Spring Cloud Stream核心
1. Spring数据集成之旅的简史
Spring数据集成之旅始于Spring Integration。通过其编程模型,它提供了一致的开发人员体验,可以构建可以包含企业集成模式以与外部系统(如数据库,消息代理等)连接的应用程序。
快进到云时代,微服务在企业环境中变得突出。Spring Boot改变了开发人员构建应用程序的方式。使用Spring的编程模型和Spring Boot处理的运行时职责,开发独立的,基于生产级Spring的微服务变得无缝。
为了将其扩展到数据集成工作负载,将Spring Integration和Spring Boot组合到一个新项目中。Spring Cloud Stream诞生了。
使用Spring Cloud Stream,开发人员可以:*独立构建,测试,迭代和部署以数据为中心的应用程序。*应用现代微服务架构模式,包括通过消息传递组合。*将应用程序职责与以事件为中心的思维分开。事件可以表示及时发生的事情,下游消费者应用程序可以在不知道其来源或生产者身份的情况下做出反应。*将业务逻辑移植到消息代理(例如RabbitMQ,Apache Kafka,Amazon Kinesis)。*通过使用Project Reactor的Flux和Kafka Streams API,在基于通道和非基于通道的应用程序绑定方案之间进行互操作,以支持无状态和有状态计算。*依靠框架对常见用例的自动内容类型支持。可以扩展到不同的数据转换类型。
2.快速入门
您可以在不到5分钟内尝试Spring Cloud Stream,甚至在您按照这个三步指南跳转到任何细节之前。
我们将向您展示如何创建一个Spring Cloud Stream应用程序,该应用程序接收来自您选择的消息传递中间件的消息(稍后将详细介绍),并将收到的消息记录到控制台。我们称之为LoggingConsumer。虽然不太实用,但它提供了一些主要概念和抽象的良好介绍,使其更容易消化本用户指南的其余部分。
这三个步骤如下:
2.1.使用Spring Initializr创建示例应用程序
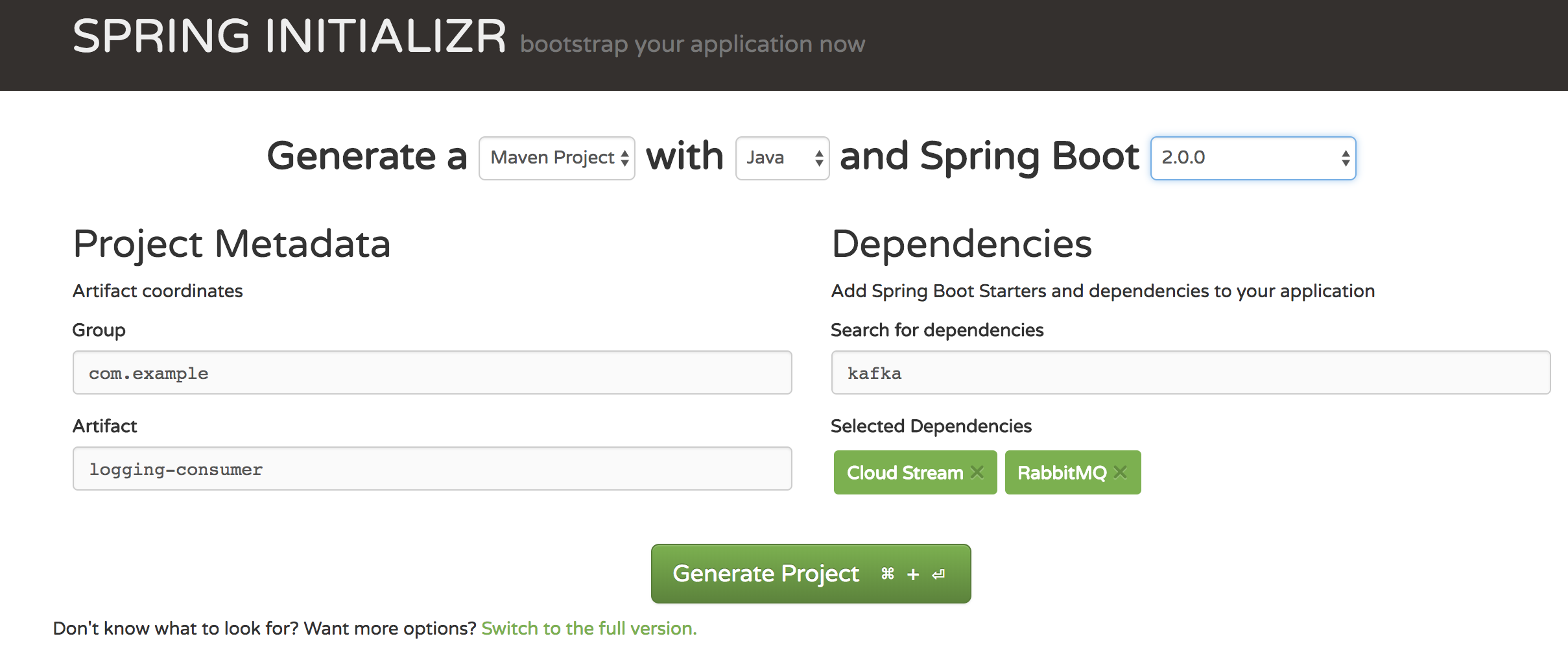
要开始使用,请访问Spring Initializr。从那里,您可以生成我们的LoggingConsumer应用程序。为此:
-
在“ 依赖关系”部分中,开始键入
stream。当出现“Cloud Stream”选项时,选择它。 -
开始输入'kafka'或'rabbit'。
-
选择“Kafka”或“RabbitMQ”。
基本上,您选择应用程序绑定的消息传递中间件。我们建议您使用已安装的或安装和运行时感觉更舒适。此外,从Initilaizer屏幕中可以看到,您可以选择其他一些选项。例如,您可以选择Gradle作为构建工具而不是Maven(默认值)。
-
在“ 工件”字段中,键入“logging-consumer”。
Artifact字段的值成为应用程序名称。如果您为中间件选择了RabbitMQ,那么您的Spring Initializr现在应如下所示:
-
单击“ 生成项目”按钮。
这样做会将生成的项目的压缩版本下载到硬盘驱动器。
-
将文件解压缩到要用作项目目录的文件夹中。
| 我们鼓励您探索Spring Initializr中提供的众多可能性。它允许您创建许多不同类型的Spring应用程序。 |
2.2.将项目导入IDE
现在,您可以将项目导入IDE。请记住,根据IDE,您可能需要遵循特定的导入过程。例如,根据项目的生成方式(Maven或Gradle),您可能需要遵循特定的导入过程(例如,在Eclipse或STS中,您需要使用File→Import→Maven→Existing Maven Project)。
导入后,项目必须没有任何错误。此外,src/main/java应包含com.example.loggingconsumer.LoggingConsumerApplication。
