest
cd LoggingSink
java -jar target/LoggingSink-0.0.1-SNAPSHOT.jar --server.port=8090 --spring.cloud.stream.bindings.input.destination=mydest(不同的服务器端口可以防止两个应用程序中用于维护Spring Boot Actuator端点的HTTP端口的冲突。)
LoggingSink应用程序的输出将如下所示:
[ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8090 (http)
[ main] com.example.LoggingSinkApplication : Started LoggingSinkApplication in 6.828 seconds (JVM running for 7.371)
hello world 1458595076731
hello world 1458595077732
hello world 1458595078733
hello world 1458595079734
hello world 1458595080735Spring Cloud Bus
快速开始
Spring Cloud Bus的工作原理是添加Spring Boot自动配置,如果它在类路径中检测到自身。所有您需要做的是启用总线是将spring-cloud-starter-bus-amqp或spring-cloud-starter-bus-kafka添加到您的依赖关系管理中,Spring Cloud负责其余部分。确保代理(RabbitMQ或Kafka)可用和配置:在本地主机上运行您不应该做任何事情,但如果您远程运行使用Spring Cloud连接器或Spring Boot约定来定义经纪人凭证,例如Rabbit
spring:
rabbitmq:
host: mybroker.com
port: 5672
username: user
password: secret
总线当前支持向所有节点发送消息,用于特定服务的所有节点(由Eureka定义)。未来可能会添加更多的选择器标准(即,仅数据中心Y中的服务X节点等)。/bus/*执行器命名空间下还有一些http端点。目前有两个实施。第一个/bus/env发送密钥/值对来更新每个节点的Spring环境。第二个/bus/refresh将重新加载每个应用程序的配置,就好像他们在/refresh端点上都被ping过。
|
注意
|
总线启动器覆盖Rabbit和Kafka,因为这是两个最常见的实现,但Spring Cloud Stream非常灵活,绑定将与spring-cloud-bus结合使用。
|
处理实例
HTTP端点接受“目的地”参数,例如“/ bus / refresh?destination = customers:9000”,其中目的地是ApplicationContext ID。如果ID由总线上的一个实例拥有,那么它将处理消息,所有其他实例将忽略它。默认情况下,Spring Boot将ContextIdApplicationContextInitializer中的ID设置为spring.application.name,活动配置文件和server.port的组合。
寻址服务的所有实例
“destination”参数用于Spring PathMatcher(路径分隔符为冒号:)以确定实例是否处理该消息。使用上面的示例,“/ bus / refresh?destination = customers:**”将针对“客户”服务的所有实例,而不管配置文件和端口设置为ApplicationContext ID。
应用程序上下文ID必须是唯一的
总线尝试消除事件两次处理,一次从原来的ApplicationEvent和一次从队列中。为此,它会检查发送应用程序上下文id,以重新显示当前的应用程序上下文ID。如果服务的多个实例具有相同的应用程序上下文id,则不会处理事件。在本地机器上运行,每个服务将在不同的端口上,这将是应用程序上下文ID的一部分。Cloud Foundry提供了区分的索引。为了确保应用程序上下文id是唯一的,请将spring.application.index设置为每个服务实例唯一的值。例如,在lattice中,在application.properties中设置spring.application.index=${INSTANCE_INDEX}(如果使用configserver,请设置bootstrap.properties)。
自定义Message Broker
Spring Cloud Bus使用
Spring Cloud Stream广播消息,以便获取消息流,只需要在类路径中包含您选择的binder实现。有专门为AMQP(RabbitMQ)和Kafka(spring-cloud-starter-bus-[amqp,kafka])的总线方便的启动器。一般来说,Spring Cloud Stream依赖于Spring Boot配置中间件的自动配置约定,因此例如可以使用spring.rabbitmq.*配置属性更改AMQP代理地址。Spring Cloud Bus在spring.cloud.bus.*中具有少量本机配置属性(例如,spring.cloud.bus.destination是使用外部中间件的主题的名称)。通常,默认值就足够了。
要更多地了解如何自定义消息代理设置,请参阅Spring Cloud Stream文档。
追踪Bus Events
可以通过设置spring.cloud.bus.trace.enabled=true来跟踪总线事件(RemoteApplicationEvent的子类)。如果这样做,那么Spring Boot TraceRepository(如果存在)将显示每个服务实例发送的所有事件和所有的ack。示例(来自/trace端点):
{
"timestamp": "2015-11-26T10:24:44.411+0000",
"info": {
"signal": "spring.cloud.bus.ack",
"type": "RefreshRemoteApplicationEvent",
"id": "c4d374b7-58ea-4928-a312-31984def293b",
"origin": "stores:8081",
"destination": "*:**"
}
},
{
"timestamp": "2015-11-26T10:24:41.864+0000",
"info": {
"signal": "spring.cloud.bus.sent",
"type": "RefreshRemoteApplicationEvent",
"id": "c4d374b7-58ea-4928-a312-31984def293b",
"origin": "customers:9000",
"destination": "*:**"
}
},
{
"timestamp": "2015-11-26T10:24:41.862+0000",
"info": {
"signal": "spring.cloud.bus.ack",
"type": "RefreshRemoteApplicationEvent",
"id": "c4d374b7-58ea-4928-a312-31984def293b",
"origin": "customers:9000",
"destination": "*:**"
}
}这个迹象表明RefreshRemoteApplicationEvent已从customers:9000广播发送到所有服务,并已被customers:9000和stores:8081收到(确认)。
为了处理信号,您可以向您的应用添加AckRemoteApplicationEvent和SentApplicationEvent类型的@EventListener(并启用跟踪)。或者您可以利用TraceRepository并从中挖掘数据。
|
注意
|
任何总线应用程序都可以跟踪ack,但有时在一个可以对数据进行更复杂查询的中央服务器中执行此操作是有用的。或者将其转发到专门的跟踪服务。 |
广播自己的Events
总线可以携带任何类型为RemoteApplicationEvent的事件,但默认传输是JSON,并且解串器需要知道哪些类型将提前使用。要注册一个新的类型,它需要在org.springframework.cloud.bus.event的子包中。您可以在自定义类上使用@JsonTypeName,也可以使用默认策略来使用类的简单名称。请注意,生产者和消费者都需要访问类定义。
Spring Cloud Sleuth
Adrian Cole,Spencer Gibb,Marcin Grzejszczak,Dave Syer
Brixton.BUILD,快照
Spring Cloud Sleuth为Spring Cloud实现分布式跟踪解决方案。
术语
Spring Cloud Sleuth借用Dapper的术语。
跨度:工作的基本单位。例如,发送RPC是一个新的跨度,以及向RPC发送响应。跨度由跨度的唯一64位ID标识,跨度是其中一部分的跟踪的另一个64位ID。跨度还具有其他数据,例如描述,时间戳记事件,键值注释(标签),导致它们的跨度的ID以及进程ID(通常是IP地址)。
跨距开始和停止,他们跟踪他们的时间信息。创建跨度后,必须在将来的某个时刻停止。
|
提示
|
启动跟踪的初始范围称为root span。该跨度的跨度id的值等于跟踪ID。
|
Trace:一组spans形成一个树状结构。例如,如果您正在运行分布式大数据存储,则可能会由put请求形成跟踪。
注释:用于及时记录事件的存在。用于定义请求的开始和停止的一些核心注释是:
-
cs - 客户端发送 - 客户端已经发出请求。此注释描绘了跨度的开始。
-
sr - 服务器接收 - 服务器端得到请求,并将开始处理它。如果从此时间戳中减去cs时间戳,则会收到网络延迟。
-
ss - 服务器发送 - 在完成请求处理后(响应发送回客户端时)注释。如果从此时间戳中减去sr时间戳,则会收到服务器端处理请求所需的时间。
-
cr - 客户端接收 - 表示跨度的结束。客户端已成功接收到服务器端的响应。如果从此时间戳中减去cs时间戳,则会收到客户端从服务器接收响应所需的整个时间。
可视化系统中的跨度和跟踪将与Zipkin注释一起查看:
一个音符的每个颜色表示跨度(7 spans - 从A到G)。如果您在笔记中有这样的信息:
Trace Id = X
Span Id = D
Client Sent这意味着,目前的跨度跟踪-ID设置为X,跨度-ID设置为ð。它也发出了 客户端发送的事件。
这样,spans的父/子关系的可视化将如下所示:
目的
在以下部分中,将考虑上述图像中的示例。
分布式跟踪Zipkin
共有7个spans。如果你去Zipkin中的痕迹,你将在第二个轨迹中看到这个数字:
但是,如果你选择一个特定的跟踪,那么你会看到4 spans:
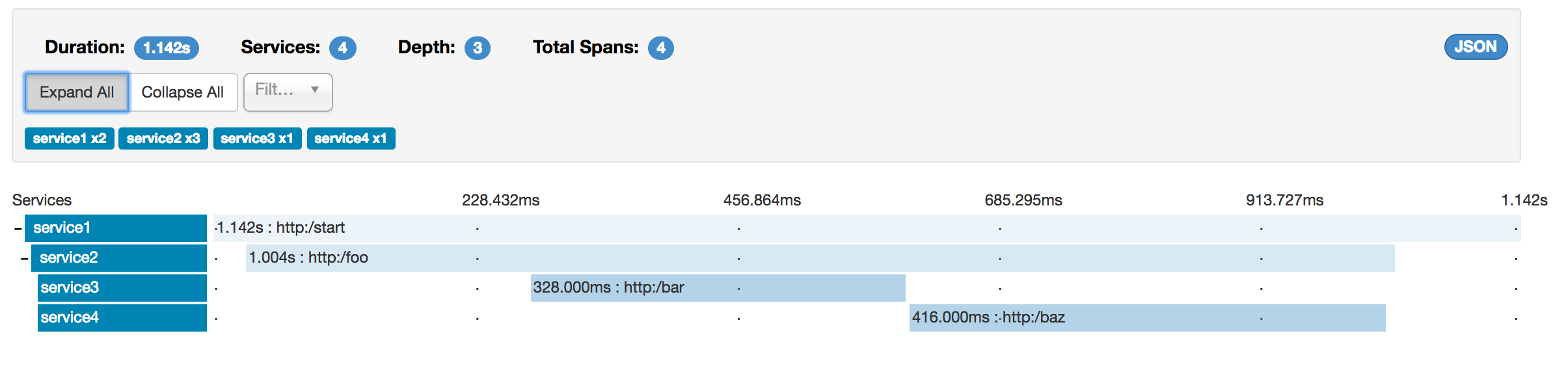
|
注意
|
当选择特定的跟踪时,您将看到合并的spans。这意味着如果发送到服务器接收和服务器发送/接收客户端和客户端发送注释的spans发送到Zipkin,那么它们将被显示为单个跨度。 |
为什么在这种情况下7和4 spans之间有区别?
-
2 spans来自
http:/start跨度。它具有服务器接收(SR)和服务器发送(SS)注释。 -
2 spans来自
service1到service2到http:/foo端点的RPC呼叫。它在service1方面具有客户端发送(CS)和客户端接收(CR)注释。它还在service2侧具有服务器接收(SR)和服务器发送(SS)注释。在物理上有2 spans,但它们形成与RPC调用相关的1个逻辑跨度。 -
2 spans来自
service2到service3到http:/bar端点的RPC呼叫。它在service2方面具有客户端发送(CS)和客户端接收(CR)注释。它还在service3端上具有服务器接收(SR)和服务器发送(SS)注释。在物理上有2 spans,但它们形成与RPC调用相关的1个逻辑跨度。 -
2 spans来自
service2到service4到http:/baz端点的RPC呼叫。它在service2方面具有客户端发送(CS)和客户端接收(CR)注释。它还在service4方面具有服务器接收(SR)和服务器发送(SS)注释。在物理上有2 spans,但它们形成与RPC调用相关的1个逻辑跨度。
因此,如果我们算上物理spans我们有1从http:/start 2从service1调用service2 2形式service2调用service3和2从service2调用service4。共7个 spans。
逻辑上,我们看到Total Spans的信息:4,因为我们有1个跨度与传入请求相关的service1和3 spans与RPC调用相关。
可视化错误
Zipkin允许您可视化跟踪中的错误。当抛出异常并且未被捕获时,我们在Zipkin可以正确着色的跨度上设置适当的标签。您可以在痕迹列表中看到一条是红色的痕迹。这是因为抛出了一个异常。
如果您点击该轨迹,您将看到类似的图片
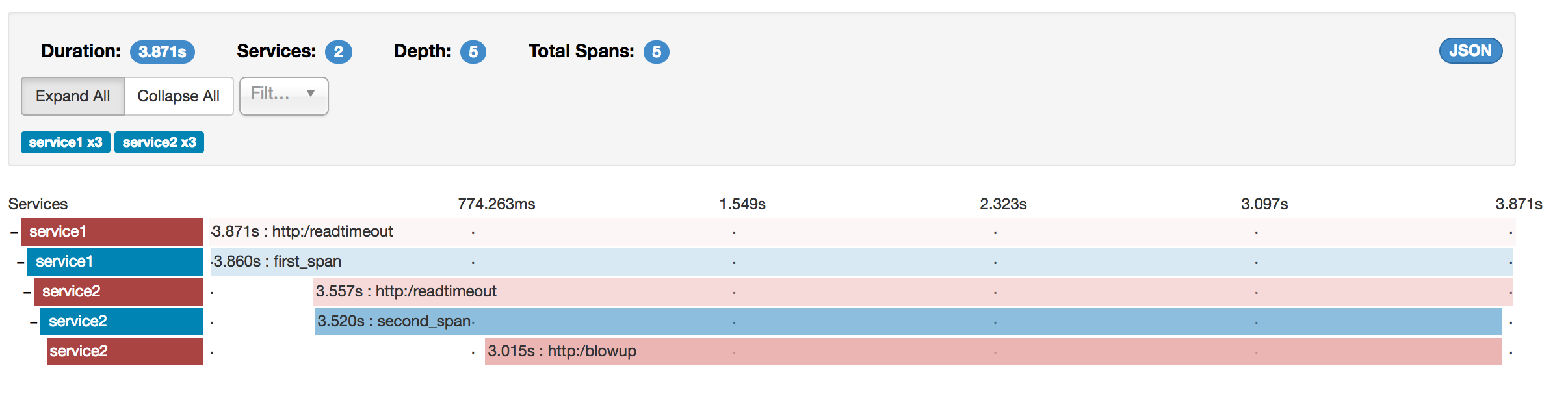
然后,如果您点击其中一个spans,您将看到以下内容
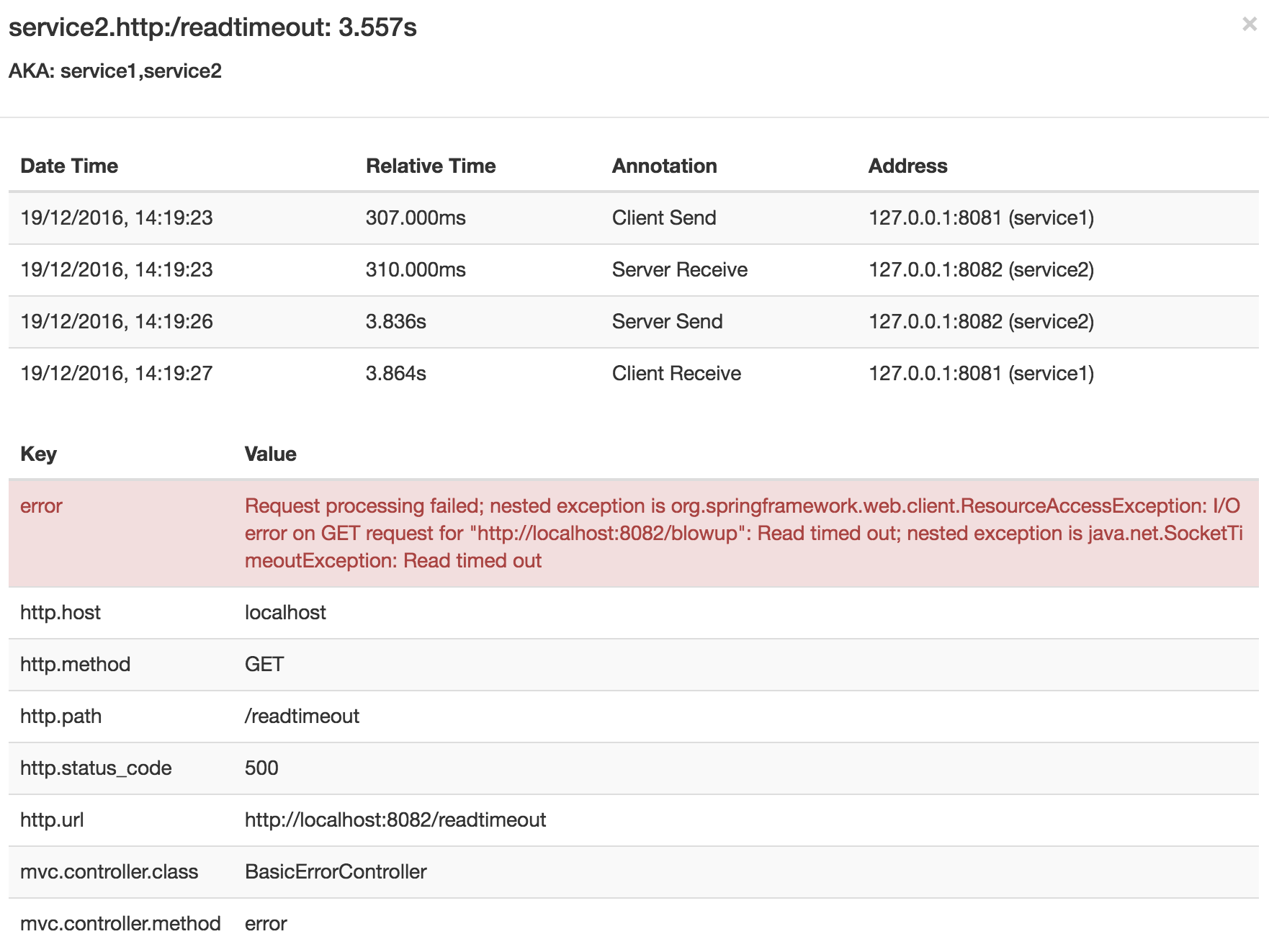
你可以看到,你可以很容易的看到错误的原因和整个stacktrace相关的。
实例

Zipkin中的依赖图将如下所示:

对数相关
当通过跟踪id等于例如2485ec27856c56f4的这四个应用程序的日志进行打印时,可以得到以下内容:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}|
注意
|
如果您想将Grok与Cloud Foundry的日志一起使用,则必须使用此模式: |
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}使用Logstash进行JSON回溯
通常,您不希望将日志存储在文本文件中,而不是将Logstash可以立即选择的JSON文件中存储。为了做到这一点,你必须做以下(为了可读性,我们传递依赖关系在groupId:artifactId:version符号。
依赖关系设置
-
确保Logback位于类路径(
ch.qos.logback:logback-core) -
添加Logstash Logback编码 - 版本
4.6的示例:net.logstash.logback:logstash-logback-encoder:4.6
回读设置
您可以在下面找到一个Logback配置(名为logback-spring.xml)的示例:
-
将来自应用程序的信息以JSON格式记录到
build/${spring.application.name}.json文件中 -
已经评论了两个额外的追加者 - 控制台和标准日志文件
-
具有与上一节所述相同的记录模式
|
注意
|
如果您使用自定义logback-spring.xml,则必须传递bootstrap spring.application.name而不是application属性文件。否则您的自定义logback文件将不会正确读取该属性。
|
添加到项目中
只有Sleuth(对数相关)
如果您只想从Spring Cloud Sleuth中获利,而Zipkin集成只需将spring-cloud-starter-sleuth模块添加到您的项目中即可。
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-starter-sleuth
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-starter-sleuth
通过HTTP访问Zipkin
如果你想要Sleuth和Zipkin只需添加spring-cloud-starter-zipkin依赖关系。
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-starter-zipkin
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-starter-zipkin
通过Spring Cloud Stream的Zipkin
如果你想要Sleuth和Zipkin只需添加spring-cloud-sleuth-stream依赖项。
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- EXAMPLE FOR RABBIT BINDING -->
<dependency> (4)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-sleuth-stream -
将依赖关系添加到
spring-cloud-starter-sleuth- 这样将依赖所有依赖关系将被下载 -
添加一个绑定器(例如Rabbit binder)来告诉Spring Cloud Stream它应该绑定到什么
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-sleuth-stream" (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth" (3)