从技术上讲,此时,您可以运行应用程序的主类。它已经是一个有效的Spring Boot应用程序。但是,它没有做任何事情,所以我们想添加一些代码。
2.3.添加消息处理程序,构建和运行
将com.example.loggingconsumer.LoggingConsumerApplication类修改为如下所示:
@SpringBootApplication
@EnableBinding(Sink.class)
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@StreamListener(Sink.INPUT)
public void handle(Person person) {
System.out.println("Received: " + person);
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}从前面的清单中可以看出:
-
我们使用
@EnableBinding(Sink.class)启用了Sink绑定(输入 - 无输出)。这样做会向框架发出信号,以启动与消息传递中间件的绑定,从而自动创建绑定到Sink.INPUT通道的目标(即队列,主题和其他)。 -
我们添加了一个
handler方法来接收Person类型的传入消息。这样做可以让您看到框架的核心功能之一:它尝试自动将传入的消息有效负载转换为Person类型。
您现在拥有一个功能齐全的Spring Cloud Stream应用程序,可以侦听消息。从这里开始,为简单起见,我们假设您在第一步中选择了RabbitMQ 。假设您已安装并运行RabbitMQ,则可以通过在IDE中运行其main方法来启动应用程序。
你应该看到以下输出:
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)转到RabbitMQ管理控制台或任何其他RabbitMQ客户端,并向input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg发送消息。anonymous.CbMIwdkJSBO1ZoPDOtHtCg部分代表组名并且已生成,因此它在您的环境中必然会有所不同。对于更可预测的内容,您可以通过设置spring.cloud.stream.bindings.input.group=hello(或您喜欢的任何名称)来使用显式组名。
消息的内容应该是Person类的JSON表示,如下所示:
{“name”:“Sam Spade”}
然后,在您的控制台中,您应该看到:
Received: Sam Spade
您还可以将应用程序构建并打包到引导jar中(使用./mvnw clean install)并使用java -jar命令运行构建的JAR。
现在你有一个工作(虽然非常基本的)Spring Cloud Stream应用程序。
3. 2.0中的新功能是什么?
Spring Cloud Stream引入了许多新功能,增强功能和更改。以下部分概述了最值得注意的部分:
3.1.新功能和组件
-
轮询消费者:引入轮询的消费者,让应用程序控制消息处理速率。有关详细信息,请参阅“ 使用轮询的使用者 ”。您还可以阅读此博客文章了解更多详情。
-
千分尺支持:度量标准已切换为使用千分尺。
MeterRegistry也作为bean提供,以便自定义应用程序可以自动装配它以捕获自定义指标。有关详细信息,请参阅“ 度量标准发射器 ”。 -
新的执行器绑定控件:新的执行器绑定控件可让您可视化和控制Bindings生命周期。有关更多详细信息,请参阅绑定可视化和控件。
-
可配置的RetryTemplate:除了提供配置
RetryTemplate的属性之外,我们现在允许您提供自己的模板,有效地覆盖框架提供的模板。要使用它,请在应用程序中将其配置为@Bean。
3.2.值得注意的增强功能
此版本包括以下显着增强功能:
3.2.1.Actuator和Web依赖关系现在都是可选的