// Example for Rabbit binding
compile "org.springframework.cloud:spring-cloud-stream-binder-rabbit" (4)
}-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-sleuth-stream -
将依赖关系添加到
spring-cloud-starter-sleuth- 这样就可以下载所有依赖关系 -
添加一个绑定器(例如Rabbit binder)来告诉Spring Cloud Stream它应该绑定到什么
Spring Cloud Sleuth流Zipkin收藏家
如果要启动Spring Cloud Sleuth Stream Zipkin收藏夹,只需添加spring-cloud-sleuth-zipkin-stream依赖关系即可
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- EXAMPLE FOR RABBIT BINDING -->
<dependency> (4)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-sleuth-zipkin-stream -
将依赖关系添加到
spring-cloud-starter-sleuth- 这样就可以下载所有依赖关系 -
添加一个绑定器(例如Rabbit binder)来告诉Spring Cloud Stream它应该绑定到什么
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-sleuth-zipkin-stream" (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth" (3)
// Example for Rabbit binding
compile "org.springframework.cloud:spring-cloud-stream-binder-rabbit" (4)
}-
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,则会更好
-
将依赖关系添加到
spring-cloud-sleuth-zipkin-stream -
将依赖关系添加到
spring-cloud-starter-sleuth中,这样就可以下载所有依赖关系 -
添加一个绑定器(例如Rabbit binder)来告诉Spring Cloud Stream它应该绑定到什么
然后使用@EnableZipkinStreamServer注释来标注你的主类:
额外的资源
Marcin Grzejszczak谈论Spring Cloud Sleuth和Zipkin
特征
-
将跟踪和跨度添加到Slf4J MDC,以便您可以从日志聚合器中的给定跟踪或跨度中提取所有日志。示例日志:
2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:30:58.372 ERROR [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ...
注意MDC中的
[appname,traceId,spanId,exportable]条目:-
spanId - 发生特定操作的ID
-
appname - 记录跨度的应用程序的名称
-
traceId - 包含跨度的延迟图的ID
-
导出 -日志是否应该被导出到Zipkin与否。你什么时候希望跨度不能出口?在这种情况下,您希望在Span中包装一些操作,并将其写入日志。
-
-
对共同的分布式跟踪数据模型提供抽象:trace,spans(形成DAG),注释,键值注释。松散地基于HTrace,但Zipkin(Dapper)兼容。
-
Sleuth记录定时信息以辅助延迟分析。使用窃贼,您可以精确定位应用程序中的延迟原因。Sleuth被写入不会记录太多,并且不会导致您的生产应用程序崩溃。
-
传播有关您的呼叫图表带内的结构数据,其余的是带外。
-
包括有意见的层次测试,如HTTP
-
包括采样策略来管理卷
-
可以向Zipkin系统报告查询和可视化
-
-
来自Spring应用程序(servlet过滤器,异步终结点,休息模板,调度操作,消息通道,zuul过滤器,假客户端)的仪器通用入口和出口点。
-
Sleuth包括在http或消息传递边界上加入跟踪的默认逻辑。例如,http传播通过Zipkin兼容的请求标头工作。该传播逻辑是通过
SpanInjector和SpanExtractor实现来定义和定制的。 -
提供接受/删除spans的简单指标。
-
如果
spring-cloud-sleuth-zipkin,则应用程序将生成并收集Zipkin兼容的跟踪。默认情况下,它通过HTTP将其发送到本地主机(端口9411)上的Zipkin服务器。使用spring.zipkin.baseUrl配置服务的位置。 -
如果
spring-cloud-sleuth-stream,则应用程序将通过Spring Cloud Stream生成和收集跟踪。您的应用程序自动成为通过您的代理商发送的跟踪消息的生成者(例如RabbitMQ,Apache Kafka,Redis))。
|
重要
|
如果使用Zipkin或Stream,请使用spring.sleuth.sampler.percentage(默认为0.1,即10%)配置spans的百分比。否则你可能认为Sleuth不工作,因为它省略了一些spans。
|
|
注意
|
始终设置SLF4J MDC,并且Logback用户将立即按照上述示例查看日志中的跟踪和跨度ID。其他日志记录系统必须配置自己的格式化程序以获得相同的结果。默认值为logging.pattern.level设置为%clr(%5p) %clr([${spring.application.name:},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]){yellow}(这是对于回溯用户的Spring Boot功能)。
这意味着如果您不使用SLF4J,则不会自动应用此模式。
|
采样
在分布式跟踪中,数据量可能非常高,因此抽样可能很重要(您通常不需要导出所有spans以获得正在发生的情况)。Spring Cloud Sleuth具有Sampler策略,您可以实现该策略来控制采样算法。采样器不会停止生成跨度(相关)ids,但是它们确实阻止了附加和导出的标签和事件。默认情况下,您将获得一个策略,如果跨度已经处于活动状态,则会继续跟踪,但新策略始终被标记为不可导出。如果您的所有应用程序都使用此采样器运行,您将看到日志中的跟踪,但不会在任何远程存储中。对于测试,默认值通常是足够的,如果您仅使用日志(例如使用ELK聚合器),则可能是您需要的。如果要将span数据导出到Zipkin或Spring Cloud Stream,还有一个AlwaysSampler导出所有内容,PercentageBasedSampler对spans的固定分数进行采样。
|
注意
|
如果您使用spring-cloud-sleuth-zipkin或spring-cloud-sleuth-stream,则PercentageBasedSampler是默认值。您可以使用spring.sleuth.sampler.percentage配置导出。通过的值需要从0.0到1.0的双倍,所以不是百分比。为了向后兼容性原因,我们不会更改属性名称。
|
可以通过创建一个bean定义来安装采样器,例如:
@Bean
public Sampler defaultSampler() {
return new AlwaysSampler();
}仪表
Spring Cloud Sleuth自动设置您的所有Spring应用程序,因此您不必执行任何操作即可激活。根据可用的堆栈,例如对于我们使用Filter的servlet Web应用程序和Spring Integration我们使用ChannelInterceptors,可以使用各种技术添加仪器。
您可以自定义span标签中使用的键。为了限制跨度数据量,默认情况下,HTTP请求只会被标记为少量的元数据,如状态码,主机和URL。您可以通过配置spring.sleuth.keys.http.headers(头名称列表)来添加请求头。
|
注意
|
请记住,如果存在Sampler允许标签(默认情况下没有,所以没有配置某些东西就不会意外收集太多数据的危险),则只会收集和导出标签。
|
|
注意
|
目前,Spring Cloud Sleuth中的工具是渴望的 - 这意味着我们正在积极地尝试在线程之间传递跟踪上下文。即使在没有将数据导出到跟踪系统的情况下,也会捕获定时事件。这种做法在将来可能会改变为在这件事上懒惰。 |
跨度生命周期
您可以通过org.springframework.cloud.sleuth.Tracer接口在Span上执行以下操作:
|
提示
|
Spring为您创建了Tracer的实例。为了使用它,你需要的只是自动连接它。
|
创建和关闭spans
您可以使用Tracer界面手动创建spans 。
// Start a span. If there was a span present in this thread it will become
// the `newSpan`'s parent.
Span newSpan = this.tracer.createSpan("calculateTax");
try {
// ...
// You can tag a span
this.tracer.addTag("taxValue", taxValue);
// ...
// You can log an event on a span
newSpan.logEvent("taxCalculated");
} finally {
// Once done remember to close the span. This will allow collecting
// the span to send it to Zipkin
this.tracer.close(newSpan);
}在这个例子中,我们可以看到如何创建一个新的跨度实例。假设这个线程中已经存在跨度,那么它将成为该跨度的父代。
|
重要
|
创建跨度后始终清洁!如果要将其发送到Zipkin,请不要忘记关闭跨度。 |
继续spans
有时你不想创建一个新的跨度,但你想继续。这种情况的例子可能是(当然这取决于用例):
-
AOP - 如果在达到方面之前已经创建了一个跨度,则可能不想创建一个新的跨度。
-
Hystrix - 执行Hystrix命令很可能是当前处理的逻辑部分。实际上,它只是一个技术实现细节,你不一定要反映在跟踪中作为一个单独的存在。
持续的跨度实例等于它继续的范围:
Span continuedSpan = this.tracer.continueSpan(spanToContinue);
assertThat(continuedSpan).isEqualTo(spanToContinue);要继续跨度,您可以使用Tracer界面。
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X
Span continuedSpan = this.tracer.continueSpan(initialSpan);
try {
// ...
// You can tag a span
this.tracer.addTag("taxValue", taxValue);
// ...
// You can log an event on a span
continuedSpan.logEvent("taxCalculated");
} finally {
// Once done remember to detach the span. That way you'll
// safely remove it from the current thread without closing it
this.tracer.detach(continuedSpan);
}|
重要
|
创建跨度后始终清洁!如果在一个线程(例如线程X)中开始了某些工作,并且正在等待其他线程(例如Y,Z)完成,请不要忘记分离跨距。那么线程Y,Z中的spans在工作结束时应该被分离。当收集结果时,螺纹X中的跨度应该被关闭。 |
用明确的父代创建spans
您可能想要开始一个新的跨度,并提供该跨度的显式父级。假设跨度的父项在一个线程中,并且要在另一个线程中启动一个新的跨度。Tracer接口的startSpan方法是您要查找的方法。
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X. `initialSpan` will be the parent
// of the `newSpan`
Span newSpan = this.tracer.createSpan("calculateCommission", initialSpan);
try {
// ...
// You can tag a span
this.tracer.addTag("commissionValue", commissionValue);
// ...
// You can log an event on a span
newSpan.logEvent("commissionCalculated");
} finally {
// Once done remember to close the span. This will allow collecting
// the span to send it to Zipkin. The tags and events set on the
// newSpan will not be present on the parent
this.tracer.close(newSpan);
}|
重要
|
创建这样一个跨度后,记得关闭它。否则,您将在您的日志中看到很多警告,其中有一个事实,即您在当前线程中存在一个跨度,而不是您要关闭的线程。更糟糕的是,您的spans不会正确关闭,因此不会收集到Zipkin。 |
命名spans
选择一个跨度名称不是一件小事。跨度名称应描述操作名称。名称应该是低基数(例如不包括标识符)。
由于有很多仪器仪表在一些跨度名称将是人为的:
-
controller-method-name当控制器收到方法名称conrollerMethodName -
async通过封装Callable和Runnable完成异步操作。 -
@Scheduled注释方法将返回类的简单名称。
幸运的是,对于异步处理,您可以提供明确的命名。
@SpanName注释
您可以通过@SpanName注释明确指定该跨度。
@SpanName("calculateTax")
class TaxCountingRunnable implements Runnable {
@Override public void run() {
// perform logic
}
}在这种情况下,以下列方式处理时:
Runnable runnable = new TraceRunnable(tracer, spanNamer, new TaxCountingRunnable());
Future<?> future = executorService.submit(runnable);
// ... some additional logic ...
future.get();该范围将命名为calculateTax。
toString()方法
为Runnable或Callable创建单独的课程很少见。通常,创建这些类的匿名实例。如果没有@SpanName注释,我们将检查该类是否具有toString()方法的自定义实现。
所以执行这样的代码:
Runnable runnable = new TraceRunnable(tracer, spanNamer, new Runnable() {
@Override public void run() {
// perform logic
}
@Override public String toString() {
return "calculateTax";
}
});
Future<?> future = executorService.submit(runnable);
// ... some additional logic ...
future.get();将导致创建一个名为calculateTax的跨度。
自定义
感谢SpanInjector和SpanExtractor,您可以自定义spans的创建和传播方式。
目前有两种在进程之间传递跟踪信息的内置方式:
-
通过Spring Integration
-
通过HTTP
从Zipkin兼容(B3)头(Message或HTTP头)中提取范围,以启动或加入现有跟踪。跟踪信息被注入到任何出站请求中,所以下一跳可以提取它们。
Spring Integration
对于Spring Integration,这些是负责从Message创建跨度并使用跟踪信息填写MessageBuilder的bean。
@Bean
public SpanExtractor<Message> messagingSpanExtractor() {
...