如果不需要执行器和web依赖性,则此更改会减少已部署应用程序的占用空间。它还允许您通过手动添加以下依赖项之一在响应和传统web范例之间切换。
以下清单显示了如何添加传统的web框架:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>以下清单显示了如何添加反应式web框架:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>以下列表显示了如何添加执行器依赖项:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>3.2.2.内容类型协商改进
verion 2.0的核心主题之一是围绕内容类型协商和消息转换的改进(在一致性和性能方面)。以下摘要概述了该领域的显着变化和改进。有关详细信息,请参阅“ 内容类型协商 ”部分。另外这个博客帖子中包含更多细节。
-
现在,所有邮件转换仅由
MessageConverter个对象处理。 -
我们引入了
@StreamMessageConverter注释来提供自定义MessageConverter对象。 -
我们将默认值
Content Type引入为application/json,在迁移1.3应用程序或在混合模式下运行时需要考虑这一点(即1.3生产者→2.0使用者)。 -
对于无法确定所提供的
MessageHandler的参数类型的情况,具有文本有效负载和contentTypetext/…或…/json的消息不再转换为Message<String>(即,public void handle(Message<?> message)或public void handle(Object payload))。此外,强大的参数类型可能不足以正确转换消息,因此contentType标题可能被某些MessageConverters用作补充。
3.3.值得注意的弃用
从2.0版开始,不推荐使用以下项目:
3.3.1.Java序列化(Java Native和Kryo)
JavaSerializationMessageConverter和KryoMessageConverter目前仍然存在。但是,我们计划在未来将它们从核心软件包和支持中移除。这种弃用的主要原因是标记基于类型的,特定于语言的序列化可能在分布式环境中引起的问题,其中生产者和消费者可能依赖于不同的JVM版本或具有不同版本的支持库(即Kryo)。我们还想提请注意消费者和生产者甚至可能不是基于Java的事实,因此多语言样式序列化(即JSON)更适合。
3.3.2.不推荐使用的类和方法
以下是显着弃用的快速摘要。有关详细信息,请参阅相应的{spring-cloud-stream - javadoc-current} [javadoc]。
-
SharedChannelRegistry.使用SharedBindingTargetRegistry。 -
Bindings.由它限定的豆类已经根据其类型进行了唯一标识 - 例如,提供Source,Processor或自定义绑定:
public interface Sample {
String OUTPUT =“sampleOutput”;
@Output(Sample.OUTPUT)
MessageChannel输出();
}
-
HeaderMode.raw.使用none,headers或embeddedHeaders -
ProducerProperties.partitionKeyExtractorClass赞成partitionKeyExtractorName和ProducerProperties.partitionSelectorClass赞成partitionSelectorName。此更改可确保Spring配置和管理这两个组件,并以Spring友好的方式引用。 -
BinderAwareRouterBeanPostProcessor.虽然该组件仍然存在,但它不再是BeanPostProcessor并且将来会重命名。 -