}
@Bean
public SpanInjector<MessageBuilder> messagingSpanInjector() {
...
}您可以通过提供自己的实现并通过在bean定义中添加@Primary注释来覆盖它们。
HTTP
对于HTTP,这些是负责从HttpServletRequest创建跨度的bean。
@Bean
public SpanExtractor<HttpServletRequest> httpServletRequestSpanExtractor() {
...
}您可以通过提供自己的实现并通过在bean定义中添加@Primary注释来覆盖它们。
例
我们假设,而不是标准的Zipkin兼容的跟踪HTTP头名称
-
for trace id -
correlationId -
for span id -
mySpanId
这是一个SpanExtractor的例子
static class CustomHttpServletRequestSpanExtractor
implements SpanExtractor<HttpServletRequest> {
@Override
public Span joinTrace(HttpServletRequest carrier) {
long traceId = Span.hexToId(carrier.getHeader("correlationId"));
long spanId = Span.hexToId(carrier.getHeader("mySpanId"));
// extract all necessary headers
Span.SpanBuilder builder = Span.builder().traceId(traceId).spanId(spanId);
// build rest of the Span
return builder.build();
}
}你可以这样注册:
@Bean
@Primary
SpanExtractor<HttpServletRequest> customHttpServletRequestSpanExtractor() {
return new CustomHttpServletRequestSpanExtractor();
}出于安全考虑,Spring Cloud Sleuth不会将跟踪/跨度相关的标头添加到Http响应。如果您需要标题,那么将标题注入Http响应的自定义SpanInjector,并且可以使用以下方法添加一个使用此标签的Servlet过滤器:
static class CustomHttpServletResponseSpanInjector
implements SpanInjector<HttpServletResponse> {
@Override
public void inject(Span span, HttpServletResponse carrier) {
carrier.addHeader(Span.TRACE_ID_NAME, span.traceIdString());
carrier.addHeader(Span.SPAN_ID_NAME, Span.idToHex(span.getSpanId()));
}
}
static class HttpResponseInjectingTraceFilter extends GenericFilterBean {
private final Tracer tracer;
private final SpanInjector<HttpServletResponse> spanInjector;
public HttpResponseInjectingTraceFilter(Tracer tracer, SpanInjector<HttpServletResponse> spanInjector) {
this.tracer = tracer;
this.spanInjector = spanInjector;
}
@Override
public void doFilter(ServletRequest request, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletResponse response = (HttpServletResponse) servletResponse;
Span currentSpan = this.tracer.getCurrentSpan();
this.spanInjector.inject(currentSpan, response);
filterChain.doFilter(request, response);
}
}你可以这样注册:
@Bean
SpanInjector<HttpServletResponse> customHttpServletResponseSpanInjector() {
return new CustomHttpServletResponseSpanInjector();
}
@Bean
HttpResponseInjectingTraceFilter responseInjectingTraceFilter(Tracer tracer) {
return new HttpResponseInjectingTraceFilter(tracer, customHttpServletResponseSpanInjector());
}Zipkin中的自定义SA标签
有时你想创建一个手动的Span,它会将一个呼叫打包到一个没有被检测到的外部服务。您可以做的是创建一个包含peer.service标签的跨度,其中包含要调用的服务的值。下面你可以看到一个调用Redis的例子,它被包装在这样一个跨度里。
org.springframework.cloud.sleuth.Span newSpan = tracer.createSpan("redis");
try {
newSpan.tag("redis.op", "get");
newSpan.tag("lc", "redis");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_SEND);
// call redis service e.g
// return (SomeObj) redisTemplate.opsForHash().get("MYHASH", someObjKey);
} finally {
newSpan.tag("peer.service", "redisService");
newSpan.tag("peer.ipv4", "1.2.3.4");
newSpan.tag("peer.port", "1234");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_RECV);
tracer.close(newSpan);
}|
重要
|
请记住不要添加peer.service标签和SA标签!您只需添加peer.service。
|
自定义服务名称
默认情况下,Sleuth假设当您将跨度发送到Zipkin时,您希望跨度的服务名称等于spring.application.name值。这并不总是这样。在某些情况下,您希望为应用程序中的所有spans显式提供不同的服务名称。要实现这一点,只需将以下属性传递给应用程序即可覆盖该值(foo服务名称的示例):
spring.zipkin.service.name: fooSpan Data作为消息
可以积累和在发送跨度数据
Spring Cloud Stream通过包括spring-cloud-sleuth-stream罐作为依赖,以及加入信道Binder实现(例如spring-cloud-starter-stream-rabbit为RabbitMQ的或spring-cloud-starter-stream-kafka为Kafka)。这将自动将您的应用程序转换为有效载荷类型为Spans的邮件的生成者。
Zipkin消费者
有一个特殊的便利注释来设置Span数据的消息使用者,并将其推入Zipkin SpanStore。这个应用程序
@SpringBootApplication
@EnableZipkinStreamServer
public class Consumer {
public static void main(String[] args) {
SpringApplication.run(Consumer.class, args);
}
}将通过Spring Cloud Stream Binder(例如包括RabbitMQ的spring-cloud-starter-stream-rabbit)以及Redis和Kafka的类似起始者)收听您提供的任何传输的Span数据。如果添加以下UI依赖关系
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>然后,您将有一个Zipkin服务器,您的应用程序 在端口9411上承载UI和API。
默认的SpanStore是内存中的(适用于演示,快速入门)。对于更强大的解决方案,您可以将MySQL和spring-boot-starter-jdbc添加到类路径中,并通过配置启用JDBC SpanStore,例如:
spring:
rabbitmq:
host: ${RABBIT_HOST:localhost}
datasource:
schema: classpath:/mysql.sql
url: jdbc:mysql://${MYSQL_HOST:localhost}/test
username: root
password: root
# Switch this on to create the schema on startup:
initialize: true
continueOnError: true
sleuth:
enabled: false
zipkin:
storage:
type: mysql|
注意
|
@EnableZipkinStreamServer也用@EnableZipkinServer注释,所以该过程还将公开标准的Zipkin服务器端点,用于通过HTTP收集spans,并在Zipkin Web UI中进行查询。
|
定制消费者
也可以使用spring-cloud-sleuth-stream并绑定到SleuthSink来轻松实现自定义消费者。例:
@EnableBinding(SleuthSink.class)
@SpringBootApplication(exclude = SleuthStreamAutoConfiguration.class)
@MessageEndpoint
public class Consumer {
@ServiceActivator(inputChannel = SleuthSink.INPUT)
public void sink(Spans input) throws Exception {
// ... process spans
}
}|
注意
|
上面的示例消费者应用程序明确排除了SleuthStreamAutoConfiguration,因此它不会向其自己发送消息,但这是可选的(您可能希望将消息跟踪到消费者应用程序中)。
|
度量
目前Spring Cloud Sleuth注册了与spans相关的简单指标。它使用Spring Boot的指标支持 来计算接受和删除的数量spans。每次发送到Zipkin时,接受的spans的数量将增加。如果出现错误,则删除的数量spans将会增加。
集成
可运行和可调用
如果你在Runnable或Callable中包含逻辑,就可以将这些类包装在他们的Sleuth代表中。
Runnable的示例:
Runnable runnable = new Runnable() {
@Override
public void run() {
// do some work
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceRunnable` creation with explicit "calculateTax" Span name
Runnable traceRunnable = new TraceRunnable(tracer, spanNamer, runnable, "calculateTax");
// Wrapping `Runnable` with `Tracer`. The Span name will be taken either from the
// `@SpanName` annotation or from `toString` method
Runnable traceRunnableFromTracer = tracer.wrap(runnable);Callable的示例:
Callable<String> callable = new Callable<String>() {
@Override
public String call() throws Exception {
return someLogic();
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceCallable` creation with explicit "calculateTax" Span name
Callable<String> traceCallable = new TraceCallable<>(tracer, spanNamer, callable, "calculateTax");
// Wrapping `Callable` with `Tracer`. The Span name will be taken either from the
// `@SpanName` annotation or from `toString` method
Callable<String> traceCallableFromTracer = tracer.wrap(callable);这样,您将确保为每次执行创建并关闭新的跨度。
Hystrix
自定义并发策略
我们正在注册一个HystrixConcurrencyStrategy
将所有Callable实例包装到他们的Sleuth代表中的定制 - TraceCallable。该策略要么开始还是继续一个跨度,这取决于调用Hystrix命令之前跟踪是否已经进行的事实。要禁用自定义Hystrix并发策略,将spring.sleuth.hystrix.strategy.enabled设置为false。
手动命令设置
假设你有以下HystrixCommand:
HystrixCommand<String> hystrixCommand = new HystrixCommand<String>(setter) {
@Override
protected String run() throws Exception {
return someLogic();
}
};为了传递跟踪信息,您必须在HystrixCommand的TraceCommand的Sleuth版本中包装相同的逻辑:
TraceCommand<String> traceCommand = new TraceCommand<String>(tracer, traceKeys, setter) {
@Override
public String doRun() throws Exception {
return someLogic();
}
};RxJava
我们正在注册RxJavaSchedulersHook
将所有Action0实例包装到他们的Sleuth代表中的定制 - TraceAction。钩子起动或继续一个跨度取决于跟踪在Action被安排之前是否已经进行的事实。要禁用自定义RxJavaSchedulersHook设置spring.sleuth.rxjava.schedulers.hook.enabled为false。
您可以定义线程名称的正则表达式列表,您不需要创建Span。只需在spring.sleuth.rxjava.schedulers.ignoredthreads属性中提供逗号分隔的正则表达式列表。
HTTP集成
可以通过提供值等于false的spring.sleuth.web.enabled属性来禁用此部分的功能。
HTTP过滤器
通过TraceFilter所有采样的进入请求都会创建一个跨度。该Span的名称是http: +发送请求的路径。例如,如果请求已发送到/foo/bar,则该名称将为http:/foo/bar。您可以通过spring.sleuth.web.skipPattern属性配置要跳过的URI。如果您在类路径上有ManagementServerProperties,那么其值contextPath将附加到提供的跳过模式。
的HandlerInterceptor
由于我们希望跨度名称是精确的,我们使用TraceHandlerInterceptor来包装现有的HandlerInterceptor,或直接添加到现有的HandlerInterceptors列表中。TraceHandlerInterceptor向给定的HttpServletRequest添加了一个特殊请求属性。如果TraceFilter没有看到此属性集,它将创建一个“后备”跨度,这是在服务器端创建的一个额外的跨度,以便在UI中正确显示跟踪。看到最有可能意味着有一个缺失的仪器。在这种情况下,请在Spring Cloud Sleuth中提出问题。
异步Servlet支持
如果您的控制器返回Callable或WebAsyncTask Spring Cloud Sleuth将继续现有的跨度,而不是创建一个新的跨度。
HTTP客户端集成
同步休息模板
我们正在注入一个RestTemplate拦截器,确保所有跟踪信息都传递给请求。每次呼叫都会创建一个新的Span。收到回应后关闭。为了阻止同步的RestTemplate功能,只需将spring.sleuth.web.client.enabled设置为false。
|
重要
|
您必须注册RestTemplate作为一个bean,以便拦截器将被注入。如果您创建一个new关键字的RestTemplate实例,那么该工具将无法正常工作。
|
异步休息模板
|
重要
|
AsyncRestTemplate bean的跟踪版本是为您开箱即用的。如果你有你自己的bean,你必须把它包装成一个TraceAsyncRestTemplate表示。最好的解决方案是只定制ClientHttpRequestFactory和/或AsyncClientHttpRequestFactory。
如果您有自己的AsyncRestTemplate,并且不要包装,您的电话将不会被追踪。
|
定制仪器设置为在发送和接收请求时创建和关闭跨度。您可以通过注册您的bean来自定义ClientHttpRequestFactory和AsyncClientHttpRequestFactory。记住使用跟踪兼容的实现(例如,不要忘记在TraceAsyncListenableTaskExecutor中包装ThreadPoolTaskScheduler)。自定义请求工厂示例:
@EnableAutoConfiguration
@Configuration
public static class TestConfiguration {
@Bean
ClientHttpRequestFactory mySyncClientFactory() {
return new MySyncClientHttpRequestFactory();
}
@Bean
AsyncClientHttpRequestFactory myAsyncClientFactory() {
return new MyAsyncClientHttpRequestFactory();
}
}将AsyncRestTemplate功能集spring.sleuth.web.async.client.enabled封锁为false。禁用TraceAsyncClientHttpRequestFactoryWrapper设置spring.sleuth.web.async.client.factory.enabled设置为false。如果您不想将AsyncRestClient spring.sleuth.web.async.client.template.enabled设为false。
Feign
默认情况下,Spring Cloud Sleuth通过TraceFeignClientAutoConfiguration提供与feign的集成。您可以通过将spring.sleuth.feign.enabled设置为false来完全禁用它。如果这样做,那么不会发生Feign相关的仪器。
Feign仪器的一部分是通过FeignBeanPostProcessor完成的。您可以通过提供spring.sleuth.feign.processor.enabled等于false来禁用它。如果您这样设置,那么Spring Cloud Sleuth将不会调整您的任何自定义Feign组件。然而,所有默认的工具仍然存在。
异步通信
@Async注释方法
在Spring Cloud Sleuth中,我们正在检测异步相关的组件,以便跟踪信息在线程之间传递。您可以通过将spring.sleuth.async.enabled的值设置为false来禁用此行为。
如果您使用@Async注释方法,那么我们将自动创建一个具有以下特征的新Span:
-
Span名称将是注释方法名称
-
Span将被该方法的类名称和方法名称标记
@Scheduled注释方法
在Spring Cloud Sleuth中,我们正在调试计划的方法执行,以便跟踪信息在线程之间传递。您可以通过将spring.sleuth.scheduled.enabled的值设置为false来禁用此行为。
如果您使用@Scheduled注释方法,那么我们将自动创建一个具有以下特征的新Span:
-
Span名称将是注释方法名称
-
Span将被该方法的类名称和方法名称标记
如果要跳过某些@Scheduled注释类的Span创建,您可以使用与@Scheduled注释类的完全限定名称匹配的正则表达式来设置spring.sleuth.scheduled.skipPattern。
|
提示
|
如果您一起使用spring-cloud-sleuth-stream和spring-cloud-netflix-hystrix-stream,则会为每个Hystrix指标创建Span,并发送到Zipkin。这可能是恼人的。您可以设置spring.sleuth.scheduled.skipPattern=org.springframework.cloud.netflix.hystrix.stream.HystrixStreamTask
|
Executor,ExecutorService和ScheduledExecutorService
我们提供LazyTraceExecutor,TraceableExecutorService和TraceableScheduledExecutorService。每次提交,调用或调度新任务时,这些实现都将创建Spans。
在这里,您可以看到一个使用CompletableFuture使用TraceableExecutorService传递跟踪信息的示例:
CompletableFuture<Long> completableFuture = CompletableFuture.supplyAsync(() -> {
// perform some logic
return 1_000_000L;
}, new TraceableExecutorService(executorService,
// 'calculateTax' explicitly names the span - this param is optional
tracer, traceKeys, spanNamer, "calculateTax"));消息
Spring Cloud Sleuth与Spring Integration集成。它创建spans发布和订阅事件。要禁用Spring Integration检测,请将spring.sleuth.integration.enabled设置为false。
Spring Cloud Sleuth直到版本1.0.4在使用消息传递时发送无效的跟踪头。那些标头实际上与HTTP中发送的那些标头(它们包含一个-)的名称相同。为了在1.0.4中向后兼容,我们开始发送有效和无效的头文件。请升级到1.0.4,因为在Spring Cloud Sleuth 1.1中,我们将删除对已弃用头的支持。
自1.0.4以来,您可以提供spring.sleuth.integration.patterns模式,以明确提供要包括的跟踪通道名称。默认情况下,所有通道都包含在内。
Zuul
我们正在注册Zuul过滤器以传播跟踪信息(请求标头丰富了跟踪数据)。要禁用Zuul支持,请将spring.sleuth.zuul.enabled属性设置为false。
运行示例
您可以在Pivotal Web Services中找到部署的运行示例。在以下链接中查看它们:
Spring Cloud Consul
安装Consul
请参阅安装文档获取有关如何安装Consul指令。
Consul代理
所有Spring Cloud Consul应用程序必须可以使用Consul代理客户端。默认情况下,代理客户端预计位于localhost:8500。有关如何启动代理客户端以及如何连接到Consul代理服务器的群集的详细信息,请参阅代理文档。对于开发,安装consul后,您可以使用以下命令启动Consul代理:
./src/main/bash/local_run_consul.sh
这将启动端口8500上的服务器模式的代理,其中ui可以在http:// localhost:8500上找到
服务发现与Consul
服务发现是基于微服务架构的关键原则之一。尝试配置每个客户端或某种形式的约定可能非常困难,可以非常脆弱。Consul通过HTTP API和DNS提供服务发现服务。Spring Cloud Consul利用HTTP API进行服务注册和发现。这不妨碍非Spring Cloud应用程序利用DNS界面。Consul代理服务器在通过八卦协议进行通信的群集中运行,并使用筏式协议协议。
注册Consul
当客户端注册Consul时,它提供有关自身的元数据,例如主机和端口,ID,名称和标签。默认情况下会创建一个HTTP 检查,Consul每10秒点击一次/health端点。如果健康检查失败,则服务实例被标记为关键。
示例Consul客户端:
@SpringBootApplication
@EnableDiscoveryClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}(即完全正常的Spring Boot应用程序)。如果Consul客户端位于localhost:8500以外的位置,则需要配置来定位客户端。例:
spring:
cloud:
consul:
host: localhost
port: 8500
|
警告
|
如果您使用Spring Cloud Consul配置,上述值将需要放置在bootstrap.yml而不是application.yml中。
|
来自Environment的默认服务名称,实例ID和端口分别为${spring.application.name},Spring上下文ID和${server.port}。
@EnableDiscoveryClient将应用程序设为Consul“服务”(即注册自己)和“客户端”(即可以查询Consul查找其他服务)。
HTTP健康检查
Consul实例的运行状况检查默认为“/ health”,这是Spring Boot Actuator应用程序中有用端点的默认位置。如果您使用非默认上下文路径或servlet路径(例如server.servletPath=/foo)或管理端点路径(例如management.contextPath=/admin),则需要更改这些,即使是执行程序应用程序。也可以配置Consul用于检查运行状况端点的间隔。“10s”和“1m”分别表示10秒和1分钟。例:
spring:
cloud:
consul:
discovery:
healthCheckPath: ${management.contextPath}/health
healthCheckInterval: 15s
元数据和Consul标签
Consul尚未支持服务元数据。Spring Cloud的ServiceInstance有一个Map<String, String> metadata字段。Spring Cloud Consul使用Consul标签来近似元数据,直到Consul正式支持元数据。具有key=value形式的标签将被分割并分别用作Map键和值。没有相等=符号的标签将被用作键和值两者。
spring:
cloud:
consul:
discovery:
tags: foo=bar, baz
上述配置将导致foo→bar和baz→baz的地图。
使Consul实例ID唯一
默认情况下,使用等于其Spring应用程序上下文ID的ID注册consul实例。缺省情况下,Spring应用上下文ID为${spring.application.name}:comma,separated,profiles:${server.port}。在大多数情况下,这将允许一个服务的多个实例在一台机器上运行。如果需要进一步的唯一性,使用Spring Cloud,您可以通过在spring.cloud.consul.discovery.instanceId中提供唯一的标识来覆盖此。例如:
spring:
cloud:
consul:
discovery:
instanceId: ${spring.application.name}:${spring.application.instance_id:${random.value}}
使用这个元数据和在localhost上部署的多个服务实例,随机值将在那里进行,以使实例是唯一的。在Cloudfoundry中,spring.application.instance_id将在Spring Boot Actuator应用程序中自动填充,因此不需要随机值。
使用DiscoveryClient
Spring Cloud支持Feign(REST客户端构建器),还支持Spring RestTemplate使用逻辑服务名称而不是物理URL。
您还可以使用org.springframework.cloud.client.discovery.DiscoveryClient,它为Netflix不具体的发现客户端提供简单的API,例如
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List<ServiceInstance> list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri();
}
return null;
}
具有Consul的分布式配置
Consul提供了存储配置和其他元数据的密钥/值存储。Spring Cloud Consul配置是配置服务器和客户端的替代方案。在特殊的“引导”阶段,配置被加载到Spring环境中。默认情况下,配置存储在/config文件夹中。根据应用程序的名称和模拟解析属性的Spring Cloud Config顺序的活动配置文件,创建多个PropertySource实例。例如,名为“testApp”的应用程序和“dev”配置文件将创建以下属性源:
config/testApp,dev/ config/testApp/ config/application,dev/ config/application/
最具体的物业来源位于顶部,底部最不具体。Properties是config/application文件夹适用于使用consul配置的所有应用程序。config/testApp文件夹中的Properties仅适用于名为“testApp”的服务实例。
配置当前在应用程序启动时被读取。发送HTTP POST到/refresh将导致重新加载配置。观看关键价值商店(Consul支持))目前不可能,但将来将是此项目的补充。
如何激活
包括对org.springframework.cloud:spring-cloud-consul-config的依赖将启用将配置Spring Cloud Consul配置的自动配置。
定制
Consul可以使用以下属性自定义配置:
spring:
cloud:
consul:
config:
enabled: true
prefix: configuration
defaultContext: apps
profileSeparator: '::'
-
enabled将此值设置为“false”将禁用Consul配置 -
prefix设置配置值的基本文件夹 -
defaultContext设置所有应用程序使用的文件夹名称 -
profileSeparator设置用于使用配置文件在属性源中分隔配置文件名称的分隔符的值
YAML或Properties配置
与单个键/值对相反,以YAML或Properties格式存储一组属性可能更为方便。将spring.cloud.consul.config.format属性设置为YAML或PROPERTIES。例如使用YAML:
spring:
cloud:
consul:
config:
format: YAML
必须在consul中的相应data键中设置YAML。使用键上面的默认值将如下所示:
config/testApp,dev/data config/testApp/data config/application,dev/data config/application/data
您可以将YAML文档存储在上述任何键中。
您可以使用spring.cloud.consul.config.data-key更改数据密钥。
git2consul与配置
git2consul是一个Consul社区项目,将文件从git存储库加载到各个密钥到Consul。默认情况下,密钥的名称是文件的名称。分别支持文件扩展名为.yml和.properties的YAML和Properties文件。将spring.cloud.consul.config.format属性设置为FILES。例如:
spring:
cloud:
consul:
config:
format: FILES
给定/config中的以下密钥,development配置文件和应用程序名称foo:
.gitignore application.yml bar.properties foo-development.properties foo-production.yml foo.properties master.ref
将创建以下属性来源:
config/foo-development.properties config/foo.properties config/application.yml
每个密钥的值需要是一个格式正确的YAML或Properties文件。
快速失败
在某些情况下(如本地开发或某些测试场景)可能不方便,如果consul不可用于配置,则不会失败。在bootstrap.yml中设置spring.cloud.consul.config.failFast=false将导致配置模块记录一个警告,而不是抛出异常。这将允许应用程序继续正常启动。
Consul重试
如果您希望consul代理程序在您的应用程序启动时可能偶尔不可用,可以要求它在失败后继续尝试。您需要在您的类路径中添加spring-retry和spring-boot-starter-aop。默认行为是重试6次,初始退避间隔为1000ms,指数乘数为1.1,用于后续退避。您可以使用spring.cloud.consul.retry.*配置属性配置这些属性(和其他)。这适用于Spring Cloud Consul配置和发现注册。
|
提示
|
要完全控制重试,请使用id为“consulRetryInterceptor”添加RetryOperationsInterceptor类型的@Bean。Spring重试有一个RetryInterceptorBuilder可以轻松创建一个。
|
Spring Cloud Bus与Consul
稍后发行。
断路器与Hystrix
应用程序可以使用Spring Cloud Netflix项目提供的Hystrix断路器,将此启动器包含在项目pom.xml:spring-cloud-starter-hystrix中。Hystrix不依赖于Netflix Discovery Client。@EnableHystrix注释应放置在配置类(通常是主类)上。那么方法可以用@HystrixCommand注释来被断路器保护。有关详细信息,请参阅文档。
使用Turbine和Consul Hystrix指标聚合
Turbine(由Spring Cloud Netflix项目提供),聚合多个实例Hystrix指标流,因此仪表板可以显示聚合视图。Turbine使用DiscoveryClient界面查找相关实例。要使用Spring Cloud与Spring Cloud Consul的Turbine配置Turbine应用程序,类似于以下示例:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-turbine</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
请注意,Turbine依赖不是起始者。涡轮启动器包括对Netflix Eureka的支持。
spring.application.name: turbine
applications: consulhystrixclient
turbine:
aggregator:
clusterConfig: ${applications}
appConfig: ${applications}
clusterConfig和appConfig部分必须匹配,因此将逗号分隔的服务ID列表放在单独的配置属性中是有用的。
@EnableTurbine
@EnableDiscoveryClient
@SpringBootApplication
public class Turbine {
public static void main(String[] args) {
SpringApplication.run(DemoturbinecommonsApplication.class, args);
}
}
Spring Cloud Zookeeper
安装Zookeeper
请参阅安装文档获取有关如何安装Zookeeper指令。
服务发现与Zookeeper
服务发现是基于微服务架构的关键原则之一。尝试配置每个客户端或某种形式的约定可能非常困难,可以非常脆弱。策展人(一个用于Zookeeper的java库)通过服务发现扩展提供服务发现服务。Spring Cloud Zookeeper利用此扩展功能进行服务注册和发现。
如何激活
包括对org.springframework.cloud:spring-cloud-starter-zookeeper-discovery的依赖将启用自动配置,从而设置Spring Cloud Zookeeper发现。
注册Zookeeper
当客户端注册Zookeeper时,它提供有关自身的元数据,如主机和端口,ID和名称。
示例Zookeeper客户端:
@SpringBootApplication
@EnableDiscoveryClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}(即完全正常的Spring Boot应用程序)。如果Zookeeper位于localhost:2181以外的地方,则需要配置来定位服务器。例:
spring:
cloud:
zookeeper:
connect-string: localhost:2181
|
警告
|
如果您使用Spring Cloud Zookeeper配置,上述值将需要放置在bootstrap.yml而不是application.yml中。
|
来自Environment的默认服务名称,实例ID和端口分别为${spring.application.name},Spring上下文ID和${server.port}。
@EnableDiscoveryClient将应用程序同时进入Zookeeper“服务”(即注册自己)和“客户端”(即可以查询Zookeeper查找其他服务)。
使用DiscoveryClient