BinderProperties.setEnvironment(Properties environment).使用BinderProperties.setEnvironment(Map<String, Object> environment)。
本节详细介绍了如何使用Spring Cloud Stream。它涵盖了创建和运行流应用程序等主题。
4.介绍Spring Cloud Stream
Spring Cloud Stream是构建消息驱动的微服务应用程序的框架。Spring Cloud Stream基于Spring Boot构建独立的生产级Spring应用程序,并使用Spring Integration提供与消息代理的连接。它提供了来自多个供应商的中间件的固定配置,介绍了持久性发布 - 订阅语义,使用者组和分区的概念。
您可以将@EnableBinding注释添加到应用程序以立即连接到消息代理,并且可以将@StreamListener添加到方法以使其接收用于流处理的事件。以下示例显示了接收外部消息的接收器应用程序:
@SpringBootApplication
@EnableBinding(Sink.class)
public class VoteRecordingSinkApplication {
public static void main(String[] args) {
SpringApplication.run(VoteRecordingSinkApplication.class, args);
}
@StreamListener(Sink.INPUT)
public void processVote(Vote vote) {
votingService.recordVote(vote);
}
}@EnableBinding注释将一个或多个接口作为参数(在本例中,参数是单个Sink接口)。接口声明输入和输出通道。Spring Cloud Stream提供Source,Sink和Processor接口。您还可以定义自己的界面。
以下清单显示了Sink接口的定义:
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}@Input注释标识输入通道,接收的消息通过该通道进入应用程序。@Output注释标识输出通道,已发布的消息通过该通道离开应用程序。@Input和@Output注释可以将通道名称作为参数。如果未提供名称,则使用带注释的方法的名称。
Spring Cloud Stream为您创建了一个接口实现。您可以通过自动装配在应用程序中使用它,如以下示例所示(来自测试用例):
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = VoteRecordingSinkApplication.class)
@WebAppConfiguration
@DirtiesContext
public class StreamApplicationTests {
@Autowired
private Sink sink;
@Test
public void contextLoads() {
assertNotNull(this.sink.input());
}
}附录
附录A:构建
A.1.基本编译和测试
要构建源代码,您需要安装JDK 1.7。
构建使用Maven包装器,因此您不必安装特定版本的Maven。要为Redis,Rabbit和Kafka绑定启用测试,您应该在构建之前运行这些服务器。有关运行服务器的更多信息,请参见下文。
主构建命令是
$ ./mvnw clean install
如果愿意,您还可以添加'-DskipTests',以避免运行测试。
您也可以自己安装Maven(> = 3.3.3)并在下面的示例中运行mvn命令代替./mvnw。如果您这样做,如果您的本地Maven设置不包含spring pre-release工件的存储库声明,您可能还需要添加-P spring。
|