Spring Cloud支持Feign(REST客户端构建器),还支持Spring RestTemplate使用逻辑服务名称而不是物理URL。
您还可以使用org.springframework.cloud.client.discovery.DiscoveryClient,它为Netflix特有的发现客户端提供了一个简单的API,例如
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List<ServiceInstance> list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri().toString();
}
return null;
}
Zookeeper依赖关系
使用Zookeeper依赖关系
Spring Cloud Zookeeper使您可以将应用程序的依赖关系提供给属性。作为依赖关系,您可以了解Zookeeper中注册的其他应用程序,您可以通过Feign(REST客户端构建器)以及Spring RestTemplate呼叫。
您还可以从Zookeeper依赖关系观察者功能中受益,这些功能可让您控制和监视依赖关系的状态,并决定如何处理。
如何激活Zookeeper依赖关系
-
包括对
org.springframework.cloud:spring-cloud-starter-zookeeper-discovery的依赖将启用自动配置,这将自动设置Spring Cloud Zookeeper依赖关系。 -
如果您必须正确设置
spring.cloud.zookeeper.dependencies部分 - 请查看后续部分了解更多详细信息,然后该功能处于活动状态 -
即使您在属性中提供依赖关系,也可以关闭依赖关系。只需将属性
spring.cloud.zookeeper.dependency.enabled设置为false(默认为true)。
设置Zookeeper依赖关系
我们来仔细看一下依赖关系表示的例子:
spring.application.name: yourServiceName
spring.cloud.zookeeper:
dependencies:
newsletter:
path: /path/where/newsletter/has/registered/in/zookeeper
loadBalancerType: ROUND_ROBIN
contentTypeTemplate: application/vnd.newsletter.$version+json
version: v1
headers:
header1:
- value1
header2:
- value2
required: false
stubs: org.springframework:foo:stubs
mailing:
path: /path/where/mailing/has/registered/in/zookeeper
loadBalancerType: ROUND_ROBIN
contentTypeTemplate: application/vnd.mailing.$version+json
version: v1
required: true
现在让我们一个接一个地遍历依赖的每个部分。根属性名称为spring.cloud.zookeeper.dependencies。
别名
在根属性下面,由于Ribbon的限制,必须通过别名来表示每个依赖关系(应用程序ID必须放在URL中,因此您不能传递任何复杂的路径,如/ foo / bar / name )。别名将是您将使用的名称,而不是DiscoveryClient,Feign或RestTemplate的serviceId。
在上述例子中,别名是newsletter和mailing。Feign使用newsletter的示例将是:
@FeignClient("newsletter")
public interface NewsletterService {
@RequestMapping(method = RequestMethod.GET, value = "/newsletter")
String getNewsletters();
}
路径
代表path yaml属性。
Path是依赖关系在Zookeeper下注册的路径。像Ribbon之前提交的URL,因此此路径不符合其要求。这就是为什么Spring Cloud Zookeeper将别名映射到正确的路径。
负载平衡器类型
代表loadBalancerType yaml属性。
如果您知道在调用此特定依赖关系时必须应用什么样的负载平衡策略,那么您可以在yaml文件中提供它,并将自动应用。您可以选择以下负载平衡策略之一
-
STICKY - 一旦选择了该实例将始终被调用
-
随机 - 随机选择一个实例
-
ROUND_ROBIN - 一遍又一遍地迭代实例
Content-Type模板和版本
代表contentTypeTemplate和version yaml属性。
如果您通过Content-Type标题版本您的api,那么您不想将此标题添加到您的每个请求中。另外如果你想调用一个新版本的API,你不想漫游你的代码,以增加API版本。这就是为什么你可以提供contentTypeTemplate特殊的$version占位符。该占位符将由version yaml属性的值填充。我们来看一个例子。
拥有以下contentTypeTemplate:
application/vnd.newsletter.$version+json
和以下version:
v1
将导致为每个请求设置Content-Type标题:
application/vnd.newsletter.v1+json
默认标题
在yaml中代表headers地图
有时每次调用依赖关系都需要设置一些默认标头。为了不在代码中这样做,您可以在yaml文件中设置它们。拥有以下headers部分:
headers:
Accept:
- text/html
- application/xhtml+xml
Cache-Control:
- no-cache
结果在您的HTTP请求中添加适当的值列表的Accept和Cache-Control标头。
强制依赖
代表yaml中的required属性
如果您的一个依赖关系在应用程序启动时需要启动并运行,则可以在yaml文件中设置required: true属性。
如果您的应用程序无法在引导期间本地化所需的依赖关系,则会引发异常,并且Spring上下文将无法设置。换句话说,如果Zookeeper中没有注册所需的依赖关系,您的应用程序将无法启动。
您可以在以下部分阅读更多有关Spring Cloud Zookeeper存在检查器的信息。
存根
您可以为包含依赖关系的存根的JAR提供冒号分隔路径。例
stubs: org.springframework:foo:stubs意味着对于特定的依赖关系可以在下面找到:
-
groupId:
org.springframework -
artifactId:
foo -
分类器:
stubs- 这是默认值
这实际上等于
stubs: org.springframework:foo因为stubs是默认分类器。
配置Spring Cloud Zookeeper依赖关系
有一些属性可以设置为启用/禁用Zookeeper依赖关系功能的部分。
-
spring.cloud.zookeeper.dependencies- 如果您不设置此属性,则不会从Zookeeper依赖关系中受益 -
spring.cloud.zookeeper.dependency.ribbon.enabled(默认情况下启用) - Ribbon需要显式的全局配置或特定的依赖关系。通过打开此属性,运行时负载平衡策略解决是可能的,您可以从Zookeeper依赖关系的loadBalancerType部分获利。需要此属性的配置具有LoadBalancerClient的实现,该代理委托给下一个子弹中的ILoadBalancer -
spring.cloud.zookeeper.dependency.ribbon.loadbalancer(默认情况下启用) - 感谢这个属性,自定义ILoadBalancer知道传递给Ribbon的URI部分实际上可能是必须被解析为Zookeeper。没有此属性,您将无法在嵌套路径下注册应用程序。 -
spring.cloud.zookeeper.dependency.headers.enabled(默认情况下启用) - 此属性注册这样一个RibbonClient,将自动添加适当的头文件和内容类型,其中包含依赖关系配置中显示的版本。没有这两个参数的设置将不会运行。 -
spring.cloud.zookeeper.dependency.resttemplate.enabled(默认情况下启用) - 启用时将修改@LoadBalanced注释的RestTemplate的请求标头,以便它在依赖关系配置中传递具有版本集的标题和内容类型。Wihtout这两个参数的设置将无法运行。
Spring Cloud Zookeeper依赖关系观察者
依赖关系观察器机制允许您将侦听器注册到依赖关系中。该功能实际上是Observator模式的实现。当依赖关系改变其状态(UP或DOWN)时,可以应用一些自定义逻辑。
如何激活
Spring Cloud Zookeeper依赖关系功能需要启用从依赖关系观察器机制中获利。
注册听众
为了注册一个监听器,你必须实现一个接口org.springframework.cloud.zookeeper.discovery.watcher.DependencyWatcherListener并将其注册为一个bean。该界面为您提供了一种方法:
void stateChanged(String dependencyName, DependencyState newState);
如果要为特定的依赖关系注册一个侦听器,则dependencyName将是您具体实现的鉴别器。newState将为您提供有关您的依赖关系是否已更改为CONNECTED或DISCONNECTED的信息。
存在检查
绑定与依赖关系观察器是称为存在检查器的功能。它允许您在启动应用程序时提供自定义行为,以根据您的依赖关系的状态作出反应。
抽象org.springframework.cloud.zookeeper.discovery.watcher.presence.DependencyPresenceOnStartupVerifier类的默认实现是org.springframework.cloud.zookeeper.discovery.watcher.presence.DefaultDependencyPresenceOnStartupVerifier,其工作方式如下。
-
如果依赖关系标记为我们
required,并且不在Zookeeper中,则在引导时,您的应用程序将抛出异常并关闭 -
如果依赖关系不是
required,org.springframework.cloud.zookeeper.discovery.watcher.presence.LogMissingDependencyChecker将在WARN级别上记录该应用程序
功能可以被覆盖,因为DefaultDependencyPresenceOnStartupVerifier只有在没有DependencyPresenceOnStartupVerifier的bean时被注册。
分布式配置与Zookeeper
Zookeeper提供了一个分层命名空间,允许客户端存储任意数据,如配置数据。Spring Cloud Zookeeper Config是Config Server和Client的替代方案。在特殊的“引导”阶段,配置被加载到Spring环境中。默认情况下,配置存储在/config命名空间中。根据应用程序的名称和模拟解析属性的Spring Cloud Config顺序的活动配置文件创建多个PropertySource实例。例如,名为“testApp”的应用程序和“dev”配置文件将创建以下属性源:
config/testApp,dev config/testApp config/application,dev config/application
最具体的物业来源位于顶部,底部最不具体。Properties是config/application命名空间适用于使用zookeeper进行配置的所有应用程序。config/testApp命名空间中的Properties仅适用于名为“testApp”的服务实例。
配置当前在应用程序启动时被读取。发送HTTP POST到/refresh将导致重新加载配置。观察配置命名空间(其中Zookeeper支持))目前尚未实现,但将来将成为此项目的补充。
如何激活
包括对org.springframework.cloud:spring-cloud-starter-zookeeper-config的依赖将启用将自动配置Spring Cloud Zookeeper配置的自动配置。
定制
Zookeeper可以使用以下属性自定义配置:
spring:
cloud:
zookeeper:
config:
enabled: true
root: configuration
defaultContext: apps
profileSeparator: '::'
-
enabled将此值设置为“false”将禁用Zookeeper配置 -
root设置配置值的基本命名空间 -
defaultContext设置所有应用程序使用的名称 -
profileSeparator设置用于使用配置文件在属性源中分隔配置文件名称的分隔符的值
Spring Boot Cloud CLI
@EnableEurekaServer)的Groovy脚本。您还可以轻松地进行加密和解密等操作,以支持具有秘密配置值的Spring Cloud Config客户端。使用Launcher CLI,您可以从命令行一次性启动Eureka,Zipkin,Config Server等服务(在开发时非常有用)。
安装
要安装,请确保您具有 Spring Boot CLI (1.4.1或更好):
$ spring version Spring CLI v1.4.1.RELEASE
例如SDKMan用户
$ sdk install springboot 1.4.1.RELEASE
$ sdk use springboot 1.4.1.RELEASE并安装Spring Cloud插件
$ mvn install
$ spring install org.springframework.cloud:spring-cloud-cli:1.2.3.BUILD-SNAPSHOT|
重要
|
先决条件:要使用加密和解密功能,您需要在JVM中安装全面的JCE(默认情况下不存在)。您可以从Oracle下载“Java加密扩展(JCE)无限强度管理策略文件”,并按照安装说明(实际上将JRE lib / security目录中的2个策略文件替换为您下载的文件)。 |
在开发中运行Spring Cloud服务
Launcher CLI可以用于从命令行运行像Eureka,Config Server等常用服务。列出您可以执行的可用服务spring cloud --list,并启动spring cloud的一组默认服务。要选择要部署的服务,只需在命令行中列出它们,例如
$ spring cloud eureka configserver h2 kafka zipkin
支持的可部署的摘要:
| 服务 | 名称 | 地址 | 描述 |
|---|---|---|---|
eureka |
Eureka Server |
Eureka服务器进行服务注册和发现。所有其他服务默认显示在其目录中。 |
|
configserver |
Config Server |
Spring Cloud Config服务器以“本机”配置文件运行,并从本地目录./launcher提供配置 |
|
h2 |
H2 Database |
http://localhost:9095 (console), jdbc:h2:tcp://localhost:9096/{data} |
关系数据库服务。连接时使用文件路径 |
kafka |
Kafka Broker |
http://localhost:9091 (actuator endpoints), localhost:9092 |
|
hystrixdashboard |
Hystrix Dashboard |
任何声明Hystrix断路器的Spring Cloud应用程式都会在 |
|
dataflow |
Dataflow Server |
Spring Cloud数据流服务器,用户名为/ admin-ui。将Dataflow shell以根路径连接到目标。 |
|
zipkin |
Zipkin Server |
Zipkin具有用于可视化跟踪的UI的服务器。存储器将数据跨越内存并通过JSON数据的HTTP POST接受。 |
可以使用具有相同名称的本地YAML文件(在当前工作目录或名为“config”或~/.spring-cloud的子目录)中配置这些应用程序。例如,在configserver.yml中,您可能需要执行此操作来查找后端的本地git存储库:
spring:
profiles:
active: git
cloud:
config:
server:
git:
uri: file://${user.home}/dev/demo/config-repo添加其他应用程序
其他应用程序可以添加到./config/cloud.yml(不是./config.yml,因为这将替换默认值),例如
spring:
cloud:
launcher:
deployables:
source:
coordinates: maven://com.example:source:0.0.1-SNAPSHOT
port: 7000
sink:
coordinates: maven://com.example:sink:0.0.1-SNAPSHOT
port: 7001列出应用程式时:
$ spring cloud --list
source sink configserver dataflow eureka h2 hystrixdashboard kafka zipkin(注意列表开头附加的应用程序)。
编写Groovy脚本并运行应用程序
Spring Cloud CLI支持大部分Spring Cloud声明性功能,例如@Enable*注解类。例如,这是一个功能齐全的Eureka服务器
@EnableEurekaServer
class Eureka {}你可以从这样的命令行运行它
$ spring run app.groovy
要包括额外的依赖关系,通常只需添加适当的特征启用注释即可,例如@EnableConfigServer,@EnableOAuth2Sso或@EnableEurekaClient。要手动包含一个依赖关系,您可以使用@Grab特殊的“Spring Boot”短格式工件坐标,即仅使用工件ID(不需要组或版本信息),例如设置客户端应用程序在AMQP上收听来自Spring CLoud总线的管理事件:
@Grab('spring-cloud-starter-bus-amqp')
@RestController
class Service {
@RequestMapping('/')
def home() { [message: 'Hello'] }
}加密和解密
Spring Cloud CLI附带一个“encrypt”和“decrypt”命令。两个接受以指定为强制“ - ”的键的相同形式的参数,例如
$ spring encrypt mysecret --key foo 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda $ spring decrypt --key foo 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda mysecret
要在文件中使用密钥(例如,用于encyption的RSA公钥),使用“@”键入键值,并提供文件路径,例如
$ spring encrypt mysecret --key @${HOME}/.ssh/id_rsa.pub
AQAjPgt3eFZQXwt8tsHAVv/QHiY5sI2dRcR+...
Spring Cloud Security
快速开始
OAuth2单一登录
这是一个拥有HTTP Basic身份验证和单个用户帐户的Spring Cloud“Hello World”应用程序:
@Grab('spring-boot-starter-security')
@Controller
class Application {
@RequestMapping('/')
String home() {
'Hello World'
}
}您可以使用spring run app.groovy运行它,并观察日志的密码(用户名为“用户”)。到目前为止,这只是Spring Boot应用程序的默认设置。
这是一个使用OAuth2 SSO的Spring Cloud应用程式:
@Controller
@EnableOAuth2Sso
class Application {
@RequestMapping('/')
String home() {
'Hello World'
}
}指出不同?这个应用程序的行为实际上与之前的一样,因为它不知道它是OAuth2的信誉。
您可以很容易地在github注册一个应用程序,所以如果你想要一个生产应用程序在你自己的域上尝试。如果您很乐意在localhost:8080上测试,那么请在应用程序配置中设置这些属性:
spring:
oauth2:
client:
clientId: bd1c0a783ccdd1c9b9e4
clientSecret: 1a9030fbca47a5b2c28e92f19050bb77824b5ad1
accessTokenUri: https://github.com/login/oauth/access_token
userAuthorizationUri: https://github.com/login/oauth/authorize
clientAuthenticationScheme: form
resource:
userInfoUri: https://api.github.com/user
preferTokenInfo: false运行上面的应用程序,它将重定向到github进行授权。如果您已经登录github,您甚至不会注意到它已经通过身份验证。只有您的应用程序在8080端口上运行,这些凭据才会起作用。
要限制客户端在获取访问令牌时要求的范围,您可以设置spring.oauth2.client.scope(逗号分隔或YAML中的数组)。默认情况下,作用域为空,由授权服务器确定默认值是什么,通常取决于客户端注册中的设置。
OAuth2受保护资源
您要使用OAuth2令牌保护API资源?这是一个简单的例子(与上面的客户端配对):
@Grab('spring-cloud-starter-security')
@RestController
@EnableResourceServer
class Application {
@RequestMapping('/')
def home() {
[message: 'Hello World']
}
}和
spring:
oauth2:
resource:
userInfoUri: https://api.github.com/user
preferTokenInfo: false更多详情
单点登录
|
注意
|
所有的OAuth2 SSO和资源服务器功能在版本1.3中移动到Spring Boot。您可以在Spring Boot用户指南中查找文档 。 |
令牌中继
令牌中继是OAuth2消费者充当客户端,并将传入令牌转发到外发资源请求。消费者可以是纯客户端(如SSO应用程序)或资源服务器。
客户端令牌中继
如果您的应用是面向OAuth2客户端的用户(即宣布@EnableOAuth2Sso或@EnableOAuth2Client)),那么它的请求范围为Spring Boot的OAuth2ClientContext。您可以从此上下文和自动连线OAuth2ProtectedResourceDetails创建自己的OAuth2RestTemplate,然后上下文将始终向下转发访问令牌,如果过期则自动刷新访问令牌。(这些是Spring安全性和Spring Boot的功能。)
|
注意
|
如果您使用client_credentials令牌,Spring Boot(1.4.1)不会自动创建OAuth2ProtectedResourceDetails。在这种情况下,您需要创建自己的ClientCredentialsResourceDetails并使用@ConfigurationProperties("security.oauth2.client")进行配置。
|
Zuul代理服务器中的客户端令牌中继
如果您的应用程序还有
Spring Cloud Zuul嵌入式反向代理(使用@EnableZuulProxy),那么您可以要求它将OAuth2访问令牌转发到其代理的服务。因此,上述的SSO应用程序可以简单地增强:
@Controller
@EnableOAuth2Sso
@EnableZuulProxy
class Application {
}并且(除了记录用户并抓取令牌之外)还将认证令牌向下游传递到/proxy/*服务。如果这些服务是使用@EnableResourceServer实现的,那么他们将在正确的头中获取一个有效的令牌。
它是如何工作的?@EnableOAuth2Sso注释引入spring-cloud-starter-security(您可以在传统应用程序中手动执行),并反过来触发一个ZuulFilter的自动配置,该自定义本身被激活,因为Zuul在classpath(via @EnableZuulProxy)。该
过滤器
仅从当前已认证的用户提取访问令牌,并将其放入下游请求的请求头中。
资源服务器令牌中继
如果您的应用程序有@EnableResourceServer,则可能需要将传入令牌下载到其他服务。如果您使用RestTemplate联系下游服务,那么这只是如何使用正确的上下文创建模板的问题。
如果您的服务使用UserInfoTokenServices来验证传入令牌(即使用security.oauth2.user-info-uri配置),则可以使用自动连线OAuth2ClientContext创建OAuth2RestTemplate(将由身份验证过程之前它遇到后端代码)。等价(使用Spring Boot 1.4),您可以在配置中注入UserInfoRestTemplateFactory并抓取其OAuth2RestTemplate。例如:
@Bean
public OAuth2RestTemplate restTemplate(UserInfoRestTemplateFactory factory) {
return factory.getUserInfoRestTemplate();
}然后,这个休息模板将具有认证过滤器使用的相同的OAuth2ClientContext(请求范围),因此您可以使用它来发送具有相同访问令牌的请求。
如果您的应用没有使用UserInfoTokenServices,但仍然是客户端(即声明@EnableOAuth2Client或@EnableOAuth2Sso),则使用Spring安全云任何OAuth2RestOperations,用户从@Autowired @OAuth2Context也会转发令牌。此功能默认实现为MVC处理程序拦截器,因此它仅适用于Spring MVC。如果您不使用MVC,可以使用包含AccessTokenContextRelay的自定义过滤器或AOP拦截器来提供相同的功能。
以下是一个基本示例,显示了使用其他地方创建的自动连线休息模板(“foo.com”是一个资源服务器,接受与周围应用程序相同的令牌):
@Autowired
private OAuth2RestOperations restTemplate;
@RequestMapping("/relay")
public String relay() {
ResponseEntity<String> response =
restTemplate.getForEntity("https://foo.com/bar", String.class);
return "Success! (" + response.getBody() + ")";
}如果您不想转发令牌(这是一个有效的选择,因为您可能想要像自己一样,而不是向您发送令牌的客户端),那么您只需要创建自己的OAuth2Context的自动装配默认值。
Feign客户端也会选择一个拦截器,使用OAuth2ClientContext,如果它是可用的,那么他们还应该在RestTemplate将要执行的令牌中继。
配置Zuul代理下游的认证
您可以通过proxy.auth.*设置控制@EnableZuulProxy下游的授权行为。例:
proxy:
auth:
routes:
customers: oauth2
stores: passthru
recommendations: none在此示例中,“客户”服务获取OAuth2令牌中继,“存储”服务获取传递(授权头只是通过下游),“建议”服务已删除其授权头。如果有令牌可用,则默认行为是执行令牌中继,否则为passthru。
有关详细信息,请参阅 ProxyAuthenticationProperties。
Spring Cloud for Cloud Foundry
Cloudfoundry的Spring Cloud可以轻松在Cloud Foundry(平台即服务)中运行 Spring Cloud应用程序 。Cloud Foundry有一个“服务”的概念,它是“绑定”到应用程序的中间件,本质上为其提供包含凭据的环境变量(例如,用于服务的位置和用户名)。
spring-cloud-cloudfoundry-web项目为Cloud Foundry中的webapps的一些增强功能提供了基本支持:自动绑定到单点登录服务,并可选择启用粘性路由进行发现。
spring-cloud-cloudfoundry-discovery项目提供Spring Cloud Commons DiscoveryClient的实施,所以您可以@EnableDiscoveryClient并将您的凭证提供为spring.cloud.cloudfoundry.discovery.[email,password],然后可以直接使用DiscoveryClient或通过LoadBalancerClient(如果您没有连接到Pivotal Web Services,则也为*.url
)。
第一次使用它时,发现客户端可能很慢,因为它必须从Cloud Foundry获取访问令牌。
发现
以下是Cloud Foundry发现的Spring Cloud应用程式:
@Grab('org.springframework.cloud:spring-cloud-cloudfoundry')
@RestController
@EnableDiscoveryClient
class Application {
@Autowired
DiscoveryClient client
@RequestMapping('/')
String home() {
'Hello from ' + client.getLocalServiceInstance()
}
}如果您运行它没有任何服务绑定:
$ spring jar app.jar app.groovy $ cf push -p app.jar
它将在主页中显示其应用程序名称。
DiscoveryClient可以列出空间中的所有应用程序,这些应用程序根据身份验证的凭据,其中的空间默认为客户端运行的空间(如果有的话)。如果组织和空间都不配置,则它们将根据Cloud Foundry中的用户配置文件进行默认。
单点登录
|
注意
|
所有的OAuth2 SSO和资源服务器功能在版本1.3中移动到Spring Boot。您可以在Spring Boot用户指南中查找文档 。 |
该项目提供从CloudFoundry服务凭据到Spring Boot功能的自动绑定。如果您有一个称为“sso”的CloudFoundry服务,例如,凭借包含“client_id”,“client_secret”和“auth_domain”的凭据,它将自动绑定到您启用的Spring OAuth2客户端@EnableOAuth2Sso(来自Spring Boot)。可以使用spring.oauth2.sso.serviceId参数化服务的名称。
Spring Cloud集群
Leader选举
Leader选举允许应用程序与其他应用程序一起通过第三方系统协调集群领导。目前,我们提供与zookeeper,hazelcast和etcd的集成。
从用户的角度来看,选举通过接口org.springframework.cloud.cluster.leader.Candidate和org.springframework.cloud.cluster.leader.Context工作。Candidate包含访问领导层的role和id,并且还有方法onGranted和onRevoked。如果更改默认Candidate实现,这些回调方法很有用。
Leader选举是自动配置的,如果从类路径中找到spring-cloud-cluster-autoconfigure和spring-cloud-cluster-hazelcast,spring-cloud-cluster-zookeeper或spring-cloud-cluster-etcd jars。如果发现两个罐子都是使用这两个系统创建的。有关创建的bean的更多信息,请参见Zookeeper,
Hazelcast和
Etcd部分。
从自动配置创建的默认Candidate是org.springframework.cloud.cluster.leader.DefaultCandidate,目前只有日志被许可和撤销事件。
如果需要禁用所有与引导相关的自动配置,则可以将spring.cloud.cluster.leader.enabled设置为false,即使在类路径上存在jar也可以进行手动配置。Properties spring.cloud.cluster.leader.id和spring.cloud.cluster.leader.role可用于设置默认标识符和角色。
如果您有兴趣简单地获得授权和撤销事件的通知,则一个选项是将事件侦听器附加到Spring ApplicationContext中。Events OnGrantedEvent和OnRevokedEvent作为Spring事件对象发送。
只需创建自己的事件侦听器类:
class MyEventListener implements ApplicationListener<AbstractLeaderEvent> {
@Override
public void onApplicationEvent(AbstractLeaderEvent event) {
// do something with OnGrantedEvent or OnRevokedEvent
}
}然后将其创建为一个bean。
@Configuration
static class Config {
@Bean
public MyEventListener myEventListener() {
return new MyEventListener();
}
}对于简单的日志事件,您还可以使用实用程序类LoggingListener,这样可以轻松配置。
import org.springframework.cloud.cluster.leader.event.LoggingListener;
@Configuration
static class Config {
@Bean
public LoggingListener loggingListener() {
return new LoggingListener("info");
}
}Zookeeper
zookeeper的Candidate实现使用bean名称zookeeperLeaderCandidate创建,可以用于覆盖在自动配置期间创建的一个。
可以使用属性spring.cloud.cluster.zookeeper.leader.enabled明确禁用基于Zookeeper的选举。
其他属性spring.cloud.cluster.zookeeper.namespace和spring.cloud.cluster.zookeeper.connect可用于设置zookeeper基本命名空间路径和连接字符串。
Hazelcast
Candidate使用bean名称hazelcastLeaderCandidate创建了hazelcast的实现,该名称可以用于覆盖自动配置过程中创建的一个。
可以使用属性spring.cloud.cluster.hazelcast.leader.enabled显式禁用基于Hazelcast的选举。如果要为Hazelcast实例提供基于xml的配置,则使用属性spring.cloud.cluster.hazelcast.config-location来告诉Hazelcast xml配置文件的位置。config-location是普通的SpringResource。
Etcd
使用bean名称etcdLeaderCandidate创建了用于etcd的Candidate实现,可以用它来覆盖在自动配置过程中创建的一个。
可以使用属性spring.cloud.cluster.etcd.leader.enabled明确禁用基于Etcd的选举。
可以使用属性spring.cloud.cluster.etcd.connect指定多个etcd集群uris
附录:配置纲要Properties
| 名称 | 默认 | 描述 |
|---|---|---|
encrypt.fail-on-error |
true |
标记说,如果存在加密或解密错误,进程将失败。 |
encrypt.key |
对称密钥。作为一个更强大的替代方案,考虑使用密钥库。 |
|
encrypt.key-store.alias |
商店中的钥匙别名 |
|
encrypt.key-store.location |
密钥存储文件的位置,例如classpath:/keystore.jks。 |
|
encrypt.key-store.password |
锁定密钥库的密码。 |
|
encrypt.key-store.secret |
秘密保护密钥(默认为密码相同)。 |
|
encrypt.rsa.algorithm |
使用RSA算法(DEFAULT或OEAP)。一旦设置不改变它(或现有的密码将不可解密)。 |
|
encrypt.rsa.salt |
deadbeef |
Salt用于加密密文的随机秘密。一旦设置不改变它(或现有的密码将不可解密)。 |
encrypt.rsa.strong |
false |
标志表示应该在内部使用“强”AES加密。如果为真,则将GCM算法应用于AES加密字节。默认值为false(在这种情况下使用“标准”CBC代替)。一旦设置不改变它(或现有的密码将不可解密)。 |
endpoints.bus.enabled |
||
endpoints.bus.id |
||
endpoints.bus.sensitive |
||
endpoints.consul.enabled |
||
endpoints.consul.id |
||
endpoints.consul.sensitive |
||
endpoints.features.enabled |
||
endpoints.features.id |
||
endpoints.features.sensitive |
||
endpoints.pause.enabled |
||
endpoints.pause.id |
||
endpoints.pause.sensitive |
||
endpoints.refresh.enabled |
||
endpoints.refresh.id |
||
endpoints.refresh.sensitive |
||
endpoints.restart.enabled |
||
endpoints.restart.id |
||
endpoints.restart.pause-endpoint.enabled |
||
endpoints.restart.pause-endpoint.id |
||
endpoints.restart.pause-endpoint.sensitive |
||
endpoints.restart.resume-endpoint.enabled |
||
endpoints.restart.resume-endpoint.id |
||
endpoints.restart.resume-endpoint.sensitive |
||
endpoints.restart.sensitive |
||
endpoints.restart.timeout |
0 |
|
endpoints.resume.enabled |
||
endpoints.resume.id |
||
endpoints.resume.sensitive |
||
eureka.client.allow-redirects |
false |
指示服务器是否可以将客户端请求重定向到备份服务器/集群。如果设置为false,服务器将直接处理请求,如果设置为true,则可能会向客户端发送HTTP重定向,并具有新的服务器位置。 |
eureka.client.availability-zones |
获取此实例所在区域的可用性区域列表(用于AWS数据中心)。 更改在运行时在registryFetchIntervalSeconds指定的下一个注册表提取周期中有效。 |
|
eureka.client.backup-registry-impl |
获取执行BackupRegistry的实现的名称,以便仅在eureka客户端启动时首次将注册表信息作为回退选项提取。 对于需要额外的弹性的注册表信息的应用程序可能需要这一点,而无法运行它们。 |
|
eureka.client.cache-refresh-executor-exponential-back-off-bound |
10 |
缓存刷新执行者指数退出相关属性。在发生超时序列的情况下,它是重试延迟的最大乘数值。 |
eureka.client.cache-refresh-executor-thread-pool-size |
2 |
cacheRefreshExecutor初始化的线程池大小 |
eureka.client.client-data-accept |
EurekaAccept客户端数据接受名称 |
|
eureka.client.decoder-name |
这是一个瞬态配置,一旦最新的编解码器稳定,可以删除(因为只有一个) |
|
eureka.client.disable-delta |
false |
指示eureka客户端是否应该禁用提取delta,而应该诉诸于获取完整的注册表信息。 请注意,增量获取可以极大地减少流量,因为尤利卡服务器的更改速率通常远低于提取速率。 更改在运行时在registryFetchIntervalSeconds指定的下一个注册表提取周期中有效 |
eureka.client.dollar-replacement |
_- |
在eureka服务器的序列化/反序列化信息期间,获取Dollar符号<code> $ </ code>的替换字符串。 |
eureka.client.enabled |
true |
标记以指示启用Eureka客户端。 |
eureka.client.encoder-name |
这是一个瞬态配置,一旦最新的编解码器稳定,可以删除(因为只有一个) |
|
eureka.client.escape-char-replacement |
__ |
在eureka服务器的序列化/反序列化信息期间获取下划线符号<code> _ </ code>的替换字符串。 |
eureka.client.eureka-connection-idle-timeout-seconds |
30 |
表示到eureka服务器的HTTP连接可以在关闭之前保持空闲状态的时间(以秒为单位)。 在AWS环境中,建议值为30秒或更短,因为防火墙在几分钟内清除连接信息,将连接挂在空中 |
eureka.client.eureka-server-connect-timeout-seconds |
5 |
指示在连接到eureka服务器需要超时之前等待(以秒为单位)的时间。请注意,客户端中的连接由org.apache.http.client.HttpClient汇集,此设置会影响实际的连接创建以及从池中获取连接的等待时间。 |
eureka.client.eureka-server-dnsname |
获取要查询的DNS名称以获取eureka服务器的列表。如果合同通过实现serviceUrls返回服务URL,则不需要此信息。 当useDnsForFetchingServiceUrls设置为true时,使用DNS机制,而eureka客户端希望DNS以某种方式配置,以便可以动态获取更改的eureka服务器。 更改在运行时有效。 |
|
eureka.client.eureka-server-port |
获取用于构建服务url的端口,以在eureka服务器列表来自DNS时联系eureka服务器。如果合同返回服务url eurekaServerServiceUrls(String),则不需要此信息。 当useDnsForFetchingServiceUrls设置为true时,使用DNS机制,而eureka客户端希望DNS以某种方式配置,以便可以动态获取更改的eureka服务器。 更改在运行时有效。 |