请注意,您可能需要通过将MAVEN_OPTS环境变量设置为-Xmx512m -XX:MaxPermSize=128m来增加Maven可用的内存量。我们尝试在.mvn配置中介绍此内容,因此如果您发现必须执行此操作才能使构建成功,请提高票证以将设置添加到源代码管理中。
|
需要中间件的项目通常包含docker-compose.yml,因此请考虑使用
Docker Compose在Docker容器中运行middeware服务器。有关mongo,rabbit和redis常见情况的具体说明,请参阅脚本演示存储库中的README
。
A.2.文档
有一个“完整”的配置文件将生成文档。
A.3.使用代码
如果您没有IDE首选项,我们建议您在使用代码时使用 Spring Tools Suite或 Eclipse。我们使用 m2eclipe eclipse插件来支持maven。其他IDE和工具也应该没有问题。
A.3.1.使用m2eclipse导入eclipse
在使用eclipse时,我们建议使用m2eclipe eclipse插件。如果您还没有安装m2eclipse,可以从“eclipse marketplace”获得。
不幸的是m2e还不支持Maven 3.3,所以一旦将项目导入Eclipse,你还需要告诉m2eclipse使用.settings.xml文件进行项目。如果不这样做,您可能会看到许多与项目中的POM相关的错误。打开Eclipse首选项,展开Maven首选项,然后选择用户设置。在“用户设置”字段中,单击“浏览”并导航到导入的Spring Cloud项目,选择该项目中的.settings.xml文件。单击应用,然后单击确定以保存首选项更改。
或者,您可以将存储库设置复制.settings.xml到您自己的~/.m2/settings.xml中。
|
A.3.2.没有m2eclipse导入eclipse
如果您不想使用m2eclipse,可以使用以下命令生成eclipse项目元数据:
$ ./mvnw eclipse:eclipse
通过从file菜单中选择import existing projects,可以导入生成的eclipse项目。[[贡献] ==贡献
Spring Cloud是在非限制性Apache 2.0许可下发布的,遵循非常标准的Github开发过程,使用Github跟踪器解决问题并将拉取请求合并到master中。如果您想贡献一些微不足道的东西,请不要犹豫,但请遵循以下指南。
A.4.签署贡献者许可协议
在我们接受非平凡的补丁或拉取请求之前,我们需要您签署 贡献者的协议。签署贡献者的协议不会授予任何人对主存储库的提交权利,但它确实意味着我们可以接受您的贡献,如果我们这样做,您将获得作者信用。可能会要求活跃的贡献者加入核心团队,并且能够合并拉取请求。
A.5.代码约定和内务管理
这些都不是拉取请求所必需的,但它们都会有所帮助。它们也可以在原始拉取请求之后但在合并之前添加。
-
使用Spring Framework代码格式约定。如果您使用Eclipse,则可以使用Spring Cloud Build项目中的
eclipse-code-formatter.xml文件导入格式化程序设置 。如果使用IntelliJ,则可以使用 Eclipse Code Formatter Plugin导入同一文件。 -
确保所有新的
.java文件都有一个简单的Javadoc类注释,至少有一个@author标记标识您,最好至少有一个关于该类所用内容的段落。 -
将ASF许可证头注释添加到所有新的
.java文件(从项目中的现有文件复制) -
将自己添加为
@author到您实际修改的.java文件(超过整容更改)。 -
添加一些Javadoc,如果更改命名空间,则添加一些XSD doc元素。
-
一些单元测试也会有很多帮助 - 有人必须这样做。
-
如果没有其他人使用您的分支,请将其重新绑定到当前主服务器(或主项目中的其他目标分支)。
-
在编写提交消息时,请遵循这些约定,如果要解决现有问题,请在提交消息末尾添加
Fixes gh-XXXX(其中XXXX是问题编号)。