|
eureka.client.eureka-server-read-timeout-seconds |
8 |
指示从eureka服务器读取之前需要等待(秒)多久才能超时。 |
eureka.client.eureka-server-total-connections |
200 |
获取从eureka客户端到所有eureka服务器允许的总连接数。 |
eureka.client.eureka-server-total-connections-per-host |
50 |
获取从eureka客户端到eureka服务器主机允许的总连接数。 |
eureka.client.eureka-server-urlcontext |
获取用于构建服务网址的URL上下文,以便在eureka服务器列表来自DNS时联系eureka服务器。如果合同从eurekaServerServiceUrls返回服务网址,则不需要此信息。 当useDnsForFetchingServiceUrls设置为true时,使用DNS机制,而eureka客户端希望DNS以某种方式配置,以便可以动态获取更改的eureka服务器。更改在运行时有效。 |
|
eureka.client.eureka-service-url-poll-interval-seconds |
0 |
表示轮询对eureka服务器信息进行更改的频率(以秒为单位)。可以添加或删除Eureka服务器,并且此设置控制尤里卡客户端应该知道的时间。 |
eureka.client.fetch-registry |
true |
指示该客户端是否应从eureka服务器获取eureka注册表信息。 |
eureka.client.fetch-remote-regions-registry |
逗号分隔将获取eureka注册表信息的区域列表。必须为availabilityZones返回的每个区域定义可用性区域。否则,将导致发现客户端启动失败。 |
|
eureka.client.filter-only-up-instances |
true |
指示是否在仅具有InstanceStatus UP状态的实例的过滤应用程序之后获取应用程序。 |
eureka.client.g-zip-content |
true |
指示从服务器支持时,是否必须压缩从eureka服务器提取的内容。来自eureka服务器的注册表信息被压缩以获得最佳的网络流量。 |
eureka.client.heartbeat-executor-exponential-back-off-bound |
10 |
心跳执行者指数回撤相关财产。在发生超时序列的情况下,它是重试延迟的最大乘数值。 |
eureka.client.heartbeat-executor-thread-pool-size |
2 |
heartbeat执行器初始化的线程池大小 |
eureka.client.initial-instance-info-replication-interval-seconds |
40 |
指示将实例信息复制到eureka服务器的开始时间(以秒为单位) |
eureka.client.instance-info-replication-interval-seconds |
30 |
指示复制要复制到eureka服务器的实例更改的频率(以秒为单位)。 |
eureka.client.log-delta-diff |
false |
指示在注册表信息方面是否记录eureka服务器和eureka客户端之间的差异。 Eureka客户端尝试仅从欧莱雅服务器检索增量更改以最小化网络流量。收到三角形后,eureka客户端将从服务器的信息进行协调,以验证它是否已经没有漏掉一些信息。当客户端发生网络问题与服务器通信时,可能会发生调解失败。如果对帐失败,eureka客户端将获得完整的注册表信息。 在获取完整的注册表信息的同时,eureka客户端可以记录客户端和服务器之间的差异,并且此设置控制它。 更改在运行时在registryFetchIntervalSecondsr指定的下一个注册表提取周期中有效 |
eureka.client.on-demand-update-status-change |
true |
如果设置为true,则通过ApplicationInfoManager进行的本地状态更新将触发对远程eureka服务器的按需(但限速)注册/更新 |
eureka.client.prefer-same-zone-eureka |
true |
指示此实例是否应尝试在同一区域中使用尤里卡服务器延迟和/或其他原因。 理想情况下,eureka客户端配置为与同一区域中的服务器通信 更改在运行时在registryFetchIntervalSeconds指定的下一个注册表提取周期中有效 |
eureka.client.property-resolver |
||
eureka.client.proxy-host |
获取代理主机到eureka服务器(如果有的话)。 |
|
eureka.client.proxy-password |
获取代理密码(如果有)。 |
|
eureka.client.proxy-port |
获取代理端口到eureka服务器(如果有的话)。 |
|
eureka.client.proxy-user-name |
获取代理用户名(如果有)。 |
|
eureka.client.region |
us-east-1 |
获取此实例所在的区域(用于AWS数据中心)。 |
eureka.client.register-with-eureka |
true |
指示此实例是否应将其信息注册到eureka服务器以供其他人发现。 在某些情况下,您不希望发现实例,而您只想发现其他实例。 |
eureka.client.registry-fetch-interval-seconds |
30 |
指示从eureka服务器获取注册表信息的频率(以秒为单位)。 |
eureka.client.registry-refresh-single-vip-address |
指示客户端是否只对单个VIP的注册表信息感兴趣。 |
|
eureka.client.service-url |
可用性区域映射到与eureka服务器通信的完全限定URL的列表。每个值可以是单个URL或逗号分隔的替代位置列表。 通常,尤里卡服务器URL携带协议,主机,端口,上下文和版本信息(如果有的话)。示例:http : //ec2-256-156-243-129.compute-1.amazonaws.com : 7001/eureka/ 更改在运行时在eurekaServiceUrlPollIntervalSeconds指定的下一个服务网址刷新周期中有效。 |
|
eureka.client.transport |
||
eureka.client.use-dns-for-fetching-service-urls |
false |
指示eureka客户端是否应该使用DNS机制来获取要与之通信的eureka服务器列表。当DNS名称更新为具有其他服务器时,该信息将在eureka客户端轮询该eurkaServiceUrlPollIntervalSeconds中指定的信息之后立即使用。 或者,服务urls可以返回serviceUrls,但用户应该实现自己的机制来返回更新的列表,以防发生更改。 更改在运行时有效。 |
eureka.dashboard.enabled |
true |
标志以启用Eureka仪表板。默认值为true。 |
eureka.dashboard.path |
/ |
到Eureka仪表板(相对于servlet路径)的路径。默认为“/”。 |
eureka.instance.a-sgname |
获取与此实例关联的AWS自动缩放组名称。该信息在AWS环境中专门用于在实例启动后自动将实例停止运行,并且已将其禁用。 |
|
eureka.instance.app-group-name |
获取要在eureka中注册的应用程序组的名称。 |
|
eureka.instance.appname |
unknown |
获取要在eureka注册的应用程序的名称。 |
eureka.instance.data-center-info |
返回此实例部署的数据中心。如果实例部署在AWS中,则此信息用于获取一些AWS特定实例信息。 |
|
eureka.instance.default-address-resolution-order |
[] |
|
eureka.instance.health-check-url |
获取此实例的绝对运行状况检查页面URL。如果运行状况检查页面驻留在与eureka通话的同一个实例中,用户可以提供healthCheckUrlPath,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。 <p>它通常用于根据实例的健康状况做出有根据的决策 - 例如,它可用于确定是否继续部署到整个场,或者停止部署而不会造成进一步的损坏。完整的URL应遵循格式http:// $ {eureka.hostname}:7001 /其中值$ {eureka.hostname}在运行时被替换。 |
|
eureka.instance.health-check-url-path |
/health |
获取此实例的相对运行状况检查URL路径。然后,健康检查页面URL由主机名和通信类型构建,如securePort和nonSecurePort中指定的安全或不安全。 它通常用于根据实例的健康状况做出有根据的决策 - 例如,它可用于确定是否继续部署到整个场,或者停止部署而不会造成进一步的损坏。 |
eureka.instance.home-page-url |
获取此实例的绝对主页URL。如果主页位于与eureka通话的同一个实例中,用户可以提供homePageUrlPath,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。 它通常用于其他服务的信息目的,以将其用作着陆页。完整的URL应遵循格式http:// $ {eureka.hostname}:7001 / 其中值$ {eureka.hostname}在运行时被替换。 |
|
eureka.instance.home-page-url-path |
/ |
获取此实例的相对主页URL路径。然后,主页URL由hostName和通信类型构建 - 安全或不安全。 它通常用于其他服务的信息目的,以将其用作着陆页。 |
eureka.instance.host-info |
||
eureka.instance.hostname |
如果可以在配置时确定主机名(否则将从操作系统原语中猜出)。 |
|
eureka.instance.inet-utils |
||
eureka.instance.initial-status |
初始状态为rmeote Eureka服务器注册。 |
|
eureka.instance.instance-enabled-onit |
false |
指示在eureka注册后,实例是否应该启用流量。有时候,应用程序可能需要做一些预处理,才能准备好交通。 |
eureka.instance.instance-id |
获取要在eureka注册的此实例的唯一ID(在appName的范围内)。 |
|
eureka.instance.ip-address |
获取实例的IPAdress。此信息仅用于学术目的,因为来自其他实例的通信主要发生在使用{@link #getHostName(boolean)}中提供的信息。 |
|
eureka.instance.lease-expiration-duration-in-seconds |
90 |
指示eureka服务器在接收到最后一个心跳之后等待的时间(秒),然后才能从此视图中删除此实例,并禁止此实例的流量。 将此值设置得太长可能意味着流量可以路由到实例,即使实例不存在。设置此值太小可能意味着,由于临时网络故障,实例可能会被取消流量。此值将设置为至少高于leaseRenewalIntervalInSeconds中指定的值。 |
eureka.instance.lease-renewal-interval-in-seconds |
30 |
指示eureka客户端需要向eureka服务器发送心跳以指示它仍然存在的频率(以秒为单位)。如果在leaseExpirationDurationInSeconds中指定的时间段内未收到心跳线,则eureka服务器将从其视图中删除该实例,因此不允许此实例的流量。 请注意,如果该实例实现HealthCheckCallback,然后决定使其本身不可用,则该实例仍然可能无法访问流量。 |
eureka.instance.metadata-map |
获取与此实例关联的元数据名称/值对。该信息发送到eureka服务器,可以被其他实例使用。 |
|
eureka.instance.namespace |
eureka |
获取用于查找属性的命名空间。忽略在Spring Cloud中。 |
eureka.instance.non-secure-port |
80 |
获取实例应该接收流量的非安全端口。 |
eureka.instance.non-secure-port-enabled |
true |
指示是否应启用非安全端口的流量。 |
eureka.instance.prefer-ip-address |
false |
标示说,当猜测主机名时,服务器的IP地址应该在操作系统报告的主机名中使用。 |
eureka.instance.secure-health-check-url |
获取此实例的绝对安全运行状况检查页面URL。如果健康检查页面驻留在与eureka通话的同一个实例中,用户可以提供secureHealthCheckUrl,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。 <p>它通常用于根据实例的健康状况做出有根据的决策 - 例如,它可用于确定是否继续部署到整个场,或者停止部署而不会造成进一步的损坏。完整的URL应遵循格式http:// $ {eureka.hostname}:7001 /其中值$ {eureka.hostname}在运行时被替换。 |
|
eureka.instance.secure-port |
443 |
获取实例应该接收流量的安全端口。 |
eureka.instance.secure-port-enabled |
false |
指示安全端口是否应启用流量。 |
eureka.instance.secure-virtual-host-name |
获取为此实例定义的安全虚拟主机名。 这通常是其他实例通过使用安全虚拟主机名找到此实例的方式。这与完全限定域名相似,您的服务的用户将需要找到此实例。 |
|
eureka.instance.status-page-url |
获取此实例的绝对状态页面URL路径。如果状态页面驻留在与eureka通话的同一个实例中,用户可以提供statusPageUrlPath,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。 它通常用于其他服务的信息目的,以查找此实例的状态。用户可以提供一个简单的HTML来指示实例的当前状态。 |
|
eureka.instance.status-page-url-path |
/info |
获取此实例的相对状态页面URL路径。然后,状态页面URL由安全端口和非安全端口中指定的hostName和通信类型构建 - 安全或不安全。 它通常用于其他服务的信息目的,以查找此实例的状态。用户可以提供一个简单的HTML来指示实例的当前状态。 |
eureka.instance.virtual-host-name |
获取为此实例定义的虚拟主机名。 这通常是其他实例通过使用虚拟主机名找到此实例的方式。这与完全限定域名相似,您的服务的用户将需要找到此实例。 |
|
eureka.server.a-sgcache-expiry-timeout-ms |
0 |
|
eureka.server.a-sgquery-timeout-ms |
300 |
|
eureka.server.a-sgupdate-interval-ms |
0 |
|
eureka.server.a-wsaccess-id |
||
eureka.server.a-wssecret-key |
||
eureka.server.batch-replication |
false |
|
eureka.server.binding-strategy |
||
eureka.server.delta-retention-timer-interval-in-ms |
0 |
|
eureka.server.disable-delta |
false |
|
eureka.server.disable-delta-for-remote-regions |
false |
|
eureka.server.disable-transparent-fallback-to-other-region |
false |
|
eureka.server.e-ipbind-rebind-retries |
3 |
|
eureka.server.e-ipbinding-retry-interval-ms |
0 |
|
eureka.server.e-ipbinding-retry-interval-ms-when-unbound |
0 |
|
eureka.server.enable-replicated-request-compression |
false |
|
eureka.server.enable-self-preservation |
true |
|
eureka.server.eviction-interval-timer-in-ms |
0 |
|
eureka.server.g-zip-content-from-remote-region |
true |
|
eureka.server.json-codec-name |
||
eureka.server.list-auto-scaling-groups-role-name |
ListAutoScalingGroups |
|
eureka.server.log-identity-headers |
true |
|
eureka.server.max-elements-in-peer-replication-pool |
10000 |
|
eureka.server.max-elements-in-status-replication-pool |
10000 |
|
eureka.server.max-idle-thread-age-in-minutes-for-peer-replication |
15 |
|
eureka.server.max-idle-thread-in-minutes-age-for-status-replication |
10 |
|
eureka.server.max-threads-for-peer-replication |
20 |
|
eureka.server.max-threads-for-status-replication |
1 |
|
eureka.server.max-time-for-replication |
30000 |
|
eureka.server.min-threads-for-peer-replication |
5 |
|
eureka.server.min-threads-for-status-replication |
1 |
|
eureka.server.number-of-replication-retries |
5 |
|
eureka.server.peer-eureka-nodes-update-interval-ms |
0 |
|
eureka.server.peer-eureka-status-refresh-time-interval-ms |
0 |
|
eureka.server.peer-node-connect-timeout-ms |
200 |
|
eureka.server.peer-node-connection-idle-timeout-seconds |
30 |
|
eureka.server.peer-node-read-timeout-ms |
200 |
|
eureka.server.peer-node-total-connections |
1000 |
|
eureka.server.peer-node-total-connections-per-host |
500 |
|
eureka.server.prime-aws-replica-connections |
true |
|
eureka.server.property-resolver |
||
eureka.server.rate-limiter-burst-size |
10 |
|
eureka.server.rate-limiter-enabled |
false |
|
eureka.server.rate-limiter-full-fetch-average-rate |
100 |
|
eureka.server.rate-limiter-privileged-clients |
||
eureka.server.rate-limiter-registry-fetch-average-rate |
500 |
|
eureka.server.rate-limiter-throttle-standard-clients |
false |
|
eureka.server.registry-sync-retries |
0 |
|
eureka.server.registry-sync-retry-wait-ms |
0 |
|
eureka.server.remote-region-app-whitelist |
||
eureka.server.remote-region-connect-timeout-ms |
1000 |
|
eureka.server.remote-region-connection-idle-timeout-seconds |
30 |
|
eureka.server.remote-region-fetch-thread-pool-size |
20 |
|
eureka.server.remote-region-read-timeout-ms |
1000 |
|
eureka.server.remote-region-registry-fetch-interval |
30 |
|
eureka.server.remote-region-total-connections |
1000 |
|
eureka.server.remote-region-total-connections-per-host |
500 |
|
eureka.server.remote-region-trust-store |
||
eureka.server.remote-region-trust-store-password |
changeit |
|
eureka.server.remote-region-urls |
||
eureka.server.remote-region-urls-with-name |
||
eureka.server.renewal-percent-threshold |
0.85 |
|
eureka.server.renewal-threshold-update-interval-ms |
0 |
|
eureka.server.response-cache-auto-expiration-in-seconds |
180 |
|
eureka.server.response-cache-update-interval-ms |
0 |
|
eureka.server.retention-time-in-msin-delta-queue |
0 |
|
eureka.server.route53-bind-rebind-retries |
3 |
|
eureka.server.route53-binding-retry-interval-ms |
0 |
|
eureka.server.route53-domain-ttl |
30 |
|
eureka.server.sync-when-timestamp-differs |
true |
|
eureka.server.use-read-only-response-cache |
true |
|
eureka.server.wait-time-in-ms-when-sync-empty |
0 |
|
eureka.server.xml-codec-name |
||
feign.compression.request.mime-types |
[text/xml, application/xml, application/json] |
支持的MIME类型列表。 |
feign.compression.request.min-request-size |
2048 |
最小阈值内容大小。 |
health.config.enabled |
false |
标记以指示应安装配置服务器运行状况指示器。 |
health.hystrix.enabled |
false |
标志着要安装hystrix健康指示器。 |
netflix.atlas.batch-size |
10000 |
|
netflix.atlas.enabled |
true |
|
netflix.atlas.uri |
||
proxy.auth.load-balanced |
false |
|
proxy.auth.routes |
每个路由的认证策略。 |
|
spring.cloud.bus.ack.destination-service |
想要听ack的服务。默认为null(表示所有服务)。 |
|
spring.cloud.bus.ack.enabled |
true |
标志关闭acks(默认打开)。 |
spring.cloud.bus.destination |
springCloudBus |
邮件的Spring Cloud Stream目的地名称。 |
spring.cloud.bus.enabled |
true |
标志表示总线已启用。 |
spring.cloud.bus.env.enabled |
true |
标志关闭环境变化事件(默认为开)。 |
spring.cloud.bus.refresh.enabled |
true |
关闭刷新事件的标志(默认为开)。 |
spring.cloud.bus.trace.enabled |
false |
打开acks跟踪的标志(默认关闭)。 |
spring.cloud.cloudfoundry.discovery.email |
验证用户的电子邮件地址。 |
|
spring.cloud.cloudfoundry.discovery.enabled |
true |
标记以指示启用发现。 |
spring.cloud.cloudfoundry.discovery.password |
用户验证和获取令牌的密码。 |
|
spring.cloud.cloudfoundry.discovery.url |
Cloud Foundry API(云控制器)的URL。 |
|
spring.cloud.config.allow-override |
true |
标记以指示可以使用{@link #isSystemPropertiesOverride()systemPropertiesOverride}。设置为false以防止用户意外更改默认值。默认值为true。 |
spring.cloud.config.discovery.enabled |
false |
标记以指示启用配置服务器发现(配置服务器URL将通过发现查找)。 |
spring.cloud.config.discovery.service-id |
CONFIGSERVER |
服务ID来定位配置服务器。 |
spring.cloud.config.enabled |
true |
标记说远程配置启用。默认为true; |
spring.cloud.config.fail-fast |
false |
标记表示无法连接到服务器是致命的(默认为false)。 |
spring.cloud.config.label |
用于拉取远程配置属性的标签名称。默认设置在服务器上(通常是基于git的服务器的“主”)。 |
|
spring.cloud.config.name |
用于获取远程属性的应用程序名称。 |
|
spring.cloud.config.override-none |
false |
标志表示当{@link #setAllowOverride(boolean)allowOverride}为true时,外部属性应该采用最低优先级,并且不覆盖任何现有的属性源(包括本地配置文件)。默认为false。 |
spring.cloud.config.override-system-properties |
true |
标记以指示外部属性应覆盖系统属性。默认值为true。 |
spring.cloud.config.password |
联系远程服务器时使用的密码(HTTP Basic)。 |
|
spring.cloud.config.profile |
default |
获取远程配置时使用的默认配置文件(逗号分隔)。默认为“默认”。 |
spring.cloud.config.retry.initial-interval |
1000 |
初始重试间隔(以毫秒为单位)。 |
spring.cloud.config.retry.max-attempts |
6 |
最大尝试次数。 |
spring.cloud.config.retry.max-interval |
2000 |
退避的最大间隔 |
spring.cloud.config.retry.multiplier |
1.1 |
下一个间隔的乘数。 |
spring.cloud.config.uri |
远程服务器的URI(默认http:// localhost:8888)。 |
|
spring.cloud.config.username |
联系远程服务器时使用的用户名(HTTP Basic)。 |
|
spring.cloud.consul.config.acl-token |
||
spring.cloud.consul.config.data-key |
data |
如果格式为Format.PROPERTIES或Format.YAML,则使用以下字段查找配置的consul。 |
spring.cloud.consul.config.default-context |
application |
|
spring.cloud.consul.config.enabled |
true |
|
spring.cloud.consul.config.fail-fast |
true |
在配置查找期间抛出异常,如果为true,否则为日志警告。 |
spring.cloud.consul.config.format |
||
spring.cloud.consul.config.prefix |
config |
|
spring.cloud.consul.config.profile-separator |
, |
|
spring.cloud.consul.config.watch.delay |
10 |
|
spring.cloud.consul.config.watch.enabled |
true |
|
spring.cloud.consul.config.watch.wait-time |
2 |
|
spring.cloud.consul.discovery.acl-token |
||
spring.cloud.consul.discovery.catalog-services-watch-delay |
10 |
|
spring.cloud.consul.discovery.catalog-services-watch-timeout |
2 |
|
spring.cloud.consul.discovery.enabled |
true |
是否启用服务发现? |
spring.cloud.consul.discovery.health-check-interval |
10s |
执行健康检查的频率(例如10s) |
spring.cloud.consul.discovery.health-check-path |
/health |
调用健康检查的备用服务器路径 |
spring.cloud.consul.discovery.health-check-timeout |
健康检查超时(例如10s) |
|
spring.cloud.consul.discovery.health-check-url |
自定义健康检查网址覆盖默认值 |
|
spring.cloud.consul.discovery.heartbeat.enabled |
false |
|
spring.cloud.consul.discovery.heartbeat.heartbeat-interval |
||
spring.cloud.consul.discovery.heartbeat.interval-ratio |
||
spring.cloud.consul.discovery.heartbeat.ttl-unit |
s |
|
spring.cloud.consul.discovery.heartbeat.ttl-value |
30 |
|
spring.cloud.consul.discovery.host-info |
||
spring.cloud.consul.discovery.hostname |
访问服务器时使用的主机名 |
|
spring.cloud.consul.discovery.instance-id |
唯一的服务实例ID |
|
spring.cloud.consul.discovery.ip-address |
访问服务时使用的IP地址(还必须设置preferIpAddress才能使用) |
|
spring.cloud.consul.discovery.lifecycle.enabled |
true |
|
spring.cloud.consul.discovery.management-suffix |
management |
注册管理服务时使用后缀 |
spring.cloud.consul.discovery.management-tags |
注册管理服务时使用的标签 |
|
spring.cloud.consul.discovery.port |
端口注册服务(默认为侦听端口) |
|
spring.cloud.consul.discovery.prefer-agent-address |
false |
我们将如何确定使用地址的来源 |
spring.cloud.consul.discovery.prefer-ip-address |
false |
在注册时使用ip地址而不是主机名 |
spring.cloud.consul.discovery.query-passing |
false |
将“pass”参数添加到/ v1 / health / service / serviceName。这会将健康检查推送到服务器。 |
spring.cloud.consul.discovery.register |
true |
在consul注册为一项服务。 |
spring.cloud.consul.discovery.register-health-check |
true |
注册身体检查consul。在开发服务期间有用。 |
spring.cloud.consul.discovery.scheme |
http |
是否注册http或https服务 |
spring.cloud.consul.discovery.server-list-query-tags |
服务器列表中要查询的serviceId的→标签的映射。这允许通过单个标签过滤服务。 |
|
spring.cloud.consul.discovery.service-name |
服务名称 |
|
spring.cloud.consul.discovery.tags |
注册服务时使用的标签 |
|
spring.cloud.consul.enabled |
true |
是否启用spring cloud consul |
spring.cloud.consul.host |
localhost |
Consul代理主机名。默认为“localhost”。 |
spring.cloud.consul.port |
8500 |
Consul代理端口。默认为'8500'。 |
spring.cloud.consul.retry.initial-interval |
1000 |
初始重试间隔(以毫秒为单位)。 |
spring.cloud.consul.retry.max-attempts |
6 |
最大尝试次数。 |
spring.cloud.consul.retry.max-interval |
2000 |
退避的最大间隔 |
spring.cloud.consul.retry.multiplier |
1.1 |
下一个间隔的乘数。 |
spring.cloud.hypermedia.refresh.fixed-delay |
5000 |
|
spring.cloud.hypermedia.refresh.initial-delay |
10000 |
|
spring.cloud.inetutils.default-hostname |
localhost |
默认主机名。用于发生错误的情况。 |
spring.cloud.inetutils.default-ip-address |
127.0.0.1 |
默认ipaddress。用于发生错误的情况。 |
spring.cloud.inetutils.ignored-interfaces |
将被忽略的网络接口的Java正则表达式列表。 |
|
spring.cloud.inetutils.timeout-seconds |
1 |
计算主机名的超时秒数。 |
spring.cloud.stream.binders |
||
spring.cloud.stream.bindings |
||
spring.cloud.stream.consumer-defaults |
||
spring.cloud.stream.default-binder |
||
spring.cloud.stream.dynamic-destinations |
[] |
|
spring.cloud.stream.ignore-unknown-properties |
true |
|
spring.cloud.stream.instance-count |
1 |
|
spring.cloud.stream.instance-index |
0 |
|
spring.cloud.stream.producer-defaults |
||
spring.cloud.stream.rabbit.binder.addresses |
[] |
|
spring.cloud.stream.rabbit.binder.admin-adresses |
[] |
|
spring.cloud.stream.rabbit.binder.compression-level |
0 |
|
spring.cloud.stream.rabbit.binder.nodes |
[] |
|
spring.cloud.stream.rabbit.binder.password |
||
spring.cloud.stream.rabbit.binder.ssl-properties-location |
||
spring.cloud.stream.rabbit.binder.use-ssl |
false |
|
spring.cloud.stream.rabbit.binder.username |
||
spring.cloud.stream.rabbit.binder.vhost |
||
spring.cloud.stream.rabbit.bindings |
||
spring.cloud.zookeeper.default-health-endpoint |
将检查以验证依赖关系是否存在的默认运行状况端点 |
|
spring.cloud.zookeeper.dependencies |
将别名映射到ZookeeperDependency。从Ribbon角度看,别名实际上是serviceID,因为Ribbon不能在serviceID中接受嵌套结构 |
|
spring.cloud.zookeeper.dependency-configurations |
||
spring.cloud.zookeeper.dependency-names |
||
spring.cloud.zookeeper.discovery.enabled |
true |
|
spring.cloud.zookeeper.discovery.instance-host |
||
spring.cloud.zookeeper.discovery.metadata |
获取与此实例关联的元数据名称/值对。该信息被发送到动物管理员,可以被其他实例使用。 |
|
spring.cloud.zookeeper.discovery.root |
/services |
|
spring.cloud.zookeeper.discovery.uri-spec |
{scheme}://{address}:{port} |
|
spring.cloud.zookeeper.prefix |
将应用于所有Zookeeper依赖关系的路径的公共前缀 |
|
spring.integration.poller.fixed-delay |
1000 |
修复默认轮询器的延迟。 |
spring.integration.poller.max-messages-per-poll |
1 |
默认轮询器每轮询的最大消息。 |
spring.sleuth.keys.async.class-name-key |
class |
具有使用{@code @Async} 注释的方法的类的简单名称,从异步进程开始 @see org.springframework.scheduling.annotation.Async |
spring.sleuth.keys.async.method-name-key |
method |
使用{@code @Async} 注释的方法的名称 @see org.springframework.scheduling.annotation.Async |
spring.sleuth.keys.async.prefix |
如果标题名称被添加为标签,则使用前缀。 |
|
spring.sleuth.keys.async.thread-name-key |
thread |
执行异步方法的线程的名称 @see org.springframework.scheduling.annotation.Async |
spring.sleuth.keys.http.headers |
额外的标题应该作为标签添加,如果它们存在。如果头值是多值的,则标签值将是逗号分隔的单引号列表。 |
|
spring.sleuth.keys.http.host |
http.host |
URL或主机头的域部分。示例:“mybucket.s3.amazonaws.com”。用于过滤主机而不是ip地址。 |
spring.sleuth.keys.http.method |
http.method |
HTTP方法或动词,如“GET”或“POST”。用于过滤http路由。 |
spring.sleuth.keys.http.path |
http.path |
绝对的http路径,没有任何查询参数。示例:“/ objects / abcd-ff”。用于过滤http路由,可以与zipkin v1一起移植。在zipkin v1中,只支持等于过滤器。删除查询参数使不同URI的数量减少。例如,无论查询行中编码的签名参数如何,都可以查询相同的资源。这不会降低HTTP单路由的基数。例如,通常将路由表示为http URI模板,如“/ resource / {resource_id}”。在只有等量查询可用的系统中,如果实际请求是“/ resource / abcd-ff” ,则搜索 {@code http.uri = / resource}将不匹配。历史记录:这通常在拉链中被表示为“http.uri”,但最常见的只是一条路。 |
spring.sleuth.keys.http.prefix |
http. |
如果标题名称被添加为标签,则使用前缀。 |
spring.sleuth.keys.http.request-size |
http.request.size |
非空HTTP请求体的大小(以字节为单位)。防爆。"16384" <p>大上传可能会超出限制或直接影响延迟。 |
spring.sleuth.keys.http.response-size |
http.response.size |
非空HTTP响应体的大小(以字节为单位)。防爆。"16384" <p>大量下载可能会超出限制或直接影响延迟。 |
spring.sleuth.keys.http.status-code |
http.status_code |
当HTTP响应代码不在2xx范围内。防爆。“503”用于过滤错误状态。2xx范围不会被记录,因为成功代码对延迟故障排除不那么有趣。省略节省每个跨度至少20个字节。 |
spring.sleuth.keys.http.url |
http.url |
整个URL,包括方案,主机和查询参数(如果可用)。防爆。“https://mybucket.s3.amazonaws.com/objects/abcd-ff?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Algorithm=AWS4-HMAC-SHA256...”结合{@link #method },您可以了解完全限定的请求行。这是可选的,因为它可能包括私人数据或相当长的长度。 |
spring.sleuth.keys.hystrix.command-group |
commandGroup |
命令组的名称 Hystrix使用命令组密钥将诸如报告,警报,仪表板或团队/库所有权的命令分组在一起。 @see com.netflix.hystrix.HystrixCommandGroupKey |
spring.sleuth.keys.hystrix.command-key |
commandKey |
命令键的名称 描述给定命令的名称。代表用于监视,断路器,指标发布,缓存和其他此类用途的{@link com.netflix.hystrix.HystrixCommand}的关键。 @see com.netflix.hystrix.HystrixCommandKey |
spring.sleuth.keys.hystrix.prefix |
如果标题名称被添加为标签,则使用前缀。 |
|
spring.sleuth.keys.hystrix.thread-pool-key |
threadPoolKey |
线程池密钥的名称。线程池密钥表示用于监视,指标发布,缓存和其他此类用途的{@link com.netflix.hystrix.HystrixThreadPool}。甲{@link com.netflix.hystrix.HystrixCommand}与单个相关的{@link com.netflix.hystrix.HystrixThreadPool}如由检索{@link com.netflix.hystrix.HystrixThreadPoolKey}注入它,或者它的默认值使用{@link com.netflix.hystrix.HystrixCommandGroupKey}创建的创建它。 @see com.netflix.hystrix.HystrixThreadPoolKey |
spring.sleuth.keys.message.headers |
额外的标题应该作为标签添加,如果它们存在。如果头值不是String,它将使用其toString()方法转换为String。 |
|
spring.sleuth.keys.message.payload.size |
message/payload-size |
估计有效载荷的大小(如果有的话)。 |
spring.sleuth.keys.message.payload.type |
message/payload-type |
有效载荷的类型。 |
spring.sleuth.keys.message.prefix |
message/ |
如果标题名称被添加为标签,则使用前缀。 |
spring.sleuth.metric.span.accepted-name |
counter.span.accepted |
|
spring.sleuth.metric.span.dropped-name |
counter.span.dropped |
|
spring.sleuth.sampler.percentage |
0.1 |
应采样的请求百分比。例如1.0 - 100%的请求应该被抽样。精度仅为全数(即不支持0.1%的痕迹)。 |
zuul.add-proxy-headers |
true |
|
zuul.host.max-per-route-connections |
20 |
|
zuul.host.max-total-connections |
200 |
|
zuul.ignore-local-service |
true |
|
zuul.ignored-headers |
||
zuul.ignored-patterns |
||
zuul.ignored-services |
||
zuul.prefix |
||
zuul.remove-semicolon-content |
true |
|
zuul.retryable |
||
zuul.routes |
||
zuul.security_headers |
||
zuul.servlet-path |
/zuul |
|
zuul.strip-prefix |
true |
|
zuul.trace-request-body |
true |